Introduction
Cohorts are a fundamental building block for studies that use the OMOP CDM, identifying people who satisfy one or more inclusion criteria for a duration of time based on their clinical records. Currently cohorts are typically built using CIRCE which allows complex cohorts to be represented using JSON. This JSON is then converted to SQL for execution against a database containing data mapped to the OMOP CDM. CIRCE JSON can be created via the ATLAS GUI or programmatically via the Capr R package. However, although a powerful tool for expressing and operationalising cohort definitions, the SQL generated can be cumbersome especially for complex cohort definitions, moreover cohorts are instantiated independently, leading to duplicated work.
The CohortConstructor package offers an alternative approach, emphasising cohort building in a pipeline format. It first creates base cohorts and then applies specific inclusion criteria. Unlike the “by definition” approach, where cohorts are built independently, CohortConstructor follows a “by domain/ table” approach, which minimises redundant queries to large OMOP tables. More details on this approach can be found in the Introduction vignette.
To test the performance of the package there is a benchmarking function which uses nine phenotypes from the OHDSI Phenotype library that cover a range of concept domains, entry and inclusion criteria, and cohort exit options. We replicated these cohorts using CohortConstructor to assess computational time and agreement between CIRCE and CohortConstructor.
cdm <- mockCdmFromDataset(datasetName = "GiBleed", source = "duckdb")Once we have created our cdm reference we can run the benchmark. Once run we’ll have a set of results with the time taken to run the different tasks. For this example we will just run task of creating all the cohorts at once using CohortConstructor.
benchmark_results <- benchmarkCohortConstructor(
cdm,
runCIRCE = FALSE,
runCohortConstructorDefinition = FALSE,
runCohortConstructorDomain = TRUE
)
#> cc_set_no_strata: 96.99 sec elapsed
#> cc_set_strata: 1.399 sec elapsed
benchmark_results |>
glimpse()
#> Rows: 257
#> Columns: 13
#> $ result_id <int> 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9,…
#> $ cdm_name <chr> "GiBleed", "GiBleed", "GiBleed", "GiBleed", "GiBleed"…
#> $ group_name <chr> "cohort_name", "cohort_name", "cohort_name", "cohort_…
#> $ group_level <chr> "cc_asthma_no_copd", "cc_asthma_no_copd", "cc_beta_bl…
#> $ strata_name <chr> "overall", "overall", "overall", "overall", "overall"…
#> $ strata_level <chr> "overall", "overall", "overall", "overall", "overall"…
#> $ variable_name <chr> "number_records", "number_subjects", "number_records"…
#> $ variable_level <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ estimate_name <chr> "count", "count", "count", "count", "count", "count",…
#> $ estimate_type <chr> "integer", "integer", "integer", "integer", "integer"…
#> $ estimate_value <chr> "101", "101", "0", "0", "0", "0", "0", "0", "1037", "…
#> $ additional_name <chr> "overall", "overall", "overall", "overall", "overall"…
#> $ additional_level <chr> "overall", "overall", "overall", "overall", "overall"…Collaboration
If you are interested in running the code on your database, feel free to reach out to us for assistance, and we can also update the vignette with your results! :)
The benchmark script was executed against the following databases:
CPRD Gold: A primary care database from the UK, capturing data mostly from Northern Ireland, Wales, and Scotland clinics. The benchmark utilized a 100,000-person sample from this dataset, which is managed using PostgreSQL.
CPRD Aurum: Another UK primary care database, primarily covering clinics in England. This database is managed on SQL Server.
Coriva: A sample of approximately 400,000 patients from the Estonia National Health Insurance database, managed on PostgreSQL.
OHDSI SQL Server: A mock OMOP CDM dataset provided by OHDSI, hosted on SQL Server.
The table below presents the number of records in the OMOP tables used in the benchmark script for each of the participating databases.
| OMOP table |
Database
|
||||||
|---|---|---|---|---|---|---|---|
| CPRD Aurum | CORIVA-Estonia | CPRD Gold 100k | OHDSI Postgres server | OHDSI redshift | OHDSI snowflake | OHDSI SQL server | |
| person | 47,193,158 | 438,433 | 100,000 | 1,000 | 1,000 | 116,352 | 1,000 |
| observation_period | 47,193,158 | 438,433 | 100,000 | 1,048 | 1,000 | 104,891 | 1,048 |
| drug_exposure | 3,256,609,138 | 31,265,445 | 12,403,195 | 49,542 | 57,095 | 6,303,388 | 49,542 |
| condition_occurrence | 2,110,992,846 | 40,957,155 | 3,191,739 | 160,322 | 147,186 | 14,455,993 | 160,322 |
| procedure_occurrence | 2,267,113,392 | 14,545,615 | 1,914,271 | 62,189 | 137,522 | 13,926,771 | 62,189 |
| visit_occurrence | 7,091,248,835 | 38,037,330 | 9,183,206 | 47,457 | 55,261 | 5,579,542 | 47,457 |
| measurement | 8,255,241,316 | 39,378,570 | 10,913,588 | 2,858 | 34,556 | 3,704,839 | 2,858 |
| observation | 16,425,069,199 | 37,010,044 | 11,107,039 | 13,481 | 19,339 | 1,876,834 | 13,481 |
Cohorts
We replicated the following cohorts from the OHDSI phenotype library: COVID-19 (ID 56), inpatient hospitalisation (23), new users of beta blockers nested in essential hypertension (1049), transverse myelitis (63), major non cardiac surgery (1289), asthma without COPD (27), endometriosis procedure (722), new fluoroquinolone users (1043), acquired neutropenia or unspecified leukopenia (213).
The COVID-19 cohort was used to evaluate the performance of common cohort stratifications. To compare the package with CIRCE, we created definitions in Atlas, stratified by age groups and sex, which are available in the benchmark GitHub repository with the benchmark code.
Cohort counts and overlap
The following table displays the number of records and subjects for each cohort across the participating databases:
|
Tool
|
||||
|---|---|---|---|---|
| Cohort name |
CIRCE
|
CohortConstructor
|
||
| Number records | Number subjects | Number records | Number subjects | |
| CPRD Aurum | ||||
| Acquired neutropenia or unspecified leukopenia | 1,429,966 | 632,966 | 1,302,498 | 633,030 |
| Asthma without COPD | 4,009,925 | 4,009,925 | 3,934,106 | 3,934,106 |
| COVID-19 | 5,600,429 | 4,452,410 | 6,206,907 | 4,452,196 |
| COVID-19: female | 3,111,643 | 2,434,062 | 3,452,138 | 2,438,759 |
| COVID-19: female, 0 to 50 | 2,172,113 | 1,730,180 | 2,382,039 | 1,730,116 |
| COVID-19: female, 51 to 150 | 939,818 | 708,838 | 1,070,099 | 708,643 |
| COVID-19: male | 2,488,786 | 2,018,348 | 2,754,769 | 2,020,625 |
| COVID-19: male, 0 to 50 | 1,709,375 | 1,422,999 | 1,862,219 | 1,422,962 |
| COVID-19: male, 51 to 150 | 779,629 | 597,804 | 892,550 | 597,663 |
| Endometriosis procedure | 139 | 108 | 77 | 77 |
| Inpatient hospitalisation | 0 | 0 | 0 | 0 |
| Major non cardiac surgery | 1,932,745 | 1,932,745 | 1,932,745 | 1,932,745 |
| New fluoroquinolone users | 1,765,274 | 1,765,274 | 1,817,439 | 1,817,439 |
| New users of beta blockers nested in essential hypertension | 98,592 | 98,592 | 102,589 | 102,589 |
| Transverse myelitis | 11,930 | 4,040 | 5,818 | 4,119 |
| CORIVA-Estonia | ||||
| Acquired neutropenia or unspecified leukopenia | 2,231 | 634 | 2,188 | 634 |
| Asthma without COPD | 25,867 | 25,867 | 25,867 | 25,867 |
| COVID-19 | 421,053 | 193,435 | 435,059 | 193,435 |
| COVID-19: female | 235,740 | 105,849 | 243,773 | 106,322 |
| COVID-19: female, 0 to 50 | 150,121 | 69,168 | 155,256 | 69,168 |
| COVID-19: female, 51 to 150 | 85,620 | 37,154 | 88,517 | 37,154 |
| COVID-19: male | 185,313 | 87,586 | 191,286 | 87,891 |
| COVID-19: male, 0 to 50 | 130,252 | 63,558 | 134,415 | 63,558 |
| COVID-19: male, 51 to 150 | 55,062 | 24,333 | 56,871 | 24,333 |
| Endometriosis procedure | 0 | 0 | 0 | 0 |
| Inpatient hospitalisation | 267,010 | 133,705 | 267,010 | 133,705 |
| Major non cardiac surgery | 4,025 | 4,025 | 4,025 | 4,025 |
| New fluoroquinolone users | 39,712 | 39,712 | 39,712 | 39,712 |
| New users of beta blockers nested in essential hypertension | 18,967 | 18,967 | 18,967 | 18,967 |
| Transverse myelitis | 27 | 10 | 12 | 10 |
| CPRD Gold 100k | ||||
| Acquired neutropenia or unspecified leukopenia | 2,719 | 1,167 | 2,675 | 1,167 |
| Asthma without COPD | 8,808 | 8,808 | 8,741 | 8,741 |
| COVID-19 | 3,231 | 2,881 | 3,275 | 2,881 |
| COVID-19: female | 1,748 | 1,543 | 1,771 | 1,543 |
| COVID-19: female, 0 to 50 | 1,271 | 1,125 | 1,291 | 1,125 |
| COVID-19: female, 51 to 150 | 477 | 418 | 480 | 418 |
| COVID-19: male | 1,483 | 1,338 | 1,504 | 1,341 |
| COVID-19: male, 0 to 50 | 1,054 | 960 | 1,072 | 960 |
| COVID-19: male, 51 to 150 | 429 | 381 | 432 | 381 |
| Endometriosis procedure | 0 | 0 | 0 | 0 |
| Inpatient hospitalisation | 0 | 0 | 0 | 0 |
| Major non cardiac surgery | 4,146 | 4,146 | 4,146 | 4,146 |
| New fluoroquinolone users | 5,412 | 5,412 | 5,412 | 5,412 |
| New users of beta blockers nested in essential hypertension | 1,723 | 1,723 | 1,723 | 1,723 |
| Transverse myelitis | 31 | 11 | 15 | 11 |
| OHDSI Postgres server | ||||
| Acquired neutropenia or unspecified leukopenia | 151 | 86 | 106 | 86 |
| Asthma without COPD | 126 | 126 | 126 | 126 |
| COVID-19 | 0 | 0 | 0 | 0 |
| COVID-19: female | 0 | 0 | 0 | 0 |
| COVID-19: female, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: female, 51 to 150 | 0 | 0 | 0 | 0 |
| COVID-19: male | 0 | 0 | 0 | 0 |
| COVID-19: male, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: male, 51 to 150 | 0 | 0 | 0 | 0 |
| Endometriosis procedure | 0 | 0 | 0 | 0 |
| Inpatient hospitalisation | 522 | 321 | 522 | 321 |
| Major non cardiac surgery | 88 | 88 | 92 | 92 |
| New fluoroquinolone users | 145 | 145 | 145 | 145 |
| New users of beta blockers nested in essential hypertension | 112 | 112 | 112 | 112 |
| Transverse myelitis | 0 | 0 | 0 | 0 |
| OHDSI redshift | ||||
| Acquired neutropenia or unspecified leukopenia | 155 | 88 | 108 | 88 |
| Asthma without COPD | 228 | 228 | 228 | 228 |
| COVID-19 | 0 | 0 | 0 | 0 |
| COVID-19: female | 0 | 0 | 0 | 0 |
| COVID-19: female, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: female, 51 to 150 | 0 | 0 | 0 | 0 |
| COVID-19: male | 0 | 0 | 0 | 0 |
| COVID-19: male, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: male, 51 to 150 | 0 | 0 | 0 | 0 |
| Endometriosis procedure | 0 | 0 | 0 | 0 |
| Inpatient hospitalisation | 612 | 365 | 612 | 365 |
| Major non cardiac surgery | 616 | 616 | 613 | 613 |
| New fluoroquinolone users | 109 | 109 | 109 | 109 |
| New users of beta blockers nested in essential hypertension | 25 | 25 | 25 | 25 |
| Transverse myelitis | – | – | – | – |
| OHDSI snowflake | ||||
| Acquired neutropenia or unspecified leukopenia | 13,960 | 8,525 | 10,147 | 8,525 |
| Asthma without COPD | 24,288 | 24,288 | 24,291 | 24,291 |
| COVID-19 | 0 | 0 | 0 | 0 |
| COVID-19: female | 0 | 0 | 0 | 0 |
| COVID-19: female, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: female, 51 to 150 | 0 | 0 | 0 | 0 |
| COVID-19: male | 0 | 0 | 0 | 0 |
| COVID-19: male, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: male, 51 to 150 | 0 | 0 | 0 | 0 |
| Endometriosis procedure | – | – | 0 | 0 |
| Inpatient hospitalisation | 64,275 | 37,780 | 64,275 | 37,780 |
| Major non cardiac surgery | 66,171 | 66,171 | 66,034 | 66,034 |
| New fluoroquinolone users | 14,203 | 14,203 | 13,398 | 13,398 |
| New users of beta blockers nested in essential hypertension | 2,022 | 2,022 | 2,028 | 2,028 |
| Transverse myelitis | 102 | 43 | 42 | 42 |
| OHDSI SQL server | ||||
| Acquired neutropenia or unspecified leukopenia | 151 | 86 | 106 | 86 |
| Asthma without COPD | 126 | 126 | 126 | 126 |
| COVID-19 | 0 | 0 | 0 | 0 |
| COVID-19: female | 0 | 0 | 0 | 0 |
| COVID-19: female, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: female, 51 to 150 | 0 | 0 | 0 | 0 |
| COVID-19: male | 0 | 0 | 0 | 0 |
| COVID-19: male, 0 to 50 | 0 | 0 | 0 | 0 |
| COVID-19: male, 51 to 150 | 0 | 0 | 0 | 0 |
| Endometriosis procedure | 0 | 0 | 0 | 0 |
| Inpatient hospitalisation | 522 | 321 | 522 | 321 |
| Major non cardiac surgery | 88 | 88 | 92 | 92 |
| New fluoroquinolone users | 145 | 145 | 145 | 145 |
| New users of beta blockers nested in essential hypertension | 112 | 112 | 112 | 112 |
| Transverse myelitis | 0 | 0 | 0 | 0 |
We also computed the overlap between patients in CIRCE and CohortConstructor cohorts, with results shown in the plot below:
Performance
To evaluate CohortConstructor performance we generated each of the CIRCE cohorts using functionalities provided by both CodelistGenerator and CohortConstructor, and measured the computational time taken.
Two different approaches with CohortConstructor were tested:
By definition: we created each of the cohorts seprately.
By domain: All nine targeted cohorts were created together in a set, following the by domain approach described in the Introduction vignette. Briefly, this approach involves creating all base cohorts at once, requiring only one call to each involved OMOP table.
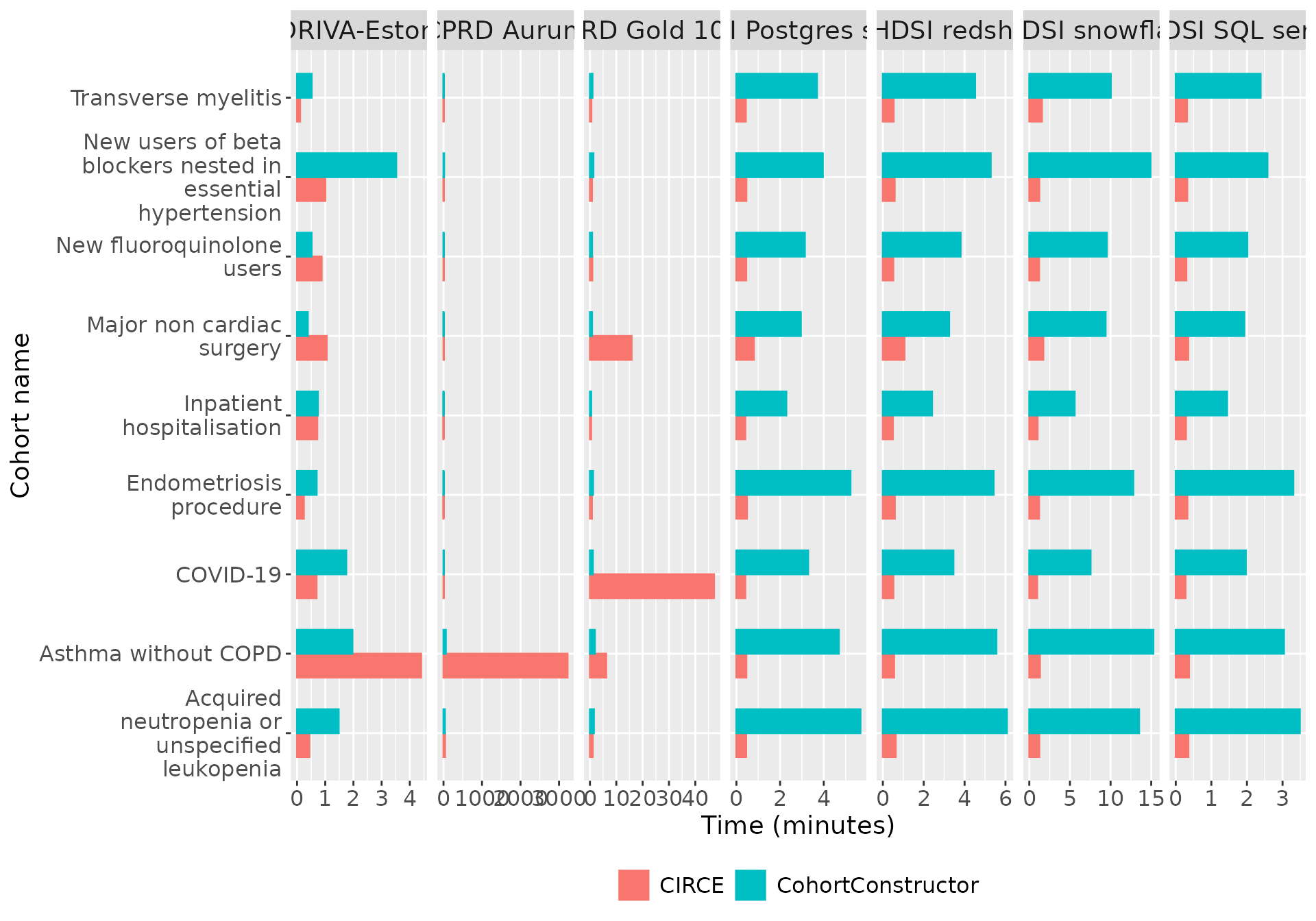
By definition
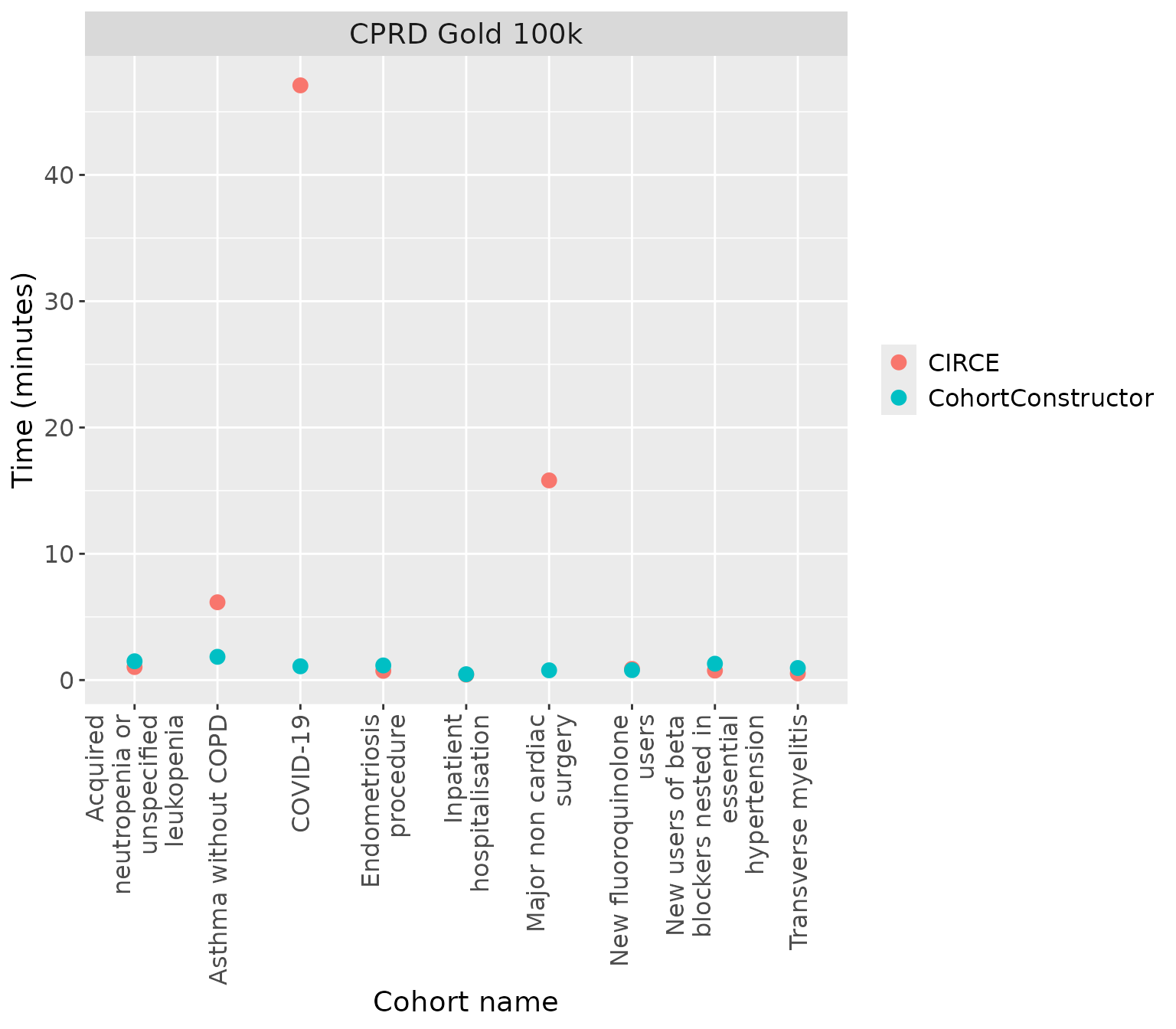
The following plot shows the times taken to create each cohort using CIRCE and CohortConstructor when each cohorts were created separately.
By domain
The table below depicts the total time it took to create the nine cohorts when using the by domain approach for CohortConstructor.
| Database_name |
Time (minutes)
|
|
|---|---|---|
| CIRCE | CohortConstructor | |
| CORIVA-Estonia | 9.51 | 9.95 |
| CPRD Aurum | 3,288.11 | 109.08 |
| CPRD Gold 100k | 73.41 | 7.85 |
| OHDSI Postgres server | 4.32 | 29.20 |
| OHDSI SQL server | 2.89 | 18.56 |
| OHDSI redshift | 5.44 | 34.05 |
| OHDSI snowflake | 11.40 | 84.56 |
Cohort stratification
Cohorts are often stratified in studies. With Atlas cohort definitions, each stratum requires a new CIRCE JSON to be instantiated, while CohortConstructor allows stratifications to be generated from an overall cohort. The following table shows the time taken to create age and sex stratifications for the COVID-19 cohort with both CIRCE and CohortConstructor.
| Database |
Time (minutes)
|
|
|---|---|---|
| CIRCE | CohortConstructor | |
| CORIVA-Estonia | 14.38 | 23.51 |
| CPRD Aurum | 3,300.18 | 241.81 |
| CPRD Gold 100k | 166.66 | 19.52 |
| OHDSI Postgres server | 6.75 | 73.24 |
| OHDSI SQL server | 4.56 | 46.64 |
| OHDSI redshift | 8.32 | 84.79 |
| OHDSI snowflake | 17.04 | 202.95 |