Chapitre 16 Validité Clinique
Responsables du chapitre : Joel Swerdel, Seng Chan You, Ray Chen & Patrick Ryan
La probabilité de transformer la matière en énergie est semblable à tirer sur des oiseaux dans le noir dans un pays où il y a seulement quelques oiseaux. Einstein, 1935
La vision d’OHDSI est “Un monde où la recherche observationnelle produit une compréhension complète de la santé et de la maladie.” Les conceptions rétrospectives offrent un véhicule pour la recherche utilisant des données existantes mais peuvent être jonchées de menaces pour divers aspects de la validité comme discuté dans le Chapitre14. Il n’est pas facile d’isoler la validité clinique de la qualité des données et de la méthodologie statistique, mais ici nous nous concentrerons sur trois aspects en termes de validité clinique : Caractéristiques des bases de données de soins de santé, Validation des cohortes, et Généralisation des preuves. Revenons à l’exemple de l’estimation au niveau de la population (Chapitre 12). Nous avons essayé de répondre à la question “Les inhibiteurs de l’ECA causent-ils plus d’angioedème par rapport aux diurétiques thiazidiques ou thiazidiques apparentés ?” Dans cet exemple, nous avons démontré que les inhibiteurs de l’ECA causaient plus d’angioedème que les diurétiques thiazidiques ou thiazidiques apparentés. Ce chapitre est dédié à répondre à la question : “Dans quelle mesure l’analyse effectuée correspond-elle à l’intention clinique ?”
16.1 Caractéristiques des Bases de Données de Soins de Santé
Il est possible que ce que nous ayons trouvé soit la relation entre la prescription d’un inhibiteur de l’ECA et l’angioedème plutôt que la relation entre l’utilisation d’un inhibiteur de l’ECA et l’angioedème. Nous avons déjà discuté de la qualité des données dans le chapitre précédent (15). La qualité de la base de données convertie en Common Data Model (CDM) ne peut pas dépasser la base de données originale. Ici, nous abordons les caractéristiques de la plupart des bases de données d’utilisation des soins de santé. De nombreuses bases de données utilisées dans OHDSI proviennent de réclamations administratives ou de dossiers médicaux électroniques (DME). Les réclamations et les DME ont des processus de collecte de données différents, dont aucun n’a la recherche comme intention principale. Les éléments de données des dossiers de réclamations sont capturés à des fins de remboursement, de transactions financières entre les cliniciens et les payeurs par lesquelles les services fournis aux patients par les prestataires sont suffisamment justifiés pour permettre un accord sur les paiements par les parties responsables. Les éléments de données des dossiers DME sont capturés pour soutenir les soins cliniques et les opérations administratives, et ils reflètent couramment uniquement les informations que les prestataires au sein d’un système de santé donné jugent nécessaires pour documenter le service actuel et fournir le contexte nécessaire pour les soins de suivi anticipés au sein de leur système de santé. Ils peuvent ne pas représenter l’historique médical complet d’un patient et peuvent ne pas intégrer de données provenant de différents systèmes de santé.
Pour générer des preuves fiables à partir de données observationnelles, il est utile pour un chercheur de comprendre le parcours que subissent les données depuis le moment où un patient cherche des soins jusqu’au moment où les données reflétant ces soins sont utilisées dans une analyse. Par exemple, “l’exposition aux médicaments” peut être inférée à partir de diverses sources de données observationnelles, y compris les prescriptions écrites par les cliniciens, les dossiers de distribution de la pharmacie, les administrations procédurales hospitalières ou les antécédents médicaux autodéclarés par les patients. La source des données peut influencer notre niveau de confiance dans l’inférence que nous tirons sur les patients ayant utilisé ou non le médicament, ainsi que sur le moment et la durée. Le processus de capture des données peut entraîner une sous-estimation de l’exposition, par exemple si les échantillons gratuits ou les médicaments en vente libre ne sont pas enregistrés, ou une surestimation de l’exposition, par exemple si un patient ne remplit pas la prescription donnée ou ne consomme pas régulièrement le médicament distribué. Comprendre les biais potentiels dans la détermination de l’exposition et du résultat, et idéalement quantifier et ajuster ces erreurs de mesure, peut améliorer notre confiance dans la validité des preuves que nous tirons des données disponibles. ## Validation de la cohorte {#CohortValidation}
G. Hripcsak and Albers (2017) décrit qu’“un phénotype est une spécification d’un état observable, potentiellement changeant, d’un organisme, à distinguer du génotype, qui est dérivé de la composition génétique d’un organisme. Le terme phénotype peut être appliqué aux caractéristiques des patients inférées à partir des données des dossiers de santé électroniques (DSE). Les chercheurs ont effectué le phénotypage des DSE depuis le début de l’informatique, à partir des données structurées et des données narratives. L’objectif est de tirer des conclusions sur un concept cible à partir des données brutes des DSE, des données de réclamations ou d’autres données cliniquement pertinentes. Les algorithmes de phénotype - c’est-à-dire les algorithmes qui identifient ou caractérisent les phénotypes - peuvent être générés par des experts du domaine et des ingénieurs en connaissance, y compris les recherches récentes en ingénierie des connaissances ou par diverses formes d’apprentissage automatique… pour générer des représentations inédites des données.”
Cette description met en lumière plusieurs attributs utiles à renforcer lorsque l’on considère la validité clinique : 1) elle précise que nous parlons de quelque chose d’observable (et donc susceptible d’être capturé dans nos données observationnelles) ; 2) elle inclut la notion de temps dans la spécification du phénotype (puisqu’un état d’une personne peut changer) ; 3) elle fait une distinction entre le phénotype en tant qu’intention souhaitée vs. l’algorithme phénotypique, qui est la mise en œuvre de l’intention souhaitée.
OHDSI a adopté le terme “cohorte” pour définir l’ensemble des personnes satisfaisant un ou plusieurs critères d’inclusion pendant une durée déterminée. Une “définition de cohorte” représente la logique nécessaire pour instancier une cohorte en utilisant une base de données observationnelles. À cet égard, la définition de la cohorte (ou algorithme phénotypique) est utilisée pour produire une cohorte, qui est censée représenter le phénotype, à savoir les personnes appartenant à l’état clinique observable d’intérêt.
La plupart des types d’analyses observationnelles, y compris la caractérisation clinique, l’estimation des effets à l’échelle de la population et la prédiction au niveau du patient, nécessitent l’établissement d’une ou plusieurs cohortes dans le cadre du processus d’étude. Pour évaluer la validité des preuves produites par ces analyses, il faut se poser cette question pour chaque cohorte : dans quelle mesure les personnes identifiées dans la cohorte basée sur la définition de la cohorte et les données observationnelles disponibles reflètent-elles avec précision les personnes qui appartiennent véritablement au phénotype ?
Pour revenir à l’exemple de l’estimation à l’échelle de la population (chapitre 12) “Les inhibiteurs de l’ECA causent-ils un œdème de Quincke par rapport aux diurétiques thiazidiques ou thiazidiques-like ?”, nous devons définir trois cohortes : une cohorte cible de personnes qui sont de nouveaux utilisateurs d’inhibiteurs de l’ECA, une cohorte comparatrice de personnes qui sont de nouveaux utilisateurs de diurétiques thiazidiques, et une cohorte d’issue de personnes qui développent un œdème de Quincke. Dans quelle mesure sommes-nous confiants que tout usage des inhibiteurs de l’ECA ou des diurétiques thiazidiques est complètement capturé, de sorte que les “nouveaux utilisateurs” puissent être identifiés par la première exposition observée, sans préoccupation d’un usage antérieur (mais non observé) ? Pouvons-nous inférer confortablement que les personnes ayant un enregistrement d’exposition à un médicament pour les inhibiteurs de l’ECA ont effectivement été exposées au médicament, et celles sans enregistrement d’exposition à un médicament n’ont effectivement pas été exposées ? Y a-t-il une incertitude quant à la définition de la durée pendant laquelle une personne est classée dans l’état “d’utilisation d’inhibiteur de l’ECA”, que ce soit lors de l’inférence de l’entrée de la cohorte au moment où le médicament a été commencé ou de la sortie de la cohorte lorsque le médicament a été interrompu ? Les personnes ayant un enregistrement de survenue d’une “Angioedema” ont-elles réellement vécu une enflure rapide sous la peau, différenciée des autres types de réactions allergiques dermatologiques ? Quelle proportion de patients qui ont développé un œdème de Quincke ont reçu une attention médicale qui aurait donné lieu aux données observationnelles utilisées pour identifier ces cas cliniques basés sur la définition de la cohorte ? Dans quelle mesure les événements d’œdème de Quincke potentiellement induits par un médicament peuvent-ils être disambigués des événements connus pour être causés par d’autres agents, tels que les allergies alimentaires ou les infections virales ? La survenue de la maladie est-elle suffisamment bien capturée pour que nous ayons confiance dans l’établissement d’une association temporelle entre le statut d’exposition et l’incidence de l’issue ? Répondre à ces types de questions est au cœur de la validité clinique.
Dans ce chapitre, nous discuterons des méthodes de validation des définitions de cohortes. Nous décrivons d’abord les métriques utilisées pour mesurer la validité d’une définition de cohorte. Ensuite, nous décrivons deux méthodes pour estimer ces métriques : 1) l’adjudication clinique par vérification des dossiers sources, et 2) PheValuator, une méthode semi-automatique utilisant la modélisation prédictive diagnostique.
16.1.1 Métriques d’évaluation des cohortes
Une fois que la définition de la cohorte pour l’étude a été déterminée, la validité de la définition peut être évaluée. Une approche courante pour évaluer la validité consiste à comparer certaines ou toutes les personnes d’une cohorte définie à une référence “étalon-or” et à exprimer les résultats dans une matrice de confusion, une table de contingence à deux par deux qui stratifie les personnes selon leur classification étalon-or et leur qualification au sein de la définition de la cohorte. La figure 16.1 montre les éléments de la matrice de confusion.

Figure 16.1: Matrice de confusion.
Les résultats vrais et faux de la définition de la cohorte sont déterminés en appliquant la définition à un groupe de personnes. Celles incluses dans la définition sont considérées comme positives pour la condition de santé et sont étiquetées “Vrais”. Les personnes non incluses dans la définition de la cohorte sont considérées comme négatives pour la condition de santé et sont étiquetées “Faux”. Bien que la vérité absolue de l’état de santé d’une personne considérée dans la définition de la cohorte soit très difficile à déterminer, il existe plusieurs méthodes pour établir une référence de l’étalon-or, dont deux seront décrites plus loin dans le chapitre. Quelle que soit la méthode utilisée, l’étiquetage de ces personnes est le même que celui décrit pour la définition de la cohorte.
En plus des erreurs dans l’indication binaire de la désignation du phénotype, la chronologie de l’état de santé peut également être incorrecte. Par exemple, alors que la définition de la cohorte peut correctement étiqueter une personne comme appartenant à un phénotype, la définition peut spécifier incorrectement la date et l’heure où une personne sans la condition est devenue une personne avec la condition. Cette erreur ajouterait un biais aux études utilisant les résultats de l’analyse de survie, par exemple, les rapports de risques, comme mesure d’effet.
La prochaine étape du processus consiste à évaluer la concordance de l’étalon-or avec la définition de la cohorte. Les personnes qui sont étiquetées à la fois par la méthode de référence étalon-or et la définition de la cohorte comme “Vrai” sont appelées “Vrais Positifs”. Les personnes étiquetées par la méthode de référence étalon-or comme “Faux” et par la définition de la cohorte comme “Vrai” sont appelées “Faux Positifs”, c’est-à-dire que la définition de la cohorte a mal classifié ces personnes comme ayant la condition alors qu’elles ne l’ont pas. Les personnes étiquetées à la fois par la méthode de référence et la définition de la cohorte comme “Faux” sont appelées “Vrais Négatifs”. Les personnes étiquetées par la méthode de référence comme “Vrai” et par la définition de la cohorte comme “Faux” sont appelées “Faux Négatifs”, c’est-à-dire que la définition de la cohorte a incorrectement classifié ces personnes comme ne présentant pas la condition, bien qu’elles appartiennent en fait au phénotype. En utilisant les comptes des quatre cases de la matrice de confusion, nous pouvons quantifier l’exactitude de la définition de la cohorte pour classifier le statut de phénotype chez un groupe de personnes. Il existe des métriques de performance standard pour mesurer la performance de la définition de la cohorte :
Sensibilité de la définition de la cohorte – quelle proportion des personnes qui appartiennent réellement au phénotype dans la population ont été correctement identifiées pour avoir le résultat de santé basé sur la définition de la cohorte ? Cela est déterminé par la formule suivante :
Sensibilité = Vrais Positifs / (Vrais Positifs + Faux Négatifs)
Spécificité de la définition de la cohorte – quelle proportion des personnes qui n’appartiennent pas au phénotype dans la population ont été correctement identifiées pour ne pas avoir le résultat de santé basé sur la définition de la cohorte ? Cela est déterminé par la formule suivante :
Spécificité = Vrais Négatifs / (Vrais Négatifs + Faux Positifs)
Valeur prédictive positive (VPP) de la définition de la cohorte – quelle proportion des personnes identifiées par la définition de la cohorte comme ayant la condition de santé appartiennent réellement au phénotype ? Cela est déterminé par la formule suivante :
VPP = Vrais Positifs / (Vrais Positifs + Faux Positifs)
Valeur prédictive négative (VPN) de la définition de la cohorte – quelle proportion des personnes identifiées par la définition de la cohorte comme ne présentant pas la condition de santé n’appartenaient réellement pas au phénotype ? Cela est déterminé par la formule suivante :
VPN = Vrais Négatifs / (Vrais Négatifs + Faux Négatifs)
Les scores parfaits pour ces mesures sont de 100 %. En raison de la nature des données observationnelles, les scores parfaits sont généralement loin d’être la norme. Rubbo et al. (2015) a passé en revue des études validant les définitions de cohortes pour l’infarctus du myocarde. Sur les 33 études qu’ils ont examinées, une seule définition de cohorte dans un seul ensemble de données a obtenu un score parfait pour la VPP. Globalement, 31 des 33 études ont rapporté des VPP ≥ 70 %. Ils ont également constaté, cependant, que sur les 33 études, seulement 11 rapportaient la sensibilité et 5 rapportaient la spécificité. La VPP est une fonction de la sensibilité, de la spécificité et de la prévalence. Les ensembles de données avec des valeurs de prévalence différentes produiront des valeurs différentes pour la VPP avec la sensibilité et la spécificité constantes. Sans sensibilité et spécificité, il est impossible de corriger les biais dus aux définitions de cohorte imparfaites. De plus, la classification erronée de la condition de santé peut être différentielle, ce qui signifie que la définition de cohorte fonctionne différemment sur un groupe de personnes par rapport au groupe de comparaison, ou non différentielle, lorsque la définition de cohorte fonctionne de manière similaire sur les deux groupes de comparaison. Les études antérieures de validation de la définition de cohorte n’ont pas testé la possibilité de classification erronée différentielle, même si elle peut entraîner un fort biais dans les estimations de l’effet.
Une fois que les métriques de performance ont été établies pour la définition de la cohorte, celles-ci peuvent être utilisées pour ajuster les résultats des études utilisant ces définitions. En théorie, l’ajustement des résultats des études pour ces estimations d’erreur de mesure est bien établi. En pratique, cependant, en raison de la difficulté à obtenir les caractéristiques de performance, ces ajustements sont rarement pris en compte. Les méthodes utilisées pour déterminer l’étalon-or sont décrites dans le reste de cette section.
16.2 Vérification des dossiers sources
Une méthode courante pour valider les définitions de cohortes est l’adjudication clinique par la vérification des dossiers sources : un examen approfondi des dossiers d’une personne par un ou plusieurs experts dans le domaine ayant une connaissance suffisante pour classer de manière compétente l’état ou la caractéristique clinique d’intérêt. La revue de dossier suit généralement les étapes suivantes :
- Obtenir l’autorisation du comité d’examen institutionnel local (IRB) et/ou des personnes nécessaires pour mener l’étude, y compris la revue des dossiers.
- Générer la cohorte en utilisant la définition de la cohorte à évaluer. Échantillonner un sous-ensemble des personnes à examiner manuellement s’il n’y a pas suffisamment de ressources pour juger l’ensemble de la cohorte.
- Identifier une ou plusieurs personnes ayant une expertise clinique suffisante pour examiner les dossiers des patients.
- Déterminer les directives pour décider si une personne est positive ou négative pour l’état clinique ou la caractéristique souhaitée.
- Les experts cliniques examinent et jugent toutes les données disponibles pour les personnes dans l’échantillon pour classer chaque individu selon qu’ils appartiennent ou non au phénotype.
- Tabuler les individus selon la classification de la définition de la cohorte et la classification de l’adjudication clinique dans une matrice de confusion, et calculer les caractéristiques de performance possibles à partir des données collectées.
Les résultats d’une revue de dossier sont généralement limités à l’évaluation d’une seule caractéristique de performance, la valeur prédictive positive (PPV). Cela est dû au fait que la définition de la cohorte évaluée ne génère que des personnes censées avoir la condition ou les caractéristiques souhaitées. Par conséquent, chaque personne de l’échantillon de la cohorte est classée soit comme vrai positif, soit comme faux positif basé sur l’adjudication clinique. Sans connaître toutes les personnes du phénotype dans la population entière (y compris celles non identifiées par la définition de la cohorte), il n’est pas possible d’identifier les faux négatifs et ainsi remplir le reste de la matrice de confusion pour générer les autres caractéristiques de performance. Les méthodes potentielles pour identifier toutes les personnes dans le phénotype à travers la population incluent la revue des dossiers de toute la base de données, ce qui n’est généralement pas faisable à moins que la population totale soit petite, ou l’utilisation de registres cliniques complets dans lesquels tous les vrais cas ont déjà été signalés et adjugés, comme les registres de tumeurs (voir exemple ci-dessous). Alternativement, on peut échantillonner les personnes qui ne remplissent pas les critères de la définition de la cohorte pour produire un sous-ensemble de négatifs prédits, puis répéter les étapes 3-6 de la revue de dossier mentionnées ci-dessus pour vérifier si ces patients manquent réellement de l’état clinique ou de la caractéristique d’intérêt afin d’identifier les vrais négatifs ou les faux négatifs. Cela permettrait l’estimation de la valeur prédictive négative (NPV), et si une estimation appropriée de la prévalence du phénotype est disponible, la sensibilité et la spécificité peuvent être estimées.
Il existe un certain nombre de limitations à l’adjudication clinique par la vérification des dossiers sources. Comme mentionné précédemment, la revue de dossier peut être un processus très chronophage et nécessitant beaucoup de ressources, même pour l’évaluation d’une seule métrique telle que la PPV. Cette limitation empêche considérablement la praticité d’évaluer une population entière pour remplir une matrice de confusion complète. De plus, plusieurs étapes du processus ci-dessus peuvent biaiser les résultats de l’étude. Par exemple, si les dossiers ne sont pas également accessibles dans le DSE, s’il n’y a pas de DSE, ou si le consentement individuel des patients est requis, alors le sous-ensemble évalué peut ne pas être véritablement aléatoire et pourrait introduire un biais d’échantillonnage ou de sélection. De plus, l’adjudication manuelle est susceptible d’erreurs humaines ou de mauvaise classification et peut donc ne pas représenter une métrique parfaitement précise. Il peut souvent y avoir des désaccords entre les adjudicateurs cliniques en raison des données dans le dossier de la personne étant vagues, subjectives ou de faible qualité. Dans de nombreuses études, le processus implique une décision par majorité pour un consensus qui donne une classification binaire pour les personnes qui ne reflète pas la discordance entre les évaluateurs.
16.2.1 Exemple de vérification des dossiers sources
Un exemple du processus de conduite d’une validation de définition de cohorte en utilisant la revue de dossier est fourni par une étude de Columbia University Irving Medical Center (CUIMC), qui a validé une définition de cohorte pour plusieurs cancers dans le cadre d’une étude de faisabilité pour le National Cancer Institute (NCI). Les étapes utilisées pour mener la validation pour l’exemple de l’un de ces cancers—le cancer de la prostate—sont les suivantes :
- Proposition soumise et consentement obtenu de l’IRB pour l’étude de phénotypage du cancer d’OHDSI.
- Développement d’une définition de cohorte pour le cancer de la prostate : Utilisation d’ATHENA et ATLAS pour explorer le vocabulaire, nous avons créé une définition de cohorte incluant tous les patients avec une occurrence de condition pour Tumeur Maligne de la Prostate (ID concept 4163261), excluant Néoplasme Secondaire de la Prostate (ID concept 4314337) ou Lymphome Non-Hodgkinien de la Prostate (ID concept 4048666).
- Génération de la cohorte en utilisant ATLAS et sélection aléatoire de 100 patients pour revue manuelle, en mappant chaque PERSON_ID au MRN du patient en utilisant les tables de mappage. 100 patients ont été sélectionnés afin d’atteindre notre niveau désiré de précision statistique pour la métrique de performance de PPV.
- Revue manuelle des dossiers dans divers DSE—à la fois en hospitalisation et en consultation externe—afin de déterminer si chaque personne dans le sous-ensemble aléatoire était un vrai ou faux positif.
- La revue manuelle et l’adjudication clinique ont été effectuées par un médecin (même si idéalement à l’avenir, des études de validation plus rigoureuses seraient réalisées par un plus grand nombre de réviseurs pour évaluer le consensus et la fiabilité inter-juges).
- La détermination d’un standard de référence était basée sur la documentation clinique, les rapports de pathologie, les laboratoires, les médicaments et les procédures tels que documentés dans l’entièreté du dossier patient électronique disponible.
- Les patients ont été étiquetés comme 1) cancer de la prostate 2) pas de cancer de la prostate ou 3) impossible à déterminer.
- Une estimation conservative de la PPV a été calculée en utilisant le ratio suivant : cancer de la prostate / (pas de cancer de la prostate + impossible à déterminer).
- Ensuite, en utilisant le registre des tumeurs comme standard d’or supplémentaire pour identifier un standard de référence dans toute la population de CUIMC, nous avons compté le nombre de personnes dans le registre des tumeurs qui ont été correctement ou incorrectement identifiées par la définition de la cohorte, ce qui nous a permis d’estimer la sensibilité en utilisant ces valeurs comme vrais positifs et faux négatifs.
- En utilisant la sensibilité estimée, la PPV et la prévalence, nous avons pu estimer la spécificité pour cette définition de cohorte.
Comme mentionné précédemment, ce processus était chronophage et nécessitant beaucoup de main-d’œuvre, car chaque définition de cohorte devait être individuellement évaluée par une revue de dossier manuelle ainsi que corrélée avec le registre des tumeurs de CUIMC pour identifier toutes les métriques de performance. Le processus d’approbation de l’IRB lui-même a pris des semaines malgré un examen accéléré alors que l’obtention de l’accès au registre des tumeurs, et le processus de revue de dossier manuelle a pris quelques semaines supplémentaires.
Une revue des efforts de validation pour les définitions de cohortes d’infarctus du myocarde (IM) par Rubbo et al. (2015) a révélé qu’il y avait une hétérogénéité significative dans les définitions de cohortes utilisées dans les études ainsi que dans les méthodes de validation et les résultats rapportés. Les auteurs ont conclu que pour l’infarctus du myocarde aigu, il n’y a pas de définition de cohorte standard disponible. Ils ont noté que le processus était à la fois coûteux et chronophage. En raison de cette limitation, la majorité des études avaient de petits échantillons dans leur validation, ce qui a conduit à de grandes variations dans les estimations des caractéristiques de performance. Ils ont également noté que parmi les 33 études, alors que toutes les études ont rapporté la valeur prédictive positive, seules 11 études ont rapporté la sensibilité et seulement cinq études ont rapporté la spécificité. Comme mentionné précédemment, sans estimations de la sensibilité et de la spécificité, une correction statistique pour le biais de classification ne peut pas être effectuée.
16.3 PheValuator
La communauté OHDSI a développé une approche différente pour construire un standard de référence en utilisant des modèles prédictifs diagnostiques. (Swerdel, Hripcsak, and Ryan 2019) L’idée générale est d’émuler la détermination de l’issue de santé de manière similaire à celle des cliniciens dans une validation de dossier source, mais de manière automatisée pouvant être appliquée à grande échelle. L’outil a été développé sous forme de package R open-source appelé PheValuator.58 PheValuator utilise des fonctions du package Patient Level Prediction.
Le processus est le suivant :
- Créez une cohorte extrêmement spécifique (« xSpec ») : Déterminez un ensemble de personnes avec une très haute probabilité d’avoir l’issue d’intérêt à utiliser comme étiquettes positives bruyantes lors de la formation d’un modèle prédictif diagnostique.
- Créez une cohorte extrêmement sensible (« xSens ») : Déterminez un ensemble de personnes qui devrait inclure toute personne pouvant avoir l’issue. Cette cohorte sera utilisée pour identifier son inverse : l’ensemble des personnes dont nous sommes certains de ne pas avoir l’issue, à utiliser comme étiquettes négatives bruyantes lors de la formation d’un modèle prédictif diagnostique.
- Ajustez un modèle prédictif en utilisant les cohortes xSpec et xSens : Comme décrit au Chapitre 13, nous ajustons un modèle en utilisant une large gamme de caractéristiques des patients comme prédicteurs et visons à prédire si une personne appartient à la cohorte xSpec (ceux que nous croyons avoir l’issue) ou à l’inverse de la cohorte xSens (ceux que nous croyons ne pas avoir l’issue).
- Appliquez le modèle ajusté pour estimer la probabilité de l’issue pour un ensemble de personnes de validation qui sera utilisé pour évaluer la performance de la définition de la cohorte : Les prédicteurs du modèle peuvent être appliqués aux données d’une personne pour estimer la probabilité prédite que la personne appartienne au phénotype. Nous utilisons ces prédictions comme une référence probabiliste.
- Évaluez les caractéristiques de performance des définitions de cohortes : Nous comparons la probabilité prédite à la classification binaire d’une définition de cohorte (les conditions de test pour la matrice de confusion). En utilisant les conditions de test et les estimations des conditions réelles, nous pouvons remplir entièrement la matrice de confusion et estimer l’ensemble des caractéristiques de performance, c’est-à-dire, sensibilité, spécificité et valeurs prédictives.
La principale limitation de cette approche est que l’estimation de la probabilité qu’une personne ait l’issue de santé est limitée par les données de la base de données. Selon la base de données, des informations importantes, telles que des notes de clinicien, peuvent ne pas être disponibles.
En modélisation prédictive diagnostique, nous créons un modèle qui discrimine entre ceux ayant la maladie et ceux n’ayant pas la maladie. Comme décrit dans le chapitre Prédiction au Niveau du Patient (Chapter 13), les modèles prédictifs sont développés en utilisant une cohorte cible et une cohorte d’issue. La cohorte cible inclut des personnes avec et sans l’issue de santé ; la cohorte d’issue identifie ces personnes dans la cohorte cible avec l’issue de santé. Pour le processus PheValuator, nous utilisons une définition de cohorte extrêmement spécifique, la cohorte “xSpec”, pour déterminer la cohorte d’issue pour le modèle prédictif. La cohorte xSpec utilise une définition pour trouver ceux ayant une très forte probabilité d’avoir la maladie d’intérêt. La cohorte xSpec peut être définie comme ces personnes ayant plusieurs enregistrements d’occurrence de condition pour l’issue de santé d’intérêt. Par exemple, pour la fibrillation auriculaire, nous pouvons avoir des personnes ayant 10 ou plus de dossiers avec le code de diagnostic de fibrillation auriculaire. Pour l’infarctus du myocarde (IM), une issue aiguë, nous pouvons utiliser 5 occurrences de l’IM et inclure l’exigence d’avoir au moins deux occurrences en milieu hospitalier. La cohorte cible pour le modèle prédictif est construite à partir de l’union des personnes ayant une faible probabilité d’avoir l’issue de santé d’intérêt et de celles de la cohorte xSpec. Pour déterminer ces personnes ayant une faible probabilité d’avoir l’issue de santé d’intérêt, nous échantillonnons toute la base de données et excluons les personnes ayant des preuves suggérant qu’elles appartiennent au phénotype, typiquement en supprimant les personnes ayant des enregistrements contenant les concepts utilisés pour définir la cohorte xSpec. Il existe des limitations à cette méthode. Il est possible que ces personnes de la cohorte xSpec aient des caractéristiques différentes des autres ayant la maladie. Il est également possible que ces personnes aient eu un temps d’observation plus long après le diagnostic initial que le patient moyen. Nous utilisons la régression logistique LASSO pour créer le modèle prédictif utilisé pour générer la référence probabiliste.(Suchard et al. 2013) Cet algorithme produit un modèle parcimonieux et élimine généralement de nombreuses covariables collinéaires qui peuvent être présentes dans l’ensemble de données. Dans la version actuelle du logiciel PheValuator, le statut de l’issue (oui/non) est évalué en fonction de toutes les données d’une personne (tout le temps d’observation), et n’évalue pas la précision de la date de début de la cohorte.
16.3.1 Validation d’Exemple avec PheValuator
Nous pouvons utiliser PheValuator pour évaluer les caractéristiques complètes de performance d’une définition de cohorte à utiliser dans une étude où il est nécessaire de déterminer les personnes ayant eu un infarctus du myocarde aigu.
Les étapes suivantes sont destinées à tester les définitions de cohortes pour l’IM en utilisant PheValuator :
Étape 1 : Définir la Cohorte xSpec
Déterminez ceux avec l’IM avec une haute probabilité. Nous avons exigé un enregistrement d’occurrence de condition avec un concept pour l’infarctus du myocarde ou l’un de ses descendants, avec une ou plusieurs occurrences d’IM enregistrées lors d’une visite hospitalière en milieu hospitalier en moins de 5 jours, et 4 ou plus d’occurrences d’IM dans le dossier du patient en moins de 365 jours. La Figure 16.2 illustre cette définition de cohorte pour l’IM dans ATLAS.
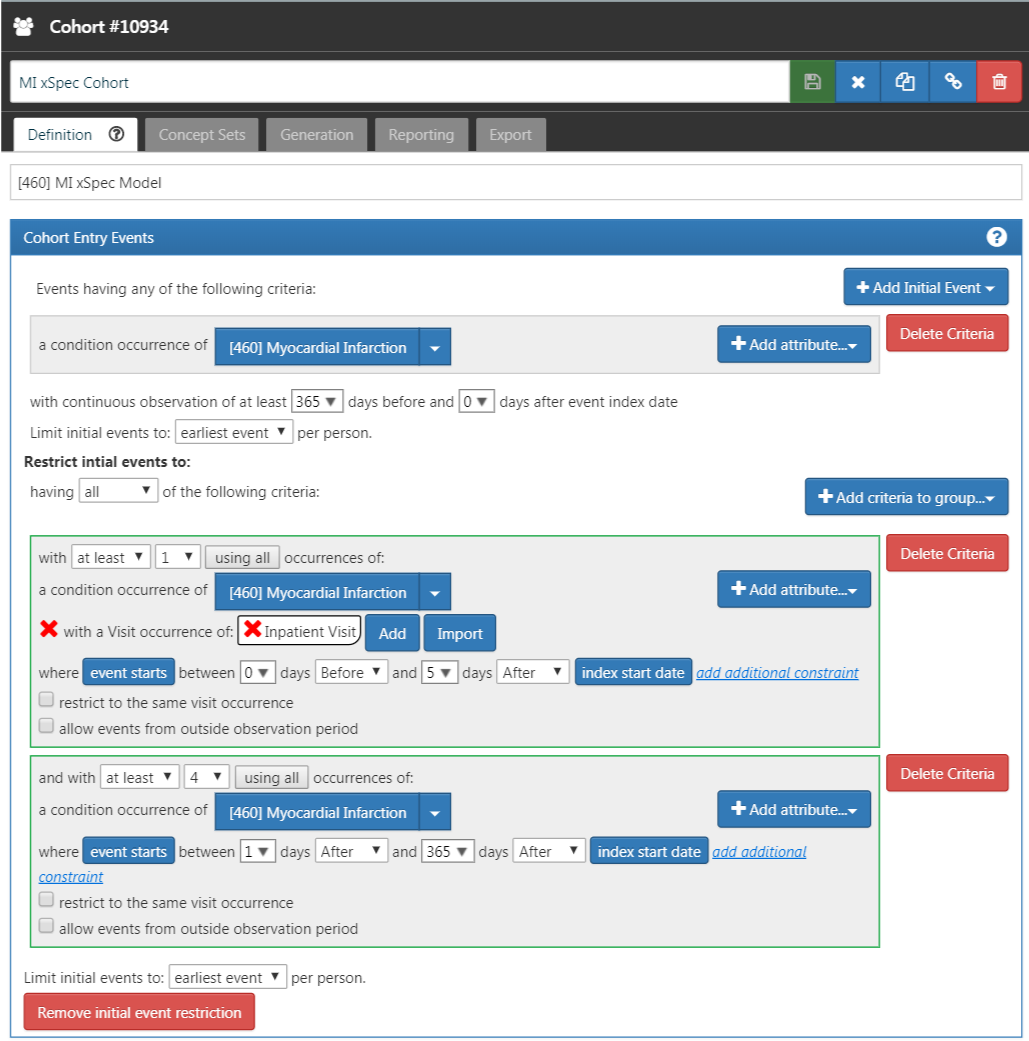
Figure 16.2: An extremely specific cohort definition (xSpec) for myocardial infarction.
Étape 2 : Définir la Cohorte xSens
Nous développons alors une cohorte extrêmement sensible (xSens). Cette cohorte peut être définie pour l’IM comme ces personnes ayant au moins un enregistrement d’occurrence de condition contenant un concept d’infarctus du myocarde à tout moment dans leur historique médical. La Figure 16.3 illustre la définition de la cohorte xSens pour l’IM dans ATLAS.
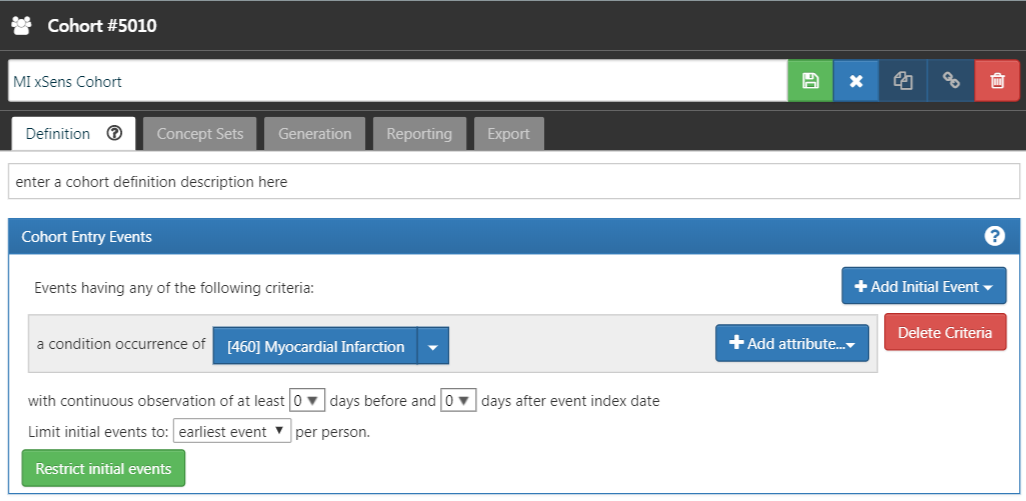
Figure 16.3: An extremely sensitive cohort definition (xSens) for myocardial infarction.
Étape 3 : Ajuster le Modèle Prédictif
La fonction createPhenoModel développe le modèle prédictif diagnostique pour évaluer la probabilité d’avoir l’issue de santé d’intérêt dans la cohorte d’évaluation. Pour utiliser cette fonction, nous utilisons les cohortes xSpec et xSens développées aux étapes 1 et 2. La cohorte xSpec sera entrée comme paramètre xSpecCohort dans la fonction. La cohorte xSens sera entrée en tant que paramètre exclCohort dans la fonction pour indiquer que ceux de la cohorte xSens doivent être exclus de la cohorte cible utilisée dans le processus de modélisation. En utilisant cette méthode d’exclusion, nous pouvons déterminer les personnes ayant une faible probabilité d’avoir l’issue de santé. Nous pouvons penser à ce groupe comme des personnes « bruyamment négatives » c’est-à-dire un groupe de personnes probablement négatif pour l’issue de santé mais permettant une petite possibilité d’inclure des personnes positives pour l’issue de santé. Nous pouvons également utiliser la cohorte xSens comme le paramètre prevCohort dans la fonction. Ce paramètre est utilisé dans le processus pour déterminer une prévalence approximative de l’issue de santé dans la population. Normalement, un échantillon aléatoire important de personnes d’une base de données devrait produire une population de personnes où les personnes avec l’issue d’intérêt sont environ proportionnelles à la prévalence de l’issue dans la base de données. En utilisant la méthode décrite, nous n’avons plus un échantillon aléatoire de personnes et devons recalibrer le modèle prédictif basé sur la réinitialisation de la proportion de personnes avec l’issue par rapport à celles sans l’issue.
Tous les concepts utilisés pour définir la cohorte xSpec doivent être exclus du processus de modélisation. Pour ce faire, nous définissons le paramètre excludedConcepts sur la liste des concepts utilisés dans la définition xSpec. Par exemple, pour l’IM, nous avons créé un ensemble de concepts dans ATLAS en utilisant le concept d’infarctus du myocarde et tous ses descendants. Pour cet exemple, nous définirions le paramètre excludedConcepts sur 4329847, l’Id de concept pour l’infarctus du myocarde, et nous définirions également le paramètre addDescendantsToExclude sur TRUE, indiquant que tous les descendants des concepts exclus doivent également être exclus.
Il existe plusieurs paramètres qui peuvent être utilisés pour spécifier les caractéristiques des personnes incluses dans le processus de modélisation. Nous pouvons définir les âges des personnes incluses dans le processus de modélisation en définissant la lowerAgeLimit aux limites inférieures d’âge désirées dans le modèle et la upperAgeLimit aux limites supérieures. Nous pouvons souhaiter le faire si les définitions de cohortes pour une étude planifiée seront créées pour un certain groupe d’âge. Par exemple, si la définition de cohorte à utiliser dans une étude est pour le diabète de type 1 chez les enfants, vous pouvez vouloir limiter les âges utilisés pour développer le modèle prédictif diagnostique de 5 à 17 ans par exemple. Ce faisant, nous produirons un modèle avec des caractéristiques qui sont probablement plus étroitement liées aux personnes sélectionnées par les définitions de cohortes à tester. Nous pouvons également spécifier quel sexe est inclus dans le modèle en définissant le paramètre gender sur l’ID de concept pour soit l’homme ou la femme. Par défaut, le paramètre est défini pour inclure les hommes et les femmes. Cette fonction peut être utile dans des issues de santé spécifiques au sexe telles que le cancer de la prostate. Nous pouvons définir la période d’inclusion des personnes sur la base de la première visite dans le dossier de la personne en définissant les paramètres startDate et endDate aux bornes inférieures et supérieures de la plage de dates, respectivement. Enfin, le paramètre mainPopnCohort peut être utilisé pour spécifier une grande cohorte de population à partir de laquelle toutes les personnes des cohortes cible et d’issue seront sélectionnées. Dans la plupart des cas, cela sera défini à 0, indiquant qu’il n’y a pas de limitation à la sélection des personnes pour les cohortes cible et d’issue. Cependant, il peut y avoir des moments où ce paramètre est utile pour construire un meilleur modèle, peut-être dans des cas où la prévalence de l’issue de santé est extrêmement faible, peut-être de 0,01% ou moins. Par exemple :
setwd("c:/temp")
library(PheValuator)
connectionDetails <- createConnectionDetails(
dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
phenoTest <- createPhenoModel(
connectionDetails = connectionDetails,
xSpecCohort = 10934,
cdmDatabaseSchema = "my_cdm_data",
cohortDatabaseSchema = "my_results",
cohortDatabaseTable = "cohort",
outDatabaseSchema = "scratch.dbo", #doit avoir accès en écriture
trainOutFile = "5XMI_train",
exclCohort = 1770120, #la cohorte xSens
prevCohort = 1770119, #la cohorte pour la détermination de la prévalence
modelAnalysisId = "20181206V1",
excludedConcepts = c(312327, 314666),
addDescendantsToExclude = TRUE,
cdmShortName = "myCDM",
mainPopnCohort = 0, #utilisez toute la population de personnes
lowerAgeLimit = 18,
upperAgeLimit = 90,
gender = c(8507, 8532),
startDate = "20100101",
endDate = "20171231")Dans cet exemple, nous avons utilisé les cohortes définies dans la base de données “my_results”, en spécifiant l’emplacement de la table de cohorte (cohortDatabaseSchema, cohortDatabaseTable - “my_results.cohort”) et où le modèle trouvera les conditions, expositions aux médicaments, etc., pour informer le modèle (cdmDatabaseSchema - “my_cdm_data”). Les personnes incluses dans le modèle seront celles dont la première visite dans le CDM est entre le 1er janvier 2010 et le 31 décembre 2017. Nous excluons également spécifiquement les ID de concept 312327, 314666 et leurs descendants qui ont été utilisés pour créer la cohorte xSpec. Leurs âges au moment de la première visite seront entre 18 et 90. Avec les paramètres ci-dessus, le nom du modèle prédictif de sortie de cette étape sera : « c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds »
Étape 4 : Création de la Cohorte d’Évaluation
La fonction createEvalCohort utilise la fonction applyModel du package PatientLevelPrediction pour produire une grande cohorte de personnes, chacune avec une probabilité prédite pour l’issue de santé d’intérêt. La fonction nécessite de spécifier la cohorte xSpec (en définissant le paramètre xSpecCohort sur l’ID de la cohorte xSpec). Nous pouvons également spécifier les caractéristiques des personnes incluses dans la cohorte d’évaluation comme nous l’avons fait à l’étape précédente. Cela pourrait inclure la spécification des limites d’âge inférieures et supérieures (en définissant les arguments lowerAgeLimit et upperAgeLimit, respectivement), le sexe (en définissant le paramètre gender sur les IDs de concept pour homme et/ou femme), les dates de début et de fin (en définissant les arguments startDate et endDate, respectivement), et désignant une grande population à partir de laquelle sélectionner les personnes en définissant le mainPopnCohort sur l’ID de cohorte pour la population à utiliser.
Par exemple :
setwd("c:/temp")
connectionDetails <- createConnectionDetails(
dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
evalCohort <- createEvalCohort(
connectionDetails = connectionDetails,
xSpecCohort = 10934,
cdmDatabaseSchema = "my_cdm_data",
cohortDatabaseSchema = "my_results",
cohortDatabaseTable = "cohort",
outDatabaseSchema = "scratch.dbo",
testOutFile = "5XMI_eval",
trainOutFile = "5XMI_train",
modelAnalysisId = "20181206V1",
evalAnalysisId = "20181206V1",
cdmShortName = "myCDM",
mainPopnCohort = 0,
lowerAgeLimit = 18,
upperAgeLimit = 90,
gender = c(8507, 8532),
startDate = "20100101",
endDate = "20171231")Dans cet exemple, les paramètres spécifient que la fonction doit utiliser le fichier de modèle : « c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds » pour produire le fichier de la cohorte d’évaluation : « c:/temp/lr_results_5XMI_eval_myCDM_ePPV0.75_20181206V1.rds » Les fichiers de modèle et de la cohorte d’évaluation créés à cette étape seront utilisés pour l’évaluation des définitions de cohortes fournies à l’étape suivante.
Étape 5 : Création et Test des Définitions de Cohortes
L’étape suivante est de créer et tester les définitions de cohortes à évaluer. Les caractéristiques de performance souhaitées peuvent dépendre de l’utilisation prévue de la cohorte pour répondre à la question de recherche d’intérêt. Pour certaines questions, un algorithme très sensible peut être nécessaire ; d’autres peuvent nécessiter un algorithme plus spécifique. Le processus de détermination des caractéristiques de performance pour une définition de cohorte en utilisant PheValuator est montré à la Figure 16.4.
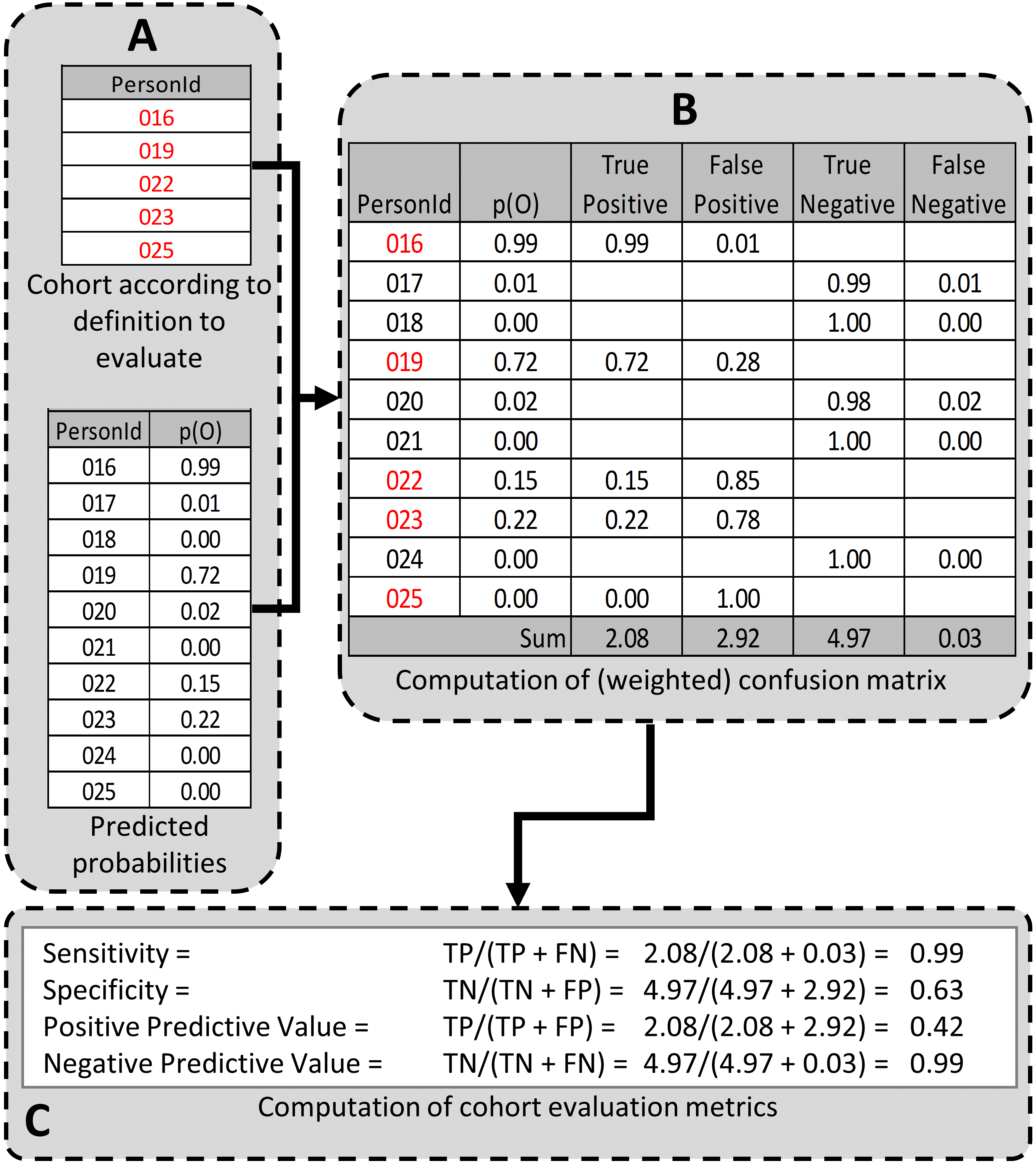
Figure 16.4: Determining the Performance Characteristics of a cohort definition using PheValuator. p(O) = Probability of outcome; TP = True Positive; FN = False Negative; TN = True Negative; FP = False Positive.
Dans la partie A de la Figure 16.4, nous avons examiné les personnes de la définition de cohorte à tester et trouvé ces personnes de la cohorte d’évaluation (créée à l’étape précédente) ## Généralisation des preuves {#GeneralizabilityOfEvidence}
Bien qu’une cohorte puisse être bien définie et pleinement évaluée dans le contexte d’une base de données observationnelle donnée, la validité clinique est limitée par la mesure dans laquelle les résultats sont considérés comme généralisables à la population cible d’intérêt. Plusieurs études observationnelles sur le même sujet peuvent produire des résultats différents, ce qui peut être causé non seulement par leurs conceptions et méthodes analytiques, mais aussi par leur choix de source de données. Madigan et al. (2013) a démontré que le choix de la base de données affecte le résultat d’une étude observationnelle. Ils ont systématiquement étudié l’hétérogénéité des résultats pour 53 couples médicament-événement et deux conceptions d’étude (études de cohorte et séries de cas auto-contrôlées) dans les 10 bases de données observationnelles. Même s’ils ont maintenu constant le design de l’étude, une hétérogénéité substantielle des estimations d’effet a été observée.
À travers le réseau OHDSI, les bases de données observationnelles varient considérablement quant aux populations qu’elles représentent (par exemple, pédiatrique vs. personnes âgées, employés assurés privément vs. chômeurs assurés publiquement), aux environnements de soins où les données sont capturées (par exemple, hospitalisation vs. soins ambulatoires, soins primaires vs. secondaires/spécialités), aux processus de capture des données (par exemple, réclamations administratives, DME, registres cliniques), et au système de santé national et régional sur lequel les soins sont basés. Ces différences peuvent se manifester sous forme d’hétérogénéité observée lors de l’étude de maladies et des effets des interventions médicales et peuvent également influencer la confiance que nous avons dans la qualité de chaque source de données pouvant contribuer aux preuves dans une étude de réseau. Bien que toutes les bases de données du réseau OHDSI soient standardisées au CDM, il est important de souligner que la standardisation ne réduit pas la véritable hétérogénéité inhérente présente à travers les populations, mais fournit simplement un cadre cohérent pour enquêter et mieux comprendre l’hétérogénéité à travers le réseau. Le réseau de recherche OHDSI offre l’environnement pour appliquer le même processus analytique sur différentes bases de données à travers le monde, afin que les chercheurs puissent interpréter les résultats sur plusieurs sources de données tout en maintenant constants les autres aspects méthodologiques. L’approche collaborative d’OHDSI dans la recherche en réseau, où les chercheurs des partenaires de données participants travaillent ensemble aux côtés de ceux ayant des connaissances dans les domaines cliniques et des méthodologistes avec une expertise analytique, est une façon d’atteindre un niveau collectif de compréhension de la validité clinique des données à travers un réseau qui devrait servir de fondation pour renforcer la confiance dans les preuves générées à partir de ces données.
16.4 Résumé
- La validité clinique peut être établie en comprenant les caractéristiques de la source de données sous-jacente, en évaluant les caractéristiques de performance des cohortes dans une analyse, et en évaluant la généralisabilité de l’étude à la population cible d’intérêt.
- Une définition de la cohorte peut être évaluée sur la mesure dans laquelle les personnes identifiées dans la cohorte sur la base de la définition de la cohorte et des données observationnelles disponibles reflètent avec précision les personnes qui appartiennent véritablement au phénotype.
- La validation de la définition de la cohorte nécessite d’estimer plusieurs caractéristiques de performance, y compris la sensibilité, la spécificité et la valeur prédictive positive, pour résumer et permettre l’ajustement de l’erreur de mesure.
- L’adjudication clinique par vérification des dossiers sources et PheValuator représentent deux approches alternatives pour estimer la validation de la définition de la cohorte.
- Les études du réseau OHDSI fournissent un mécanisme pour examiner l’hétérogénéité des sources de données et étendre la généralisabilité des résultats pour améliorer la validité clinique des preuves du monde réel.