Chapitre 1 La Communauté OHDSI
Responsables du chapitre : Patrick Ryan & George Hripcsak
Se réunir est un début ; rester ensemble est un progrès ; travailler ensemble est une réussite. Henry Ford
1.1 Le Parcours des Données à l’Évidence
Partout dans le domaine de la santé, à travers le monde, au sein des centres médicaux universitaires et des pratiques privées, des agences de réglementation et des fabricants de produits médicaux, des compagnies d’assurances et des centres de politique, et au cœur de chaque interaction patient-fournisseur, il y a un défi commun : comment appliquer ce que nous avons appris du passé pour prendre de meilleures décisions pour l’avenir ?
Depuis plus d’une décennie, beaucoup ont plaidé pour la vision d’un système de santé apprenant, “conçu pour générer et appliquer les meilleures preuves pour les choix de soins collaboratifs de chaque patient et fournisseur ; pour stimuler le processus de découverte comme une croissance naturelle de l’administration des soins patients ; et pour assurer l’innovation, la qualité, la sécurité et la valeur dans les soins de santé”. (Olsen et al. 2007) Une composante clé de cette ambition repose sur la perspective excitante que les données au niveau des patients capturées au cours de la routine des soins cliniques puissent être analysées pour produire des preuves en conditions réelles, qui à leur tour pourraient être diffusées à travers le système de santé pour informer la pratique clinique. En 2007, le Comité Scientifique de l’Institut de Médecine sur la Médecine Fondée sur les Preuves a publié un rapport établissant un objectif selon lequel “D’ici l’année 2020, 90 % des décisions cliniques seront soutenues par des informations cliniques précises, opportunes et à jour, et refléteront les meilleures preuves disponibles.” (Olsen et al. 2007) Bien que des progrès considérables aient été réalisés sur plusieurs fronts, nous sommes encore loin de ces aspirations louables.
Pourquoi ? En partie, parce que le parcours des données au niveau des patients jusqu’à des preuves fiables est ardu. Il n’existe pas de chemin unique défini des données à l’évidence, et aucune carte unique qui puisse aider à naviguer en cours de route. En fait, il n’y a pas de notion unique de “données”, tout comme il n’y a pas de notion singulière de “preuve”.
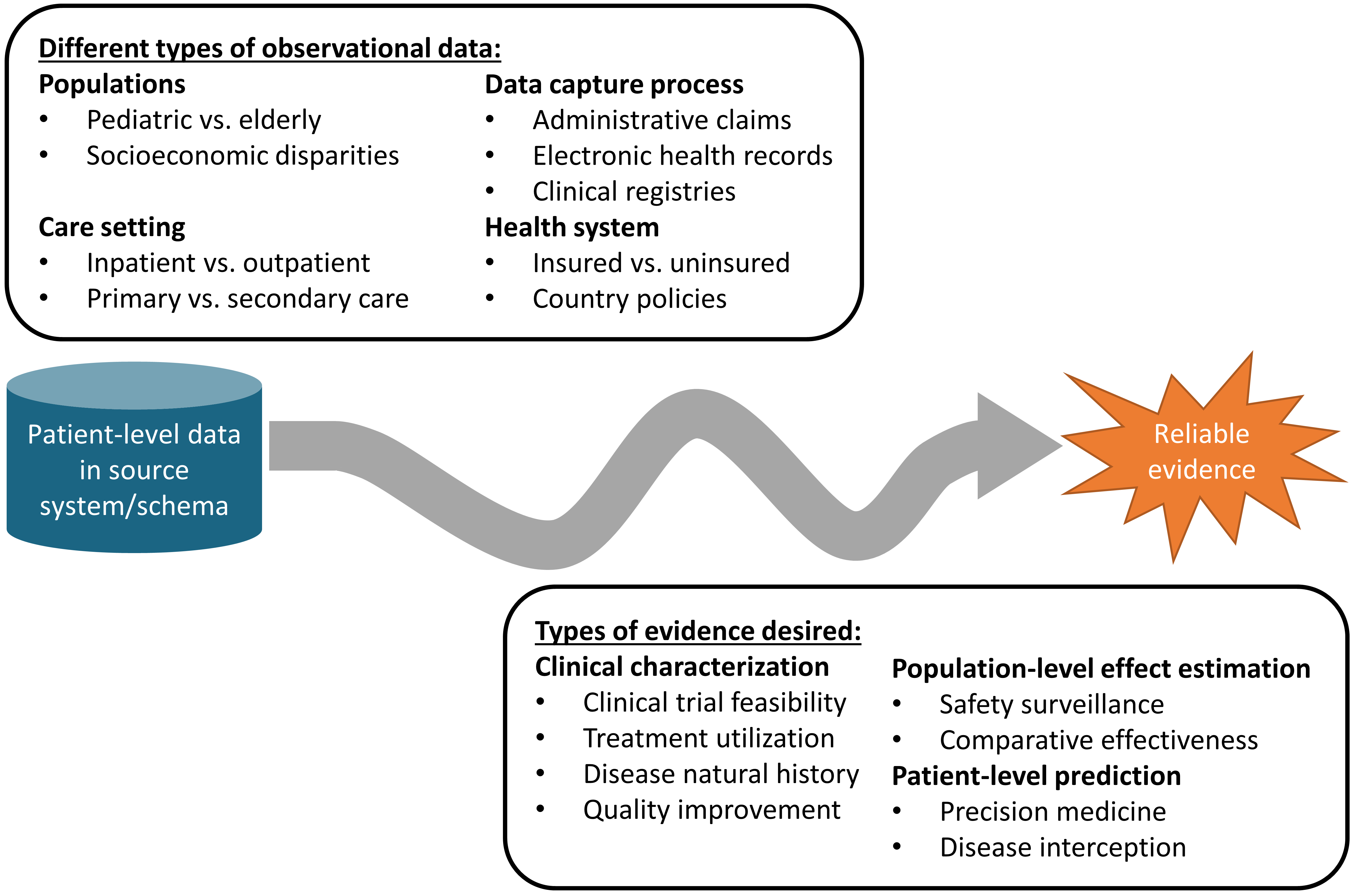
Figure 1.1: Le parcours des données à l’évidence
Il existe différents types de bases de données observationnelles qui capturent des données disparates au niveau des patients dans les systèmes sources. Ces bases de données sont aussi diverses que le système de santé lui-même, reflétant différentes populations, contextes de soins et processus de capture de données. Il existe également différents types de preuves qui pourraient être utiles pour informer la prise de décision, qui peuvent être classifiées par les cas d’utilisation analytiques de la caractérisation clinique, de l’estimation des effets au niveau de la population et de la prédiction au niveau des patients. Indépendamment de l’origine (données sources) et de la destination souhaitée (preuve), le défi est encore compliqué par l’étendue des compétences cliniques, scientifiques et techniques requises pour entreprendre le parcours. Cela nécessite une compréhension approfondie de l’informatique de la santé, y compris la provenance complète des données sources depuis l’interaction au point de soins entre un patient et un fournisseur à travers les systèmes administratifs et cliniques et dans le référentiel final, avec une appréciation des biais qui peuvent survenir dans le cadre des politiques de santé et des incitations comportementales associées aux processus de capture et de conservation des données. Il nécessite une maîtrise des principes épidémiologiques et des méthodes statistiques pour traduire une question clinique en un design d’étude observationnelle convenablement adapté pour produire une réponse pertinente. Il nécessite les compétences techniques pour implémenter et exécuter des algorithmes de science des données performants sur des ensembles de données contenant des millions de patients avec des milliards d’observations cliniques sur des années de suivi longitudinal. Il nécessite des connaissances cliniques pour synthétiser ce qui a été appris à travers un réseau de données observationnelles avec des preuves provenant d’autres sources d’information, et pour déterminer comment cette nouvelle connaissance devrait impacter la politique de santé et la pratique clinique. En conséquence, il est assez rare qu’un seul individu possède les compétences et les ressources requises pour réussir seul le chemin des données à l’évidence. Au lieu de cela, le parcours nécessite souvent une collaboration entre plusieurs individus et organisations pour s’assurer que les meilleures données disponibles sont analysées en utilisant les méthodes les plus appropriées pour produire les preuves que toutes les parties prenantes peuvent avoir confiance et utiliser dans leurs processus de prise de décision.
1.2 Observational Medical Outcomes Partnership
Un exemple notable de collaboration en recherche observationnelle a été le partenariat Observational Medical Outcomes Partnership (OMOP). OMOP était un partenariat public-privé, présidé par la Food and Drug Administration des États-Unis, administré par la Fondation des Instituts Nationaux de la Santé, et financé par un consortium de compagnies pharmaceutiques qui ont collaboré avec des chercheurs universitaires et des partenaires de données de santé pour établir un programme de recherche visant à faire progresser la science de la surveillance active de la sécurité des produits médicaux en utilisant des données de santé observationnelle. (Stang et al. 2010) OMOP a établi une structure de gouvernance multipartite et conçu une série d’expériences méthodologiques pour tester empiriquement la performance de conceptions épidémiologiques alternatives et de méthodes statistiques lorsqu’elles sont appliquées à un ensemble de bases de données de réclamations administratives et de dossiers de santé électroniques pour identifier les véritables associations de sécurité des médicaments et les distinguer des faux positifs.
Reconnaissant les défis techniques de la conduite de recherches à travers des bases de données observationnelles disparates dans un environnement centralisé et un réseau de recherche distribué, l’équipe a conçu le Modèle de Données Commun OMOP (CDM) comme un mécanisme pour standardiser la structure, le contenu et la sémantique des données observationnelles et pour permettre d’écrire du code d’analyse statistique une fois qui pourrait être réutilisé sur chaque site de données. (Overhage et al. 2012) Les expériences d’OMOP ont démontré qu’il était faisable d’établir un modèle de données commun et des vocabulaires standardisés qui pourraient accueillir différents types de données de divers contextes de soins et représentés par différents vocabulaires sources de manière à faciliter la collaboration interinstitutionnelle et les analyses performantes.
Dès le début, OMOP a adopté une approche de science ouverte, plaçant tous ses produits de travail, y compris les designs d’étude, les normes de données, le code d’analyse et les résultats empiriques, dans le domaine public pour promouvoir la transparence, renforcer la confiance dans la recherche que conduisait OMOP, mais aussi fournir une ressource communautaire qui pourrait être réutilisée pour avancer les objectifs de recherche des autres. Bien que le focus initial de l’OMOP ait été la sécurité des médicaments, le CDM OMOP a continuellement évolué pour soutenir un ensemble élargi de cas d’utilisation analytique, y compris l’efficacité comparative des interventions médicales et des politiques de système de santé.
Et bien qu’OMOP ait réussi à compléter ses expériences empiriques à grande échelle, (Ryan et al. 2012, 2013) développer des innovations méthodologiques, (Schuemie et al. 2014) et générer des connaissances utiles qui ont informé l’utilisation appropriée des données observationnelles pour la prise de décision en matière de sécurité, (Madigan et al. 2013; Madigan, Ryan, and Schuemie 2013) l’héritage de l’OMOP peut être plus mémorable pour son adoption précoce des principes de la science ouverte et son stimulus qui a motivé la formation de la communauté OHDSI.
Lorsque le projet OMOP était terminé, ayant rempli son mandat de mener des recherches méthodologiques pour informer les activités de surveillance active de la FDA, l’équipe a reconnu que la fin du parcours OMOP devait devenir le début d’un nouveau parcours ensemble. Malgré la recherche méthodologique de l’OMOP fournissant des indications tangibles sur les meilleures pratiques scientifiques qui pourraient améliorer de manière démontrable la qualité des preuves générées à partir des données observationnelles, l’adoption de ces meilleures pratiques était lente. Plusieurs obstacles ont été identifiés, y compris : 1) des préoccupations fondamentales concernant la qualité des données observationnelles qui étaient considérées comme une priorité plus élevée à résoudre avant les innovations analytiques ; 2) une compréhension conceptuelle insuffisante des problèmes méthodologiques et des solutions ; 3) une incapacité à implémenter indépendamment des solutions dans leur environnement local ; 4) une incertitude quant à savoir si ces approches étaient applicables à leurs problèmes cliniques d’intérêt. Le fil conducteur commun à chaque obstacle était le sentiment qu’une personne seule n’avait pas tout ce dont elle avait besoin pour mettre en œuvre un changement par elle-même, mais avec un soutien collaboratif, tous les problèmes pouvaient être surmontés. Mais plusieurs domaines de collaboration étaient nécessaires :
- Collaboration pour établir des normes de données communautaires ouvertes, des vocabulaires standardisés et des conventions ETL (Extract-Transform-Load) qui augmenteraient la confiance dans la qualité des données sous-jacentes et promouvraient la cohérence dans la structure, le contenu et la sémantique pour permettre des analyses standardisées.
- Collaboration pour la recherche méthodologique au-delà de la sécurité des médicaments pour établir des meilleures pratiques plus largement pour la caractérisation clinique, l’estimation des effets au niveau de la population et la prédiction au niveau des patients.
- Collaboration pour le développement analytique open-source, pour codifier les meilleures pratiques scientifiques prouvées par la recherche méthodologique et les rendre accessibles sous forme d’outils disponibles publiquement qui peuvent être facilement adoptés par la communauté de recherche.
- Collaboration pour des applications cliniques qui adressent des questions de santé importantes d’intérêt partagé à travers la communauté en naviguant collectivement le parcours des données à l’évidence.
De cette vision, OHDSI est née. ## OHDSI en tant que Collaboratif de Science Ouverte
Observational Health Data Sciences and Informatics (OHDSI, prononcé “Odyssey”) est une communauté de science ouverte qui vise à améliorer la santé en permettant à la communauté de générer de manière collaborative des preuves qui favorisent de meilleures décisions de santé et de meilleurs soins. (George Hripcsak et al. 2015) OHDSI mène des recherches méthodologiques pour établir les meilleures pratiques scientifiques pour l’utilisation appropriée des données de santé observationnelles, développe des logiciels d’analyse open-source qui codifient ces pratiques en solutions cohérentes, transparentes, et reproductibles, et applique ces outils et pratiques à des questions cliniques pour générer des preuves qui peuvent guider les politiques de santé et les soins aux patients.
1.2.1 Notre Mission
Améliorer la santé en permettant à une communauté de générer de manière collaborative des preuves qui favorisent de meilleures décisions de santé et de meilleurs soins.
1.2.2 Notre Vision
Un monde dans lequel la recherche observationnelle produit une compréhension globale de la santé et des maladies.
1.2.3 Nos Objectifs
Innovation: La recherche observationnelle est un domaine qui bénéficiera grandement d’une pensée disruptive. Nous recherchons activement et encourageons des approches méthodologiques novatrices dans notre travail.
Reproductibilité: Des preuves précises, reproductibles et bien calibrées sont nécessaires pour l’amélioration de la santé.
Communauté: Tout le monde est bienvenu pour participer activement à OHDSI, que vous soyez un patient, un professionnel de la santé, un chercheur, ou quelqu’un qui croit simplement en notre cause.
Collaboration: Nous travaillons collectivement pour donner la priorité et répondre aux besoins réels des participants de notre communauté.
Ouverture: Nous nous efforçons de rendre toutes les activités de notre communauté ouvertes et accessibles au public, y compris les méthodes, outils et preuves que nous générons.
Bienfaisance: Nous cherchons à protéger les droits des individus et des organisations au sein de notre communauté en tout temps.
1.3 Les Progrès de l’OHDSI
OHDSI a grandi depuis sa création en 2014 pour inclure plus de 2 500 collaborateurs sur ses forums en ligne, représentant divers partenaires, y compris le milieu universitaire, l’industrie des produits médicaux, les régulateurs, les gouvernements, les payeurs, les fournisseurs de technologie, les systèmes de santé, les cliniciens, les patients, et différents domaines tels que l’informatique, l’épidémiologie, les statistiques, l’informatique biomédicale, les politiques de santé et les sciences cliniques. Une liste des collaborateurs OHDSI auto-identifiés est disponible sur le site Web de l’OHDSI. 1 La carte des collaborateurs OHDSI (Figure 1.2) met en lumière l’étendue et la diversité de la communauté internationale.
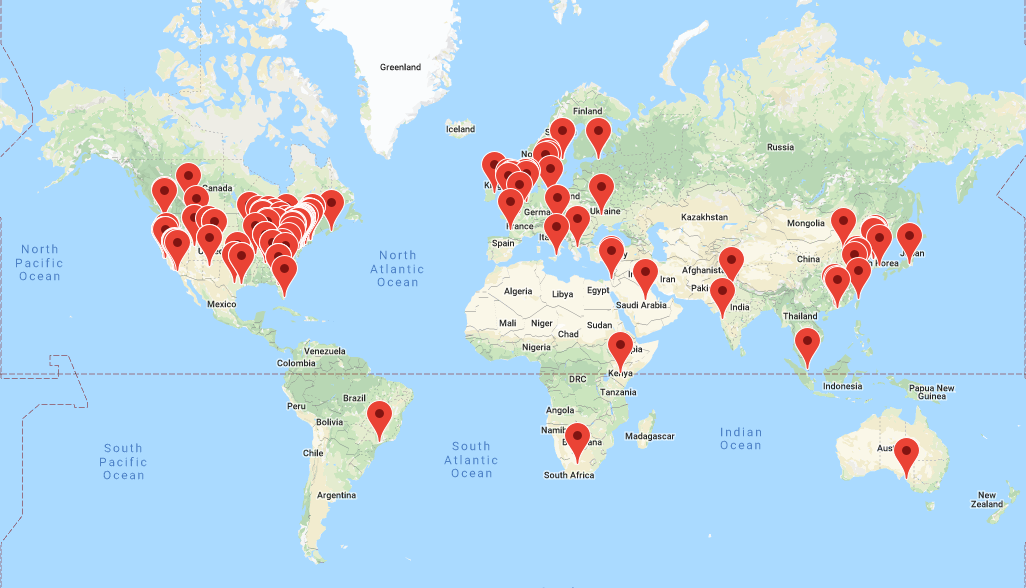
Figure 1.2: Carte des collaborateurs OHDSI en août 2019
En août 2019, OHDSI avait également établi un réseau de données de plus de 100 bases de données de soins de santé provenant de plus de 20 pays, capturant collectivement plus d’un milliard de dossiers de patients en utilisant une approche de réseau distribué appliquant une norme de données ouverte qu’elle maintient, le OMOP CDM. Un réseau distribué signifie que les données au niveau des patients ne sont pas obligées d’être partagées entre les individus ou les organisations. Au lieu de cela, les questions de recherche sont posées par les individus au sein de la communauté sous la forme d’un protocole d’étude accompagné d’un code d’analyse qui génère des preuves sous forme de statistiques sommaires agrégées, et seuls ces statistiques sommaires sont partagés entre les partenaires qui choisissent de collaborer à l’étude. Avec le réseau distribué OHDSI, chaque partenaire de données conserve une autonomie totale sur l’utilisation de leurs données au niveau des patients et continue d’observer les politiques de gouvernance des données au sein de leurs institutions respectives.
La communauté de développeurs OHDSI a créé une robuste bibliothèque d’outils analytiques open-source au-dessus de l’OMOP CDM pour soutenir trois cas d’utilisation : 1) la caractérisation clinique pour l’histoire naturelle des maladies, l’utilisation des traitements et l’amélioration de la qualité ; 2) l’estimation des effets au niveau de la population pour appliquer des méthodes d’inférence causale pour la surveillance de la sécurité des produits médicaux et l’efficacité comparative ; et 3) la prédiction au niveau des patients pour appliquer des algorithmes d’apprentissage automatique à la médecine de précision et à l’interception des maladies. Les développeurs d’OHDSI ont également développé des applications pour soutenir l’adoption de l’OMOP CDM, l’évaluation de la qualité des données et la facilitation des études de réseau OHDSI. Ces outils incluent des packages statistiques en arrière-plan construits en R et Python, et des applications web en front-end développées en HTML et Javascript. Tous les outils OHDSI sont open source et disponibles publiquement via Github. 2
L’approche communautaire de science ouverte de l’OHDSI, couplée avec ses outils open-source, a permis des avancées considérables dans la recherche observationnelle. L’une des premières analyses de réseau OHDSI a examiné les parcours de traitement à travers trois maladies chroniques : le diabète, la dépression et l’hypertension. Publiée dans les Actes de l’Académie Nationale des Sciences, c’était l’une des plus grandes études observationnelles jamais menées, avec des résultats provenant de 11 sources de données couvrant plus de 250 millions de patients, et a révélé de grandes différences géographiques et une hétérogénéité des patients dans les choix de traitement qui n’avaient jamais été observables auparavant. (George Hripcsak et al. 2016) OHDSI a développé de nouvelles méthodes statistiques de correction du biais de confusion (Tian, Schuemie, and Suchard 2018) et d’évaluation de la validité des preuves observationnelles pour l’inférence causale, (Schuemie, Hripcsak, et al. 2018) et a appliqué ces approches dans de multiples contextes, allant d’une question de surveillance de la sécurité individuelle dans l’épilepsie (Duke et al. 2017) à l’efficacité comparative des médicaments de deuxième ligne pour le diabète (Vashisht et al. 2018) jusqu’à une étude à grande échelle d’estimation des effets au niveau de la population pour la sécurité comparative des traitements de la dépression. (Schuemie, Ryan, et al. 2018) La communauté OHDSI a également établi un cadre pour comment appliquer de manière responsable les algorithmes d’apprentissage automatique aux données de santé observationnelles, (Reps et al. 2018) qui a été appliqué dans divers domaines thérapeutiques. (Johnston et al. 2019 ; Cepeda et al. 2018 ; Reps, Rijnbeek, and Ryan 2019)
1.4 Collaborer avec OHDSI
Puisque OHDSI est une communauté visant à favoriser la collaboration pour générer des preuves, qu’est-ce que cela signifie d’être un collaborateur OHDSI ? Si vous êtes quelqu’un qui croit en la mission de l’OHDSI et qui est intéressé à apporter une contribution à n’importe quelle étape du parcours allant des données aux preuves, alors OHDSI peut être la communauté pour vous. Les collaborateurs peuvent être des individus qui ont accès à des données au niveau des patients et souhaitent voir ces données utilisées pour générer des preuves. Les collaborateurs peuvent être des méthodologistes intéressés par l’établissement des meilleures pratiques scientifiques et l’évaluation d’approches alternatives. Les collaborateurs peuvent être des développeurs de logiciels intéressés à appliquer leurs compétences en programmation pour créer des outils utilisables par le reste de la communauté. Les collaborateurs peuvent être des chercheurs cliniques ayant des questions importantes de santé publique et cherchant à fournir des preuves à ces questions à la communauté de la santé au sens large par le biais de publications et d’autres formes de diffusion. Les collaborateurs peuvent être des individus ou des organisations qui croient en cette cause commune pour la santé publique et souhaitent fournir des ressources pour assurer que la communauté puisse se maintenir et continuer sa mission, y compris en organisant des activités communautaires et des sessions de formation à travers le monde. Peu importe votre discipline ou votre affiliation, OHDSI cherche à être un lieu où les individus peuvent travailler ensemble vers un objectif commun, chacun apportant sa contribution individuelle qui, collectivement, peut faire avancer les soins de santé. Si vous êtes intéressé à rejoindre le voyage, consultez le chapitre 2 (“Par Où Commencer”) pour savoir comment débuter.
1.5 Résumé
La mission de l’OHDSI est d’améliorer la santé en permettant à une communauté de générer de manière collaborative des preuves qui favorisent de meilleures décisions de santé et de meilleurs soins.
Notre vision est un monde dans lequel la recherche observationnelle produit une compréhension globale de la santé et des maladies, ce qui sera atteint par nos objectifs d’innovation, de reproductibilité, de communauté, de collaboration, d’ouverture et de bienfaisance.
Les collaborateurs de l’OHDSI sont concentrés sur les normes de données de la communauté ouverte, la recherche méthodologique, le développement d’analyses open-source, et les applications cliniques pour améliorer le parcours allant des données aux preuves.