Summarise clinical tables records
Source:vignettes/A-summarise_clinical_tables_records.Rmd
A-summarise_clinical_tables_records.RmdIntroduction
In this vignette, we will explore the OmopSketch functions designed to provide an overview of the clinical tables within a CDM object (observation_period, visit_occurrence, condition_occurrence, drug_exposure, procedure_occurrence, device_exposure, measurement, observation, and death). Specifically, there are four key functions that facilitate this:
summariseClinicalRecords()andtableClinicalRecords(): Use them to create a summary statistics with key basic information of the clinical table (e.g., number of records, number of concepts mapped, etc.)summariseRecordCount()andplotRecordCount(): Use them to summarise the number of records within a specific time interval.
Create a mock cdm
Let’s see an example of its functionalities. To start with, we will load essential packages and create a mock cdm using the mockOmopSketch() database.
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(OmopSketch)
# Connect to mock database
cdm <- mockOmopSketch()
#> Note: method with signature 'DBIConnection#Id' chosen for function 'dbExistsTable',
#> target signature 'duckdb_connection#Id'.
#> "duckdb_connection#ANY" would also be validSummarise clinical tables
Let’s now use summariseClinicalTables()from the
OmopSketch package to help us have an overview of one of the clinical
tables of the cdm (i.e., condition_occurrence).
summarisedResult <- summariseClinicalRecords(cdm, "condition_occurrence")
#> ℹ Adding variables of interest to condition_occurrence.
#> ℹ Summarising records per person in condition_occurrence.
#> ℹ Summarising condition_occurrence: `in_observation`, `standard_concept`,
#> `source_vocabulary`, `domain_id`, and `type_concept`.
summarisedResult |> print()
#> # A tibble: 18 × 13
#> result_id cdm_name group_name group_level strata_name strata_level
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 mockOmopSketch omop_table condition_occur… overall overall
#> 2 1 mockOmopSketch omop_table condition_occur… overall overall
#> 3 1 mockOmopSketch omop_table condition_occur… overall overall
#> 4 1 mockOmopSketch omop_table condition_occur… overall overall
#> 5 1 mockOmopSketch omop_table condition_occur… overall overall
#> 6 1 mockOmopSketch omop_table condition_occur… overall overall
#> 7 1 mockOmopSketch omop_table condition_occur… overall overall
#> 8 1 mockOmopSketch omop_table condition_occur… overall overall
#> 9 1 mockOmopSketch omop_table condition_occur… overall overall
#> 10 1 mockOmopSketch omop_table condition_occur… overall overall
#> 11 1 mockOmopSketch omop_table condition_occur… overall overall
#> 12 1 mockOmopSketch omop_table condition_occur… overall overall
#> 13 1 mockOmopSketch omop_table condition_occur… overall overall
#> 14 1 mockOmopSketch omop_table condition_occur… overall overall
#> 15 1 mockOmopSketch omop_table condition_occur… overall overall
#> 16 1 mockOmopSketch omop_table condition_occur… overall overall
#> 17 1 mockOmopSketch omop_table condition_occur… overall overall
#> 18 1 mockOmopSketch omop_table condition_occur… overall overall
#> # ℹ 7 more variables: variable_name <chr>, variable_level <chr>,
#> # estimate_name <chr>, estimate_type <chr>, estimate_value <chr>,
#> # additional_name <chr>, additional_level <chr>Notice that the output is in the summarised result format.
We can use the arguments to specify which statistics we want to
perform. For example, use the argument recordsPerPerson to
indicate which estimates you are interested regarding the number of
records per person.
summarisedResult <- summariseClinicalRecords(cdm,
"condition_occurrence",
recordsPerPerson = c("mean", "sd", "q05", "q95"))
#> ℹ Adding variables of interest to condition_occurrence.
#> ℹ Summarising records per person in condition_occurrence.
#> ℹ Summarising condition_occurrence: `in_observation`, `standard_concept`,
#> `source_vocabulary`, `domain_id`, and `type_concept`.
summarisedResult |>
filter(variable_name == "records_per_person") |>
select(variable_name, estimate_name, estimate_value)
#> # A tibble: 4 × 3
#> variable_name estimate_name estimate_value
#> <chr> <chr> <chr>
#> 1 records_per_person mean 6
#> 2 records_per_person q05 3
#> 3 records_per_person q95 10
#> 4 records_per_person sd 2.3225You can further specify if you want to include the number of records
in observation (inObservation = TRUE), the number of
concepts mapped (standardConcept = TRUE), which types of
source vocabulary does the table contain
(sourceVocabulary = TRUE), which types of domain does the
vocabulary have (domainId = TRUE) or the concept’s type
(typeConcept = TRUE).
summarisedResult <- summariseClinicalRecords(cdm,
"condition_occurrence",
recordsPerPerson = c("mean", "sd", "q05", "q95"),
inObservation = TRUE,
standardConcept = TRUE,
sourceVocabulary = TRUE,
domainId = TRUE,
typeConcept = TRUE)
#> ℹ Adding variables of interest to condition_occurrence.
#> ℹ Summarising records per person in condition_occurrence.
#> ℹ Summarising condition_occurrence: `in_observation`, `standard_concept`,
#> `source_vocabulary`, `domain_id`, and `type_concept`.
summarisedResult |>
select(variable_name, estimate_name, estimate_value) |>
glimpse()
#> Rows: 15
#> Columns: 3
#> $ variable_name <chr> "Number subjects", "Number subjects", "Number records",…
#> $ estimate_name <chr> "count", "percentage", "count", "mean", "q05", "q95", "…
#> $ estimate_value <chr> "100", "100", "600", "6", "3", "10", "2.3225", "600", "…Additionally, you can also stratify the previous results by sex and age groups:
summarisedResult <- summariseClinicalRecords(cdm,
"condition_occurrence",
recordsPerPerson = c("mean", "sd", "q05", "q95"),
inObservation = TRUE,
standardConcept = TRUE,
sourceVocabulary = TRUE,
domainId = TRUE,
typeConcept = TRUE,
sex = TRUE,
ageGroup = list("<35" = c(0, 34), ">=35" = c(35, Inf)))
#> ℹ Adding variables of interest to condition_occurrence.
#> ℹ Summarising records per person in condition_occurrence.
#> ℹ Summarising condition_occurrence: `in_observation`, `standard_concept`,
#> `source_vocabulary`, `domain_id`, and `type_concept`.
summarisedResult |>
select(variable_name, strata_level, estimate_name, estimate_value) |>
glimpse()
#> Rows: 135
#> Columns: 4
#> $ variable_name <chr> "Number subjects", "Number subjects", "Number records",…
#> $ strata_level <chr> "overall", "overall", "overall", "overall", "overall", …
#> $ estimate_name <chr> "count", "percentage", "count", "mean", "q05", "q95", "…
#> $ estimate_value <chr> "100", "100", "600", "6", "2.9500", "10", "2.3225", "60…Notice that, by default, the “overall” group will be also included, as well as crossed strata (that means, sex == “Female” and ageGroup == “>35”).
Also, see that the analysis can be conducted for multiple OMOP tables at the same time:
summarisedResult <- summariseClinicalRecords(cdm,
c("observation_period","drug_exposure"),
recordsPerPerson = c("mean","sd"),
inObservation = FALSE,
standardConcept = FALSE,
sourceVocabulary = FALSE,
domainId = FALSE,
typeConcept = FALSE)
#> ℹ Adding variables of interest to observation_period.
#> ℹ Summarising records per person in observation_period.
#> ℹ Adding variables of interest to drug_exposure.
#> ℹ Summarising records per person in drug_exposure.
summarisedResult |>
select(group_level, variable_name, estimate_name, estimate_value) |>
glimpse()
#> Rows: 10
#> Columns: 4
#> $ group_level <chr> "observation_period", "observation_period", "observatio…
#> $ variable_name <chr> "Number subjects", "Number subjects", "Number records",…
#> $ estimate_name <chr> "count", "percentage", "count", "mean", "sd", "count", …
#> $ estimate_value <chr> "100", "100", "100", "1", "0", "100", "100", "3100", "3…Tidy the summarised object
tableClinicalRecords() will help you to tidy the
previous results and create a gt table.
summarisedResult <- summariseClinicalRecords(cdm,
"condition_occurrence",
recordsPerPerson = c("mean", "sd", "q05", "q95"),
inObservation = TRUE,
standardConcept = TRUE,
sourceVocabulary = TRUE,
domainId = TRUE,
typeConcept = TRUE,
sex = TRUE)
#> ℹ Adding variables of interest to condition_occurrence.
#> ℹ Summarising records per person in condition_occurrence.
#> ℹ Summarising condition_occurrence: `in_observation`, `standard_concept`,
#> `source_vocabulary`, `domain_id`, and `type_concept`.
summarisedResult |>
tableClinicalRecords()| Variable name | Variable level | Estimate name |
Database name
|
|---|---|---|---|
| mockOmopSketch | |||
| condition_occurrence; overall | |||
| Number subjects | - | N (%) | 100 (100.00%) |
| Number records | - | N | 600.00 |
| Records per person | - | Mean (SD) | 6.00 (2.32) |
| q05 | 2.95 | ||
| q95 | 10.00 | ||
| In observation | Yes | N (%) | 600 (100.00%) |
| Standard concept | S | N (%) | 600 (100.00%) |
| Source vocabulary | No matching concept | N (%) | 600 (100.00%) |
| Type concept id | Unknown type concept: 1 | N (%) | 600 (100.00%) |
| condition_occurrence; Female | |||
| Number subjects | - | N (%) | 57 (100.00%) |
| Number records | - | N | 327.00 |
| Records per person | - | Mean (SD) | 5.74 (2.34) |
| q05 | 2.00 | ||
| q95 | 10.00 | ||
| In observation | Yes | N (%) | 327 (100.00%) |
| Standard concept | S | N (%) | 327 (100.00%) |
| Source vocabulary | No matching concept | N (%) | 327 (100.00%) |
| Type concept id | Unknown type concept: 1 | N (%) | 327 (100.00%) |
| condition_occurrence; Male | |||
| Number subjects | - | N (%) | 43 (100.00%) |
| Number records | - | N | 273.00 |
| Records per person | - | Mean (SD) | 6.35 (2.28) |
| q05 | 3.10 | ||
| q95 | 9.00 | ||
| In observation | Yes | N (%) | 273 (100.00%) |
| Standard concept | S | N (%) | 273 (100.00%) |
| Source vocabulary | No matching concept | N (%) | 273 (100.00%) |
| Type concept id | Unknown type concept: 1 | N (%) | 273 (100.00%) |
Summarise record counts
OmopSketch can also help you to summarise the trend of the records of
an OMOP table. See the example below, where we use
summariseRecordCount() to count the number of records
within each year, and then, we use plotRecordCount() to
create a ggplot with the trend.
summarisedResult <- summariseRecordCount(cdm, "drug_exposure", interval = "years")
summarisedResult |> print()
#> # A tibble: 67 × 13
#> result_id cdm_name group_name group_level strata_name strata_level
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 mockOmopSketch omop_table drug_exposure overall overall
#> 2 1 mockOmopSketch omop_table drug_exposure overall overall
#> 3 1 mockOmopSketch omop_table drug_exposure overall overall
#> 4 1 mockOmopSketch omop_table drug_exposure overall overall
#> 5 1 mockOmopSketch omop_table drug_exposure overall overall
#> 6 1 mockOmopSketch omop_table drug_exposure overall overall
#> 7 1 mockOmopSketch omop_table drug_exposure overall overall
#> 8 1 mockOmopSketch omop_table drug_exposure overall overall
#> 9 1 mockOmopSketch omop_table drug_exposure overall overall
#> 10 1 mockOmopSketch omop_table drug_exposure overall overall
#> # ℹ 57 more rows
#> # ℹ 7 more variables: variable_name <chr>, variable_level <chr>,
#> # estimate_name <chr>, estimate_type <chr>, estimate_value <chr>,
#> # additional_name <chr>, additional_level <chr>
summarisedResult |> plotRecordCount()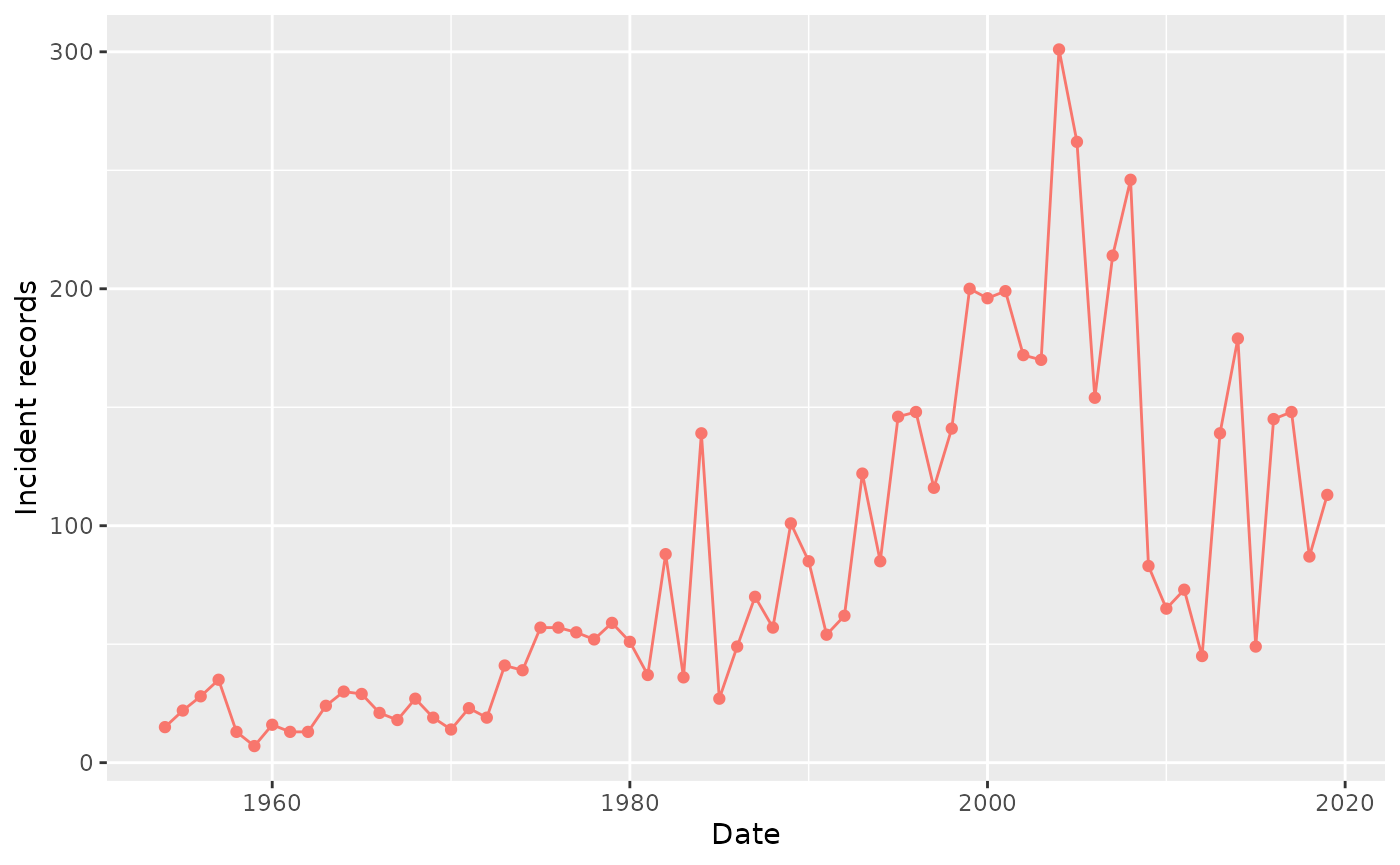
Note that you can adjust the time interval period using the
interval argument, which can be set to either “years” or
“months”. See the example below, where it shows the number of records
every 18 months:
summariseRecordCount(cdm, "drug_exposure", interval = "months") |>
plotRecordCount()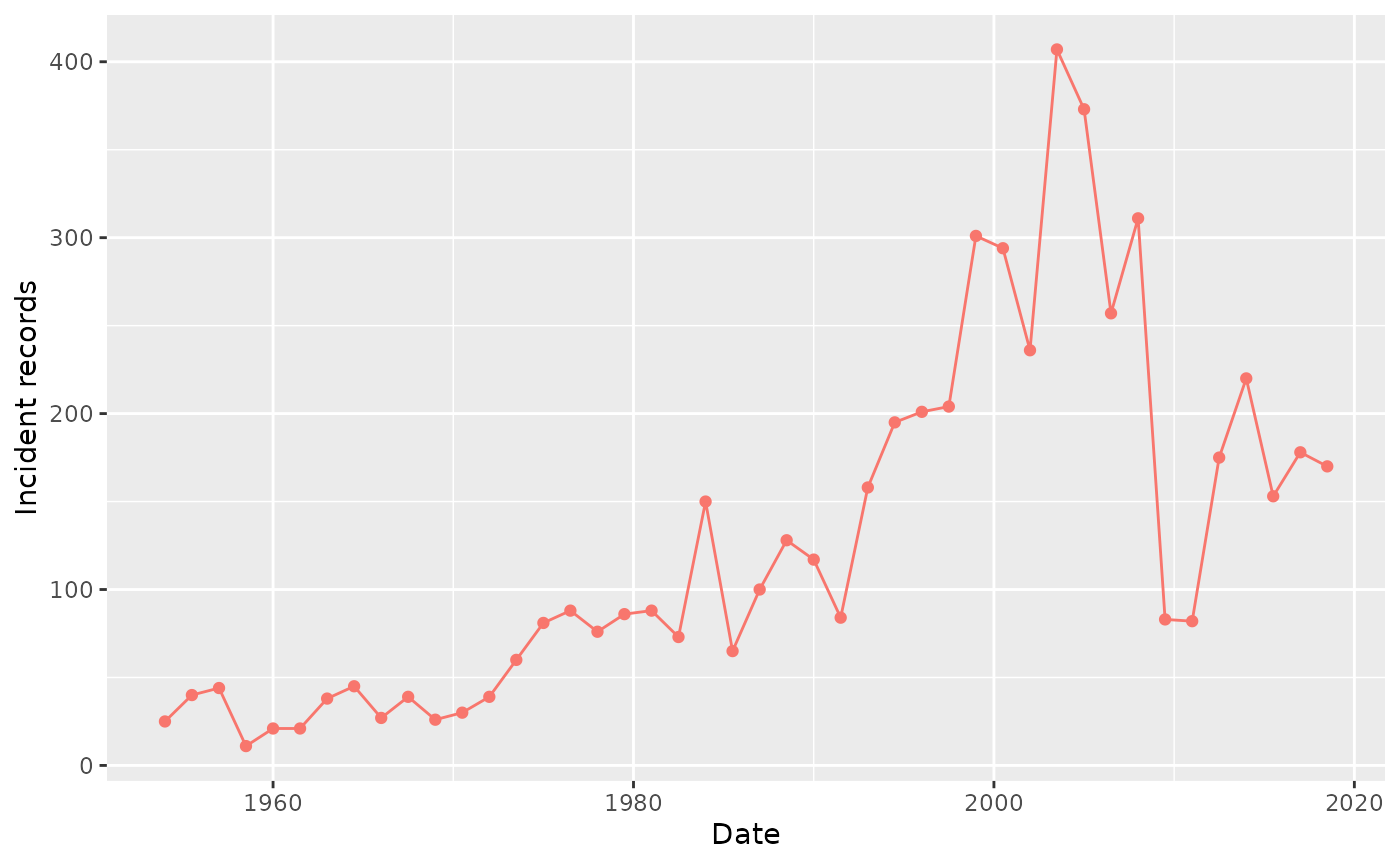
We can further stratify our counts by sex (setting argument
sex = TRUE) or by age (providing an age group). Notice that
in both cases, the function will automatically create a group called
overall with all the sex groups and all the age groups.
summariseRecordCount(cdm, "drug_exposure",
interval = "months",
sex = TRUE,
ageGroup = list("<30" = c(0,29),
">=30" = c(30,Inf))) |>
plotRecordCount()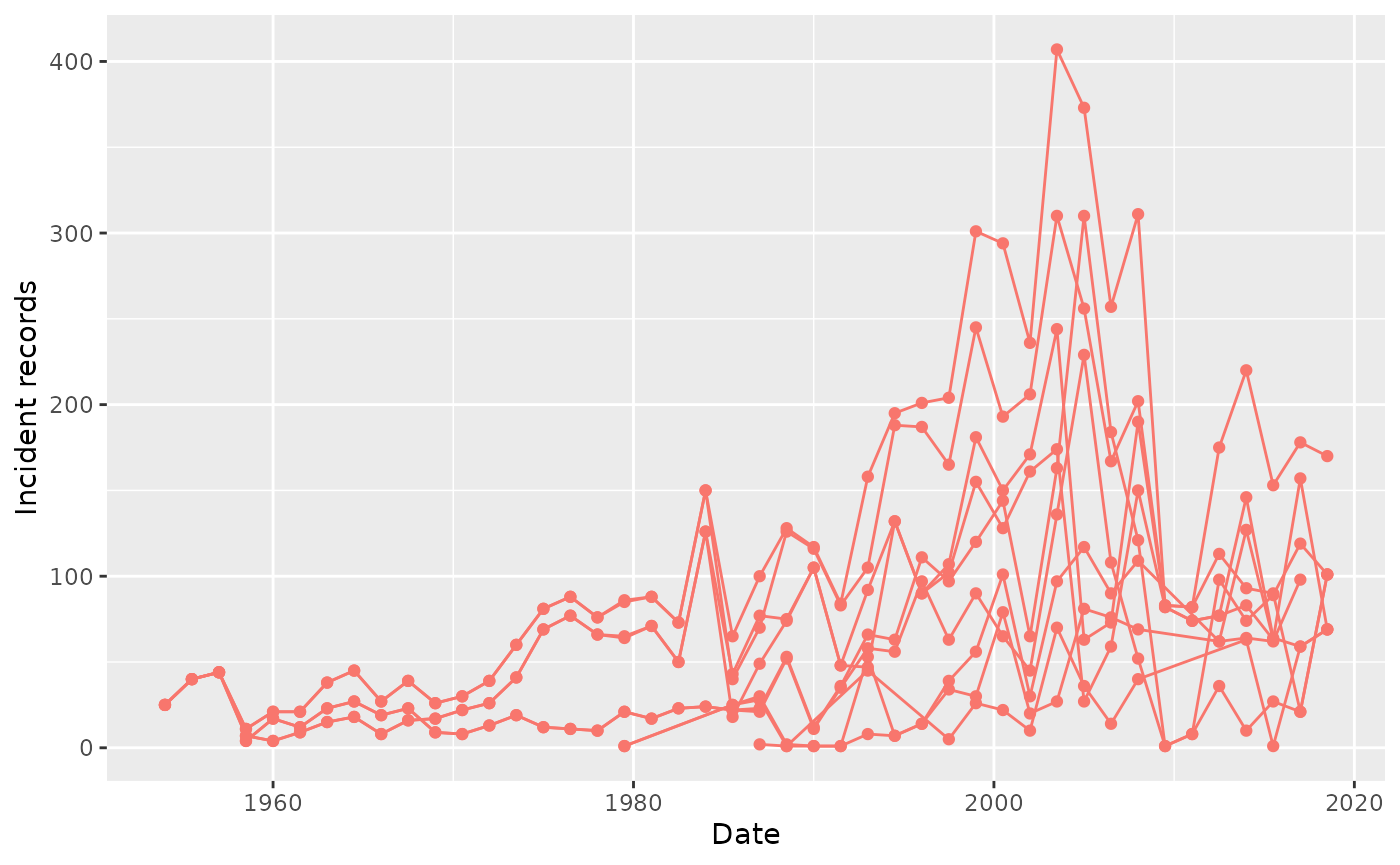
By default, plotRecordCount() does not apply faceting or
colour to any variables. This can result confusing when stratifying by
different variables, as seen in the previous picture. We can use VisOmopResults
package to help us know by which columns we can colour or face by:
summariseRecordCount(cdm, "drug_exposure",
interval = "months",
sex = TRUE,
ageGroup = list("0-29" = c(0,29),
"30-Inf" = c(30,Inf))) |>
visOmopResults::tidyColumns()
#> [1] "cdm_name" "omop_table" "age_group" "sex"
#> [5] "variable_name" "variable_level" "count" "time_interval"
#> [9] "interval"Then, we can simply specify this by using the facet and
colour arguments from plotRecordCount()
summariseRecordCount(cdm, "drug_exposure",
interval = "months",
sex = TRUE,
ageGroup = list("0-29" = c(0,29),
"30-Inf" = c(30,Inf))) |>
plotRecordCount(facet = omop_table ~ age_group, colour = "sex")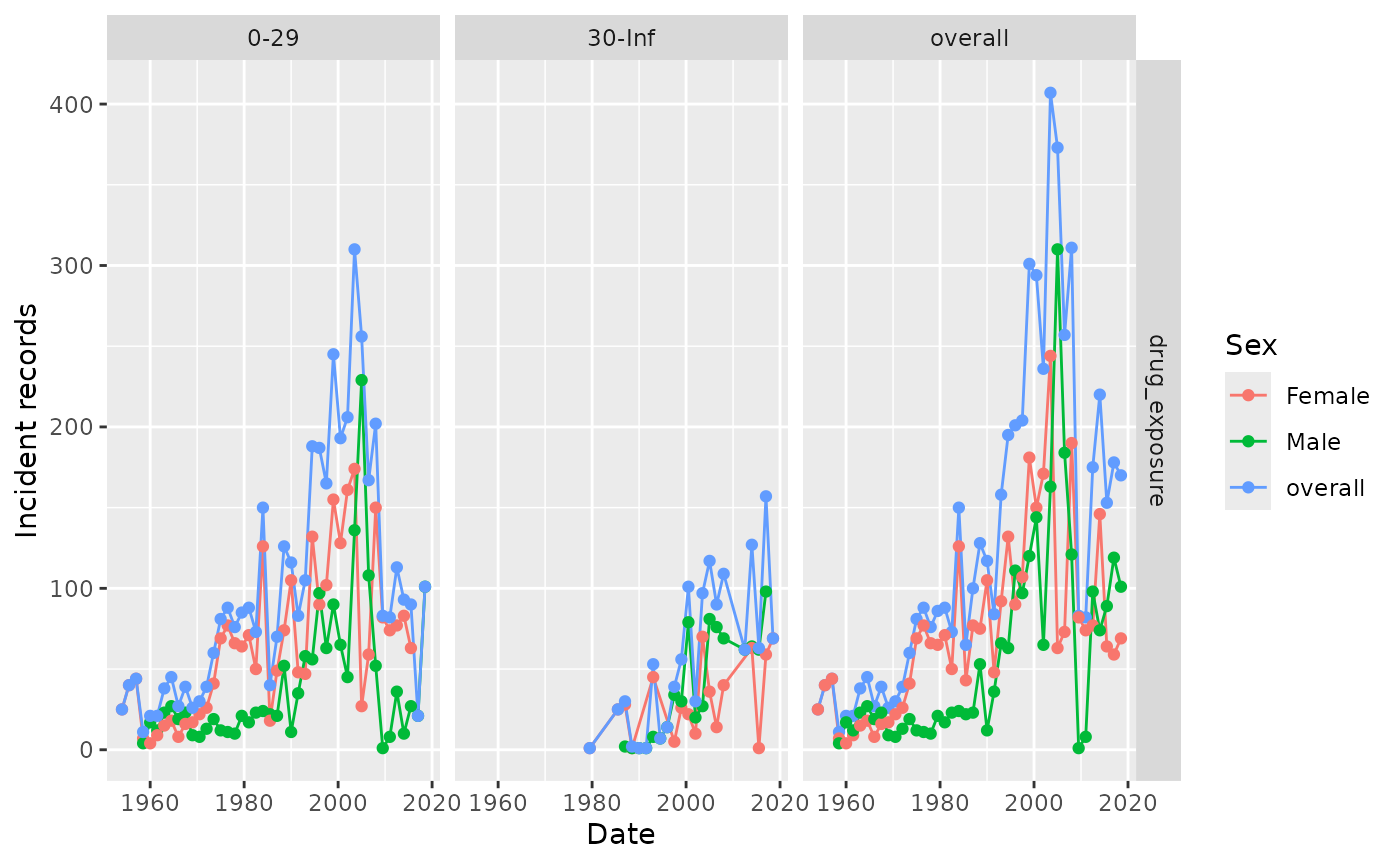
Finally, disconnect from the cdm
PatientProfiles::mockDisconnect(cdm = cdm)