Chapitre 9 SQL et R
Responsables de chapitre : Martijn Schuemie & Peter Rijnbeek
Le Common Data Model (CDM) est un modèle de base de données relationnelle (toutes les données sont représentées sous forme d’enregistrements dans des tables qui ont des champs), ce qui signifie que les données seront normalement stockées dans une base de données relationnelle utilisant une plateforme logicielle comme PostgreSQL, Oracle ou Microsoft SQL Server. Les divers outils OHDSI tels que ATLAS et la Methods Library fonctionnent en interrogeant la base de données en coulisse, mais nous pouvons également interroger directement la base de données nous-mêmes si nous disposons des droits d’accès appropriés. La principale raison de le faire est d’effectuer des analyses qui ne sont actuellement pas supportées par des outils existants. Cependant, interroger directement la base de données comporte également un risque accru de faire des erreurs, car les outils OHDSI sont souvent conçus pour aider à guider l’utilisateur vers une analyse appropriée des données. Les requêtes directes ne fournissent pas une telle guidance.
Le langage standard pour interroger les bases de données relationnelles est le SQL (Structured Query Language), qui peut être utilisé à la fois pour interroger la base de données ainsi que pour apporter des modifications aux données. Bien que les commandes de base en SQL soient en effet standard, c’est-à-dire les mêmes sur toutes les plateformes logicielles, chaque plateforme a son propre dialecte, avec des différences subtiles. Par exemple, pour récupérer les 10 premières lignes de la table PERSON sur SQL Server, on écrirait :
Tandis que la même requête sur PostgreSQL serait :
Dans OHDSI, nous aimerions être agnostiques vis-à-vis du dialecte spécifique qu’une plateforme utilise ; nous aimerions ‘parler’ le même langage SQL sur toutes les bases de données OHDSI. Pour cette raison, OHDSI a développé le package SqlRender, un package R qui peut traduire d’un dialecte standard vers n’importe lequel des dialectes supportés qui seront discutés plus tard dans ce chapitre. Ce dialecte standard - OHDSI SQL - est principalement un sous-ensemble du dialecte SQL Server SQL. Les exemples de déclarations SQL fournis tout au long de ce chapitre utiliseront tous l’OHDSI SQL.
Chaque plateforme de base de données dispose également de ses propres outils logiciels pour interroger la base de données en utilisant SQL. Dans OHDSI, nous avons développé le package DatabaseConnector, un package R qui peut se connecter à de nombreuses plateformes de base de données. DatabaseConnector sera également discuté plus tard dans ce chapitre.
Ainsi, bien que l’on puisse interroger une base de données conforme au CDM sans utiliser d’outils OHDSI, le chemin recommandé est d’utiliser les packages DatabaseConnector et SqlRender. Cela permet aux requêtes développées sur un site d’être utilisées sur n’importe quel autre site sans modification. R lui-même offre également immédiatement des fonctionnalités pour analyser davantage les données extraites de la base de données, telles que la réalisation d’analyses statistiques et la génération de graphiques (interactifs).
Dans ce chapitre, nous supposons que le lecteur a une compréhension de base de SQL. Nous passons d’abord en revue comment utiliser SqlRender et DatabaseConnector. Si le lecteur n’a pas l’intention d’utiliser ces packages, ces sections peuvent être omises. Dans la Section 9.3, nous discutons de la manière d’utiliser SQL (dans ce cas OHDSI SQL) pour interroger le CDM. La section suivante met en lumière comment utiliser le Vocabulaire Standardisé OHDSI lors de l’interrogation du CDM. Nous mettons en avant la QueryLibrary, une collection de requêtes couramment utilisées contre le CDM qui est publiquement disponible. Nous clôturons ce chapitre avec une étude exemple estimant les taux d’incidence, et implémentons cette étude en utilisant SqlRender et DatabaseConnector.
9.1 SqlRender
Le package SqlRender est disponible sur CRAN (le Comprehensive R Archive Network), et peut donc être installé en utilisant :
SqlRender prend en charge une large gamme de plateformes techniques, y compris les systèmes de bases de données traditionnels (PostgreSQL, Microsoft SQL Server, SQLite et Oracle), les entrepôts de données parallèles (Microsoft APS, IBM Netezza et Amazon Redshift), ainsi que les plateformes Big Data (Hadoop via Impala et Google BigQuery). Le package R est fourni avec un manuel et une vignette qui explore toutes les fonctionnalités. Ici, nous décrivons certaines des principales fonctionnalités.
9.1.1 Paramétrage SQL
Une des fonctions du package est de prendre en charge la paramétrisation du SQL. Souvent, de petites variations du SQL doivent être générées en fonction de certains paramètres. SqlRender offre une syntaxe de balisage simple dans le code SQL pour permettre la paramétrisation. Le rendu du SQL basé sur les valeurs des paramètres est effectué à l’aide de la fonction render().
Substitution des Valeurs de Paramètres
Le caractère @ peut être utilisé pour indiquer les noms des paramètres à échanger contre les valeurs réelles des paramètres lors du rendu. Dans l’exemple suivant, une variable appelée a est mentionnée dans le SQL. Dans l’appel à la fonction render, la valeur de ce paramètre est définie :
## [1] "SELECT * FROM concept WHERE concept_id = 123;"Notez que, contrairement à la paramétrisation offerte par la plupart des systèmes de gestion de bases de données, il est tout aussi facile de paramétrer les noms de tables ou de champs que les valeurs :
## [1] "SELECT * FROM observation WHERE person_id = 123;"Les valeurs des paramètres peuvent être des nombres, des chaînes, des booléens ainsi que des vecteurs, qui sont convertis en listes séparées par des virgules :
## [1] "SELECT * FROM concept WHERE concept_id IN (123,234,345);"If-Then-Else
Parfois, des blocs de codes doivent être activés ou désactivés en fonction des valeurs d’un ou plusieurs paramètres. Cela se fait en utilisant la syntaxe {Condition} ? {if true} : {if false}. Si la condition évalue à true ou 1, le bloc if true est utilisé, sinon le bloc if false est affiché (s’il est présent).
## [1] "SELECT * FROM cohort "## [1] "SELECT * FROM cohort WHERE subject_id = 1"Les comparaisons simples sont également prises en charge :
## [1] "SELECT * FROM cohort WHERE subject_id = 1;"## [1] "SELECT * FROM cohort ;"Ainsi que l’opérateur IN :
## [1] "SELECT * FROM cohort WHERE subject_id = 1;"9.1.2 Traduction vers d’Autres Dialectes SQL
Une autre fonction du package SqlRender est de traduire du SQL OHDSI vers d’autres dialectes SQL. Par exemple :
## [1] "SELECT * FROM person LIMIT 10;"
## attr(,"sqlDialect")
## [1] "postgresql"Le paramètre targetDialect peut avoir les valeurs suivantes : “oracle”, “postgresql”, “pdw”, “redshift”, “impala”, “netezza”, “bigquery”, “sqlite” et “sql server”.
Il existe des limites quant à ce que les fonctions et constructions SQL peuvent être traduites correctement, à la fois parce qu’un ensemble limité de règles de traduction ont été implémentées dans le package, mais aussi parce que certaines fonctionnalités SQL n’ont pas d’équivalent dans tous les dialectes. Ceci est la raison principale pour laquelle le SQL OHDSI a été développé en tant que nouveau dialecte SQL à part entière. Cependant, chaque fois que possible, nous avons gardé la syntaxe SQL Server pour éviter de réinventer la roue.
Malgré nos meilleurs efforts, il y a beaucoup de considérations à prendre en compte lors de l’écriture de SQL OHDSI qui s’exécutera sans erreur sur toutes les plateformes prises en charge. Ce qui suit discute de ces considérations en détail.
Fonctions et Structures Prises en Charge par Translate
Ces fonctions SQL Server ont été testées et se sont révélées être correctement traduites dans les différents dialectes :
Table : (#tab:sqlFunctions) Fonctions prises en charge par translate.
| Fonction | Fonction | Fonction |
|---|---|---|
| ABS | EXP | RAND |
| ACOS | FLOOR | RANK |
| ASIN | GETDATE | RIGHT |
| ATAN | HASHBYTES* | ROUND |
| AVG | ISNULL | ROW_NUMBER |
| CAST | ISNUMERIC | RTRIM |
| CEILING | LEFT | SIN |
| CHARINDEX | LEN | SQRT |
| CONCAT | LOG | SQUARE |
| COS | LOG10 | STDEV |
| COUNT | LOWER | SUM |
| COUNT_BIG | LTRIM | TAN |
| DATEADD | MAX | UPPER |
| DATEDIFF | MIN | VAR |
| DATEFROMPARTS | MONTH | YEAR |
| DATETIMEFROMPARTS | NEWID | |
| DAY | PI | |
| EOMONTH | POWER |
* Nécessite des privilèges spéciaux sur Oracle. N’a pas d’équivalent sur SQLite.
De même, de nombreuses structures syntaxiques SQL sont prises en charge. Voici une liste non exhaustive d’expressions dont nous savons qu’elles se traduisent bien :
-- Sélections simples :
SELECT * FROM table;
-- Sélections avec jointures :
SELECT * FROM table_1 INNER JOIN table_2 ON a = b;
-- Requêtes imbriquées :
SELECT * FROM (SELECT * FROM table_1) tmp WHERE a = b;
-- Limitation aux lignes du haut :
SELECT TOP 10 * FROM table;
-- Sélection dans une nouvelle table :
SELECT * INTO new_table FROM table;
-- Création de tables :
CREATE TABLE table (field INT);
-- Insertion de valeurs littérales :
INSERT INTO other_table (field_1) VALUES (1);
-- Insertion à partir de SELECT :
INSERT INTO other_table (field_1) SELECT value FROM table;
-- Commandes de suppression simples :
DROP TABLE table;
-- Suppression de table si elle existe :
IF OBJECT_ID('ACHILLES_analysis', 'U') IS NOT NULL
DROP TABLE ACHILLES_analysis;
-- Suppression de table temporaire si elle existe :
IF OBJECT_ID('tempdb..#cohorts', 'U') IS NOT NULL
DROP TABLE #cohorts;
-- Expressions de table communes :
WITH cte AS (SELECT * FROM table) SELECT * FROM cte;
-- Clauses OVER :
SELECT ROW_NUMBER() OVER (PARTITION BY a ORDER BY b)
AS "Row Number" FROM table;
-- Clauses CASE WHEN :
SELECT CASE WHEN a=1 THEN a ELSE 0 END AS value FROM table;
-- UNIONS :
SELECT * FROM a UNION SELECT * FROM b;
-- INTERSECTIONS :
SELECT * FROM a INTERSECT SELECT * FROM b;
-- EXCEPT :
SELECT * FROM a EXCEPT SELECT * FROM b;Concaténation de Chaînes
La concaténation de chaînes est un domaine où SQL Server est moins spécifique que d’autres dialectes. Dans SQL Server, on écrirait SELECT first_name + ' ' + last_name AS full_name FROM table, mais cela devrait être SELECT first_name || ' ' || last_name AS full_name FROM table dans PostgreSQL et Oracle. SqlRender tente de deviner quand les valeurs concaténées sont des chaînes. Dans l’exemple ci-dessus, parce que nous avons une chaîne explicite (l’espace entouré de guillemets simples), la traduction sera correcte. Cependant, si la requête avait été SELECT first_name + last_name AS full_name FROM table, SqlRender n’aurait pas eu d’indice que les deux champs étaient des chaînes, et laisserait incorrectement le signe plus. Un autre indice qu’une valeur est une chaîne est une conversion explicite en VARCHAR, donc SELECT last_name + CAST(age AS VARCHAR(3)) AS full_name FROM table serait également traduit correctement. Pour éviter toute ambiguïté, il est probablement préférable d’utiliser la fonction CONCAT() pour concaténer deux ou plusieurs chaînes.
Alias de Table et le Mot-Clé AS
De nombreux dialectes SQL permettent l’utilisation du mot-clé AS lors de la définition d’un alias de table, mais fonctionneront également bien sans le mot-clé. Par exemple, ces deux instructions SQL sont correctes pour SQL Server, PostgreSQL, Redshift, etc. :
-- Utilisation du mot-clé AS
SELECT *
FROM my_table AS table_1
INNER JOIN (
SELECT * FROM other_table
) AS table_2
ON table_1.person_id = table_2.person_id;
-- Non-utilisation du mot-clé AS
SELECT *
FROM my_table table_1
INNER JOIN (
SELECT * FROM other_table
) table_2
ON table_1.person_id = table_2.person_id;Cependant, Oracle renverra une erreur lorsque le mot-clé AS est utilisé. Dans l’exemple ci-dessus, la première requête échouera. Il est donc recommandé de ne pas utiliser le mot-clé AS lors de la création d’alias de tables. (Note : nous ne pouvons pas faire en sorte que SqlRender gère cela, car il ne peut pas facilement distinguer entre les alias de tables où Oracle n’autorise pas l’utilisation de AS, et les alias de champs, où Oracle nécessite l’utilisation de AS.)
Tables Temporaires
Les tables temporaires peuvent être très utiles pour stocker des résultats intermédiaires, et lorsqu’elles sont utilisées correctement, elles peuvent améliorer considérablement les performances des requêtes. Sur la plupart des plateformes de bases de données, les tables temporaires présentent de très belles propriétés : elles ne sont visibles que par l’utilisateur actuel, sont automatiquement supprimées lorsque la session se termine et peuvent être créées même lorsque l’utilisateur n’a pas d’accès en écriture. Malheureusement, dans Oracle, les tables temporaires sont essentiellement des tables permanentes, avec la seule différence que les données à l’intérieur de la table ne sont visibles que par l’utilisateur actuel. C’est pourquoi, dans Oracle, SqlRender essaiera d’émuler les tables temporaires en
- Ajoutant une chaîne aléatoire au nom de la table afin que les tables de différents utilisateurs ne soient pas en conflit.
- Permettant à l’utilisateur de spécifier le schéma où les tables temporaires seront créées.
Par exemple :
sql <- "SELECT * FROM #children;"
translate(sql, targetDialect = "oracle", oracleTempSchema = "temp_schema")## Warning: The 'oracleTempSchema' argument is deprecated. Use 'tempEmulationSchema' instead.
## This warning is displayed once every 8 hours.## [1] "SELECT * FROM temp_schema.dg6jad1ochildren ;"
## attr(,"sqlDialect")
## [1] "oracle"Notez que l’utilisateur devra avoir des privilèges d’écriture sur temp_schema.
Notez également que, parce qu’Oracle a une limite de 30 caractères pour les noms de table, les noms de tables temporaires ne sont autorisés à avoir que 22 caractères maximum, car sinon le nom deviendra trop long après l’ajout de l’ID de session.
De plus, rappelez-vous que les tables temporaires ne sont pas automatiquement supprimées sur Oracle, vous devrez donc explicitement TRUNCATE et DROP toutes les tables temporaires une fois que vous avez terminé avec elles pour éviter que des tables orphelines ne s’accumulent dans le schéma temporaire Oracle.
Conversions Implicites
L’un des rares points où SQL Server est moins explicite que d’autres dialectes est qu’il permet les conversions implicites. Par exemple, ce code fonctionnera sur SQL Server :
Même si txt est un champ VARCHAR et que nous le comparons à un entier, SQL Server convertira automatiquement l’une des deux au type correct pour permettre la comparaison. En revanche, d’autres dialectes comme PostgreSQL renverront une erreur lorsqu’ils essaieront de comparer un VARCHAR avec un INT.
Vous devez donc toujours rendre les conversions explicites. Dans l’exemple ci-dessus, la dernière instruction doit être remplacée par soit
ou
Sensibilité à la Casse dans les Comparaisons de Chaînes
Certaines plateformes SGBD comme SQL Server effectuent toujours des comparaisons de chaînes de manière insensible à la casse, tandis que d’autres comme PostgreSQL sont toujours sensibles à la casse. Il est donc recommandé de toujours supposer des comparaisons sensibles à la casse, et de rendre explicitement les comparaisons insensibles à la casse lorsqu’on n’est pas sûr de la casse. Par exemple, au lieu de
il est préférable d’utiliser
Schémas et Bases de Données
Dans SQL Server, les tables sont situées dans un schéma, et les schémas résident dans une base de données. Par exemple, cdm_data.dbo.person fait référence à la table person dans le schéma dbo dans la base de données cdm_data. Dans d’autres dialectes, bien qu’une hiérarchie similaire existe souvent, elle est utilisée de manière très différente. Dans SQL Server, il y a généralement un schéma par base de données (souvent appelé dbo), et les utilisateurs peuvent facilement utiliser des données dans différentes bases de données. Sur d’autres plateformes, par exemple dans PostgreSQL, il n’est pas possible d’utiliser des données entre différentes bases de données dans une seule session, mais il y a souvent de nombreux schémas dans une base de données. Dans PostgreSQL, on pourrait dire que l’équivalent de la base de données de SQL Server est le schéma.
Nous recommandons donc de concaténer la base de données et le schéma de SQL Server en un seul paramètre, que nous appelons généralement @databaseSchema. Par exemple, nous pourrions avoir le SQL paramétré
où sur SQL Server nous pouvons inclure à la fois les noms de base de données et de schéma dans la valeur : databaseSchema = "cdm_data.dbo". Sur d’autres plateformes, nous pouvons utiliser le même code, mais maintenant seulement spécifier le schéma comme valeur du paramètre : databaseSchema = "cdm_data".
La seule situation où cela échouera est la commande USE, puisque USE cdm_data.dbo; renverra une erreur. Il est donc préférable de ne pas utiliser la commande USE, mais de toujours spécifier la base de données / le schéma où une table est située.
Débogage de SQL Paramétré
Le débogage de SQL paramétré peut être un peu compliqué. Seul le SQL rendu peut être testé contre un serveur de base de données, mais les modifications du code doivent être effectuées dans le SQL paramétré (pré-rendu).
Une application Shiny est incluse dans le package SqlRender pour éditer de façon interactive le SQL source et générer du SQL rendu et traduit. L’application peut être lancée en utilisant :
Cela ouvrira le navigateur par défaut avec l’application montrée sur la Figure 9.1. L’application est également disponible publiquement sur le web.51
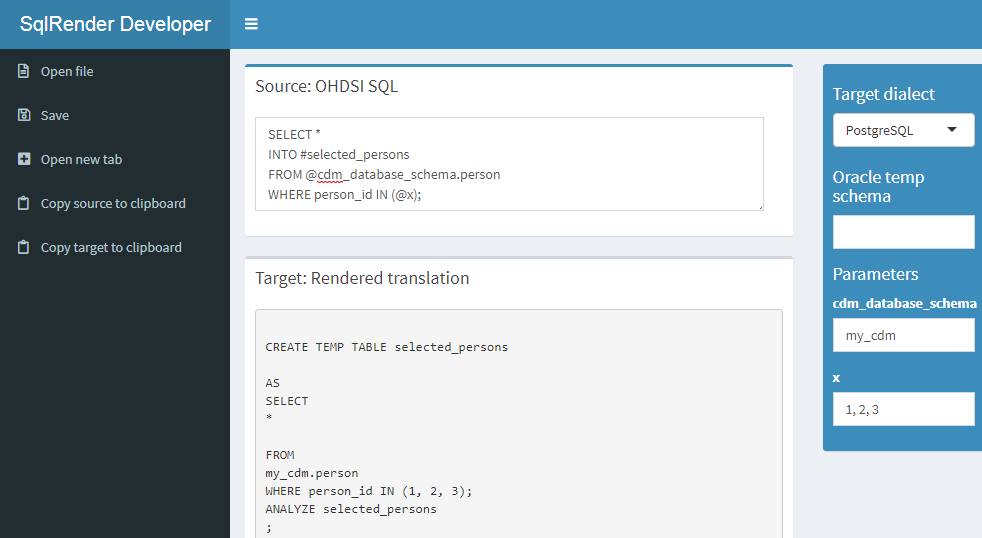
Figure 9.1: The SqlDeveloper Shiny app.
Dans l’application, vous pouvez entrer du SQL OHDSI, sélectionner le dialecte cible ainsi que fournir des valeurs pour les paramètres qui apparaissent dans votre SQL, et la traduction apparaîtra automatiquement en bas.
9.2 DatabaseConnector
DatabaseConnector est un package R pour se connecter à diverses plateformes de bases de données en utilisant les pilotes JDBC de Java. Le package DatabaseConnector est disponible sur CRAN (le Comprehensive R Archive Network), et peut donc être installé en utilisant :
DatabaseConnector prend en charge un large éventail de plateformes techniques, y compris les systèmes de bases de données traditionnels (PostgreSQL, Microsoft SQL Server, SQLite, et Oracle), les entrepôts de données parallèles (Microsoft APS, IBM Netezza, et Amazon), ainsi que les plateformes Big Data (Hadoop via Impala, et Google BigQuery). Le package contient déjà la plupart des pilotes, mais en raison de raisons de licence, les pilotes pour BigQuery, Netezza et Impala ne sont pas inclus et doivent être obtenus par l’utilisateur. Tapez ?jdbcDrivers pour des instructions sur la manière de télécharger ces pilotes. Une fois téléchargés, vous pouvez utiliser l’argument pathToDriver des fonctions connect, dbConnect, et createConnectionDetails.
9.2.1 Création d’une Connexion
Pour se connecter à une base de données, un certain nombre de détails doivent être spécifiés, tels que la plateforme de la base de données, l’emplacement du serveur, le nom d’utilisateur, et le mot de passe. Nous pouvons appeler la fonction connect et spécifier ces détails directement :
conn <- connect(dbms = "postgresql",
server = "localhost/postgres",
user = "joe",
password = "secret",
schema = "cdm")## Connecting using PostgreSQL driverVoir ?connect pour des informations sur les détails requis pour chaque plateforme. N’oubliez pas de fermer toute connexion après utilisation :
Notez que, au lieu de fournir le nom du serveur, il est également possible de fournir la chaîne de connexion JDBC si cela est plus pratique :
connString <- "jdbc:postgresql://localhost:5432/postgres"
conn <- connect(dbms = "postgresql",
connectionString = connString,
user = "joe",
password = "secret",
schema = "cdm")## Connecting using PostgreSQL driverParfois, nous pouvons d’abord spécifier les détails de la connexion et reporter la connexion à plus tard. Cela peut être pratique, par exemple, lorsque la connexion est établie à l’intérieur d’une fonction et que les détails doivent être passés en argument. Nous pouvons utiliser la fonction createConnectionDetails à cette fin :
details <- createConnectionDetails(dbms = "postgresql",
server = "localhost/postgres",
user = "joe",
password = "secret",
schema = "cdm")
conn <- connect(details)## Connecting using PostgreSQL driver9.2.2 Interroger
Les principales fonctions pour interroger une base de données sont les fonctions querySql et executeSql. La différence entre ces fonctions est que querySql s’attend à ce que des données soient retournées par la base de données et ne peut gérer qu’une seule instruction SQL à la fois. En revanche, executeSql ne s’attend pas à ce que des données soient retournées et accepte plusieurs instructions SQL dans une seule chaîne SQL.
Quelques exemples :
## person_id gender_concept_id year_of_birth
## 1 1 8507 1975
## 2 2 8507 1976
## 3 3 8507 1977Les deux fonctions fournissent des rapports d’erreurs détaillés : Lorsqu’une erreur est générée par le serveur, le message d’erreur et le morceau de SQL en cause sont écrits dans un fichier texte pour permettre un meilleur débogage. La fonction executeSql affiche également par défaut une barre de progression, indiquant le pourcentage des instructions SQL qui ont été exécutées. Si ces attributs ne sont pas souhaités, le package offre également les fonctions lowLevelQuerySql et lowLevelExecuteSql.
9.2.3 Interroger en Utilisant les Objets Ffdf
Parfois, les données à récupérer de la base de données sont trop grandes pour tenir en mémoire. Comme mentionné dans la Section 8.4.2, dans ce cas, nous pouvons utiliser le package ff pour stocker les objets de données R sur le disque et les utiliser comme s’ils étaient disponibles en mémoire. DatabaseConnector peut télécharger des données directement dans des objets ffdf :
x est maintenant un objet ffdf.
9.2.4 Interroger Différentes Plateformes en Utilisant le Même SQL
Les fonctions de commodité suivantes sont disponibles et appellent d’abord les fonctions render et translate du package SqlRender : renderTranslateExecuteSql, renderTranslateQuerySql, renderTranslateQuerySql.ffdf. Par exemple :
x <- renderTranslateQuerySql(conn,
sql = "SELECT TOP 10 * FROM @schema.person",
schema = "cdm_synpuf")Notez que la syntaxe spécifique à SQL Server ‘TOP 10’ sera traduite par exemple en ‘LIMIT 10’ sur PostgreSQL, et que le paramètre SQL @schema sera instancié avec la valeur fournie ‘cdm_synpuf’.
9.2.5 Insérer des Tables
Bien qu’il soit également possible d’insérer des données dans la base de données en envoyant des instructions SQL en utilisant la fonction executeSql, il est souvent plus pratique et plus rapide (grâce à certaines optimisations) d’utiliser la fonction insertTable :
Dans cet exemple, nous téléchargeons la dataframe mtcars dans une table appelée ‘mtcars’ sur le serveur, qui sera automatiquement créée.
9.3 Interroger le CDM
Dans les exemples suivants, nous utilisons SQL d’OHDSI pour interroger une base de données qui adhère au CDM. Ces requêtes utilisent @cdm pour désigner le schéma de base de données où les données du CDM peuvent être trouvées.
Nous pouvons commencer par simplement interroger combien de personnes sont dans la base de données :
| PERSON_COUNT |
|---|
| 26299001 |
Ou peut-être que nous sommes intéressés par la longueur moyenne d’une période d’observation :
SELECT AVG(DATEDIFF(DAY,
observation_period_start_date,
observation_period_end_date) / 365.25) AS num_years
FROM @cdm.observation_period;| NUM_YEARS |
|---|
| 1.980803 |
Nous pouvons joindre des tables pour produire des statistiques supplémentaires. Une jointure combine des champs de plusieurs tables, en exigeant généralement que des champs spécifiques des tables aient la même valeur. Par exemple, ici nous joignons la table PERSON avec la table OBSERVATION_PERIOD sur les champs PERSON_ID dans les deux tables. En d’autres termes, le résultat de la jointure est un nouvel ensemble de type table qui contient tous les champs des deux tables, mais dans toutes les lignes, les champs PERSON_ID des deux tables doivent avoir la même valeur. Nous pouvons maintenant, par exemple, calculer l’âge maximum à la fin de l’observation en utilisant le champ OBSERVATION_PERIOD_END_DATE de la table OBSERVATION_PERIOD avec le champ year_of_birth de la table PERSON :
SELECT MAX(YEAR(observation_period_end_date) -
year_of_birth) AS max_age
FROM @cdm.person
INNER JOIN @cdm.observation_period
ON person.person_id = observation_period.person_id;| MAX_AGE |
|---|
| 90 |
Une requête beaucoup plus compliquée est nécessaire pour déterminer la distribution de l’âge au début de l’observation. Dans cette requête, nous joignons d’abord la table PERSON à la table OBSERVATION_PERIOD pour calculer l’âge au début de l’observation. Nous calculons également l’ordre pour cet ensemble joint en fonction de l’âge, et le stockons sous order_nr. Parce que nous voulons utiliser le résultat de cette jointure plusieurs fois, nous le définissons comme une expression de table commune (CTE) (définie en utilisant WITH ... AS) que nous appelons “ages,” ce qui signifie que nous pouvons référencer ages comme s’il s’agissait d’une table existante. Nous comptons le nombre de lignes dans ages pour produire “n,” puis pour chaque quantile trouvons l’âge minimum où order_nr est inférieur à la fraction multipliée par n. Par exemple, pour trouver la médiane, nous utilisons l’âge minimum où \(order\_nr < .50 * n\). Les âges minimum et maximum sont calculés séparément :
WITH ages
AS (
SELECT age,
ROW_NUMBER() OVER (
ORDER BY age
) order_nr
FROM (
SELECT YEAR(observation_period_start_date) - year_of_birth AS age
FROM @cdm.person
INNER JOIN @cdm.observation_period
ON person.person_id = observation_period.person_id
) age_computed
)
SELECT MIN(age) AS min_age,
MIN(CASE
WHEN order_nr < .25 * n
THEN 9999
ELSE age
END) AS q25_age,
MIN(CASE
WHEN order_nr < .50 * n
THEN 9999
ELSE age
END) AS median_age,
MIN(CASE
WHEN order_nr < .75 * n
THEN 9999
ELSE age
END) AS q75_age,
MAX(age) AS max_age
FROM ages
CROSS JOIN (
SELECT COUNT(*) AS n
FROM ages
) population_size;| MIN_AGE | Q25_AGE | MEDIAN_AGE | Q75_AGE | MAX_AGE |
|---|---|---|---|---|
| 0 | 6 | 17 | 34 | 90 |
Des calculs plus complexes peuvent également être effectués en R au lieu d’utiliser SQL. Par exemple, nous pouvons obtenir la même réponse en utilisant ce code R :
sql <- "SELECT YEAR(observation_period_start_date) -
year_of_birth AS age
FROM @cdm.person
INNER JOIN @cdm.observation_period
ON person.person_id = observation_period.person_id;"
age <- renderTranslateQuerySql(conn, sql, cdm = "cdm")
quantile(age[, 1], c(0, 0.25, 0.5, 0.75, 1))## 0% 25% 50% 75% 100%
## 0 6 17 34 90Ici, nous calculons l’âge sur le serveur, téléchargeons tous les âges, puis calculons la distribution des âges. Cependant, cela nécessite le téléchargement de millions de lignes de données depuis le serveur de base de données, et n’est donc pas très efficace. Vous devrez décider au cas par cas si un calcul est mieux effectué en SQL ou en R.
Les requêtes peuvent utiliser les valeurs source dans le CDM. Par exemple, nous pouvons récupérer les 10 codes sources de conditions les plus fréquents en utilisant :
SELECT TOP 10 condition_source_value,
COUNT(*) AS code_count
FROM @cdm.condition_occurrence
GROUP BY condition_source_value
ORDER BY -COUNT(*);| CONDITION_SOURCE_VALUE | CODE_COUNT |
|---|---|
| 4019 | 49094668 |
| 25000 | 36149139 |
| 78099 | 28908399 |
| 319 | 25798284 |
| 31401 | 22547122 |
| 317 | 22453999 |
| 311 | 19626574 |
| 496 | 19570098 |
| I10 | 19453451 |
| 3180 | 18973883 |
Ici, nous avons regroupé les enregistrements de la table CONDITION_OCCURRENCE par les valeurs du champ CONDITION_SOURCE_VALUE, et avons compté le nombre d’enregistrements dans chaque groupe. Nous récupérons le CONDITION_SOURCE_VALUE et le compte, et les trions par ordre décroissant du compte.
9.4 Utiliser le Vocabulaire Lors de l’Interrogation
De nombreuses opérations nécessitent que le vocabulaire soit utile. Les tables de Vocabulaire font partie du CDM, et sont donc disponibles via des requêtes SQL. Ici, nous montrons comment les requêtes contre le Vocabulaire peuvent être combinées avec des requêtes contre le CDM. De nombreux champs dans le CDM contiennent des identifiants de concept qui peuvent être résolus en utilisant la table CONCEPT. Par exemple, nous voudrions peut-être compter le nombre de personnes dans la base de données stratifiées par sexe, et il serait pratique de résoudre le champ GENDER_CONCEPT_ID en un nom de concept :
SELECT COUNT(*) AS subject_count,
concept_name
FROM @cdm.person
INNER JOIN @cdm.concept
ON person.gender_concept_id = concept.concept_id
GROUP BY concept_name;| SUBJECT_COUNT | CONCEPT_NAME |
|---|---|
| 14927548 | FEMALE |
| 11371453 | MALE |
Une caractéristique très puissante du Vocabulaire est sa hiérarchie. Une requête très courante recherche un concept spécifique et tous ses descendants. Par exemple, imaginons que nous souhaitons compter le nombre de prescriptions contenant l’ingrédient ibuprofène :
SELECT COUNT(*) AS prescription_count
FROM @cdm.drug_exposure
INNER JOIN @cdm.concept_ancestor
ON drug_concept_id = descendant_concept_id
INNER JOIN @cdm.concept ingredient
ON ancestor_concept_id = ingredient.concept_id
WHERE LOWER(ingredient.concept_name) = 'ibuprofen'
AND ingredient.concept_class_id = 'Ingredient'
AND ingredient.standard_concept = 'S';| PRESCRIPTION_COUNT |
|---|
| 26871214 |
9.5 QueryLibrary
QueryLibrary est une bibliothèque de requêtes SQL couramment utilisées pour le CDM. Elle est disponible sous forme d’application en ligne52 montrée dans la Figure 9.2, et sous forme de package R.53
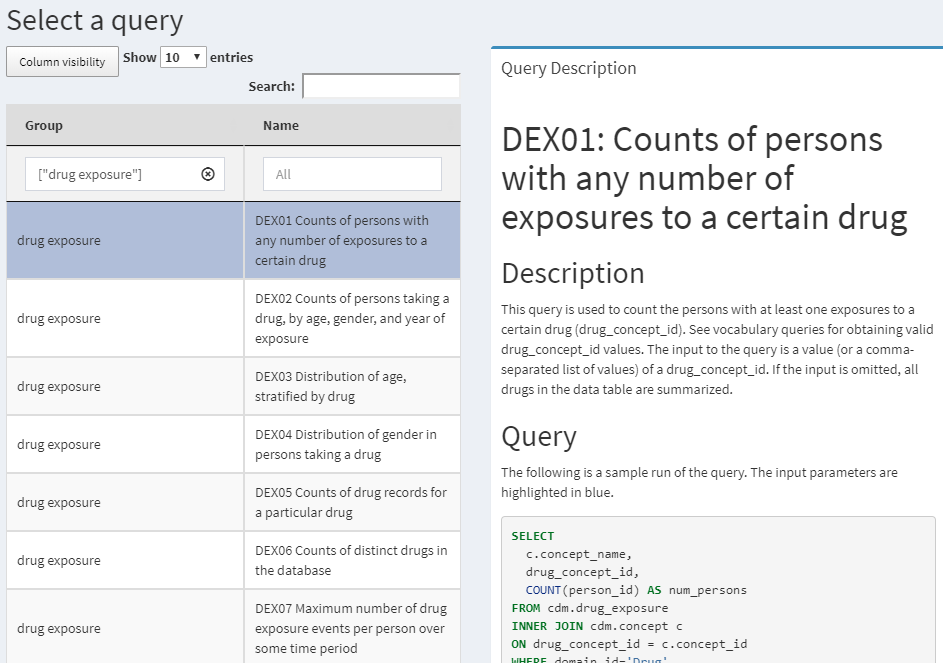
Figure 9.2: QueryLibrary : une bibliothèque de requêtes SQL contre le CDM.
L’objectif de la bibliothèque est d’aider les nouveaux utilisateurs à apprendre à interroger le CDM. Les requêtes dans la bibliothèque ont été examinées et approuvées par la communauté OHDSI. La bibliothèque de requêtes est principalement destinée à des fins de formation, mais elle est également une ressource précieuse pour les utilisateurs expérimentés.
La QueryLibrary utilise SqlRender pour produire les requêtes dans le dialecte SQL de votre choix. Les utilisateurs peuvent également spécifier le schéma de la base de données CDM, le schéma de la base de données de vocabulaire (s’ils sont séparés) et le schéma temporaire d’Oracle (si nécessaire), de sorte que les requêtes seront automatiquement rendues avec ces paramètres.
9.6 Concevoir une Étude Simple
9.6.1 Définition du Problème
L’angio-œdème est un effet secondaire bien connu des inhibiteurs de l’ECA (IECA). Slater et al. (1988) estime que le taux d’incidence de l’angio-œdème dans la première semaine de traitement par IECA est d’un cas pour 3 000 patients par semaine. Ici, nous cherchons à reproduire cette constatation, et à stratifier par âge et sexe. Pour simplifier, nous nous concentrons sur un IECA : le lisinopril. Nous répondons donc à la question
Quel est le taux d’angio-œdème dans la première semaine suivant l’initiation du traitement par lisinopril, stratifié par âge et sexe ?
9.6.2 Exposition
Nous définirons l’exposition comme la première exposition au lisinopril. Par « première », nous entendons qu’aucune exposition antérieure au lisinopril n’est présente. Nous exigeons 365 jours de temps d’observation continue avant la première exposition.
9.7 Implémenter l’Étude en Utilisant SQL et R
Bien que nous ne soyons pas liés aux conventions des outils OHDSI, il est utile de suivre les mêmes principes. Dans ce cas, nous utiliserons SQL pour peupler une table de cohorte, de la même manière que les outils OHDSI. La table COHORT est définie dans le CDM et possède un ensemble prédéfini de champs que nous utiliserons également. Nous devons d’abord créer la table COHORT dans un schéma de base de données où nous avons accès en écriture, ce qui n’est probablement pas le même que le schéma de base de données qui contient les données au format CDM.
library(DatabaseConnector)
conn <- connect(dbms = "postgresql",
server = "localhost/postgres",
user = "joe",
password = "secret")
cdmDbSchema <- "cdm"
cohortDbSchema <- "scratch"
cohortTable <- "my_cohorts"
sql <- "
CREATE TABLE @cohort_db_schema.@cohort_table (
cohort_definition_id INT,
cohort_start_date DATE,
cohort_end_date DATE,
subject_id BIGINT
);
"
renderTranslateExecuteSql(conn, sql,
cohort_db_schema = cohortDbSchema,
cohort_table = cohortTable)Ici, nous avons paramétré le schéma de base de données et les noms de table, afin de pouvoir les adapter facilement à différents environnements. Le résultat est une table vide sur le serveur de base de données.
9.7.1 Cohorte d’Exposition
Ensuite, nous créons notre cohorte d’exposition et l’insérons dans notre table COHORT :
sql <- "
INSERT INTO @cohort_db_schema.@cohort_table (
cohort_definition_id,
cohort_start_date,
cohort_end_date,
subject_id
)
SELECT 1 AS cohort_definition_id,
cohort_start_date,
cohort_end_date,
subject_id
FROM (
SELECT drug_era_start_date AS cohort_start_date,
drug_era_end_date AS cohort_end_date,
person_id AS subject_id
FROM (
SELECT drug_era_start_date,
drug_era_end_date,
person_id,
ROW_NUMBER() OVER (
PARTITION BY person_id
ORDER BY drug_era_start_date
) order_nr
FROM @cdm_db_schema.drug_era
WHERE drug_concept_id = 1308216 -- Lisinopril
) ordered_exposures
WHERE order_nr = 1
) first_era
INNER JOIN @cdm_db_schema.observation_period
ON subject_id = person_id
AND observation_period_start_date < cohort_start_date
AND observation_period_end_date > cohort_start_date
WHERE DATEDIFF(DAY,
observation_period_start_date,
cohort_start_date) >= 365;
"
renderTranslateExecuteSql(conn, sql,
cohort_db_schema = cohortDbSchema,
cohort_table = cohortTable,
cdm_db_schema = cdmDbSchema)Ici, nous utilisons la table DRUG_ERA, une table standard dans le CDM automatiquement dérivée de la table DRUG_EXPOSURE. La table DRUG_ERA contient des ères d’exposition continue au niveau de l’ingrédient. Nous pouvons ainsi rechercher le lisinopril, et cela identifiera automatiquement toutes les expositions aux médicaments contenant du lisinopril. Nous prenons la première exposition au médicament par personne, puis nous joignons cela à la table OBSERVATION_PERIOD. Étant donné qu’une personne peut avoir plusieurs périodes d’observation, nous devons nous assurer que nous ne joignons que la période contenant l’exposition au médicament. Nous exigeons ensuite au moins 365 jours entre la OBSERVATION_PERIOD_START_DATE et la COHORT_START_DATE.
9.7.2 Cohorte de Résultat
Enfin, nous devons créer notre cohorte de résultat :
sql <- "
INSERT INTO @cohort_db_schema.@cohort_table (
cohort_definition_id,
cohort_start_date,
cohort_end_date,
subject_id
)
SELECT 2 AS cohort_definition_id,
cohort_start_date,
cohort_end_date,
subject_id
FROM (
SELECT DISTINCT person_id AS subject_id,
condition_start_date AS cohort_start_date,
condition_end_date AS cohort_end_date
FROM @cdm_db_schema.condition_occurrence
INNER JOIN @cdm_db_schema.concept_ancestor
ON condition_concept_id = descendant_concept_id
WHERE ancestor_concept_id = 432791 -- Angioedema
) distinct_occurrence
INNER JOIN @cdm_db_schema.visit_occurrence
ON subject_id = person_id
AND visit_start_date <= cohort_start_date
AND visit_end_date >= cohort_start_date
WHERE visit_concept_id IN (262, 9203,
9201) -- Inpatient or ER;
"
renderTranslateExecuteSql(conn, sql,
cohort_db_schema = cohortDbSchema,
cohort_table = cohortTable,
cdm_db_schema = cdmDbSchema)Ici, nous joignons la table CONDITION_OCCURRENCE à la table CONCEPT_ANCESTOR pour trouver toutes les occurrences d’angioedème ou de ses descendants. Nous utilisons DISTINCT pour nous assurer de ne sélectionner qu’un seul enregistrement par jour, car nous pensons que plusieurs diagnostics d’angioedème le même jour sont plus susceptibles d’être la même occurrence plutôt que plusieurs événements distincts d’angioedème. Nous joignons ces occurrences à la table VISIT_OCCURRENCE pour nous assurer que le diagnostic a été fait en milieu hospitalier ou aux urgences.
9.7.3 Calcul du Taux d’Incidence
Maintenant que nos cohortes sont en place, nous pouvons calculer le taux d’incidence, stratifié par âge et sexe :
sql <- "
WITH tar AS (
SELECT concept_name AS gender,
FLOOR((YEAR(cohort_start_date) -
year_of_birth) / 10) AS age,
subject_id,
cohort_start_date,
CASE WHEN DATEADD(DAY, 7, cohort_start_date) >
observation_period_end_date
THEN observation_period_end_date
ELSE DATEADD(DAY, 7, cohort_start_date)
END AS cohort_end_date
FROM @cohort_db_schema.@cohort_table
INNER JOIN @cdm_db_schema.observation_period
ON subject_id = observation_period.person_id
AND observation_period_start_date < cohort_start_date
AND observation_period_end_date > cohort_start_date
INNER JOIN @cdm_db_schema.person
ON subject_id = person.person_id
INNER JOIN @cdm_db_schema.concept
ON gender_concept_id = concept_id
WHERE cohort_definition_id = 1 -- Exposure
)
SELECT days.gender,
days.age,
days,
CASE WHEN events IS NULL THEN 0 ELSE events END AS events
FROM (
SELECT gender,
age,
SUM(DATEDIFF(DAY, cohort_start_date,
cohort_end_date)) AS days
FROM tar
GROUP BY gender,
age
) days
LEFT JOIN (
SELECT gender,
age,
COUNT(*) AS events
FROM tar
INNER JOIN @cohort_db_schema.@cohort_table angioedema
ON tar.subject_id = angioedema.subject_id
AND tar.cohort_start_date <= angioedema.cohort_start_date
AND tar.cohort_end_date >= angioedema.cohort_start_date
WHERE cohort_definition_id = 2 -- Outcome
GROUP BY gender,
age
) events
ON days.gender = events.gender
AND days.age = events.age;
"
results <- renderTranslateQuerySql(conn, sql,
cohort_db_schema = cohortDbSchema,
cohort_table = cohortTable,
cdm_db_schema = cdmDbSchema,
snakeCaseToCamelCase = TRUE)Nous créons d’abord “tar,” un CTE qui contient toutes les expositions avec le temps à risque approprié. Notez que nous tronquons le temps à risque à la OBSERVATION_PERIOD_END_DATE. Nous calculons également l’âge par tranche de 10 ans et identifions le genre. L’avantage d’utiliser un CTE est que nous pouvons utiliser le même ensemble de résultats intermédiaires plusieurs fois dans une requête. Dans ce cas, nous l’utilisons pour compter la quantité totale de temps à risque, ainsi que le nombre d’événements d’angioedème qui se produisent pendant le temps à risque.
Nous utilisons snakeCaseToCamelCase = TRUE car en SQL, nous avons tendance à utiliser snake_case pour les noms de champs (parce que SQL est insensible à la casse), tandis qu’en R nous avons tendance à utiliser camelCase (parce que R est sensible à la casse). Les noms de colonnes du data frame results seront maintenant en camelCase.
Avec l’aide du package ggplot2, nous pouvons facilement tracer nos résultats :
# Calculer le taux d'incidence (IR) :
results$ir <- 1000 * results$events / results$days / 7
# Corriger l'échelle d'âge:
results$age <- results$age * 10
library(ggplot2)
ggplot(results, aes(x = age, y = ir, group = gender, color = gender)) +
geom_line() +
xlab("Âge") +
ylab("Incidence (pour 1 000 patients-semaines)")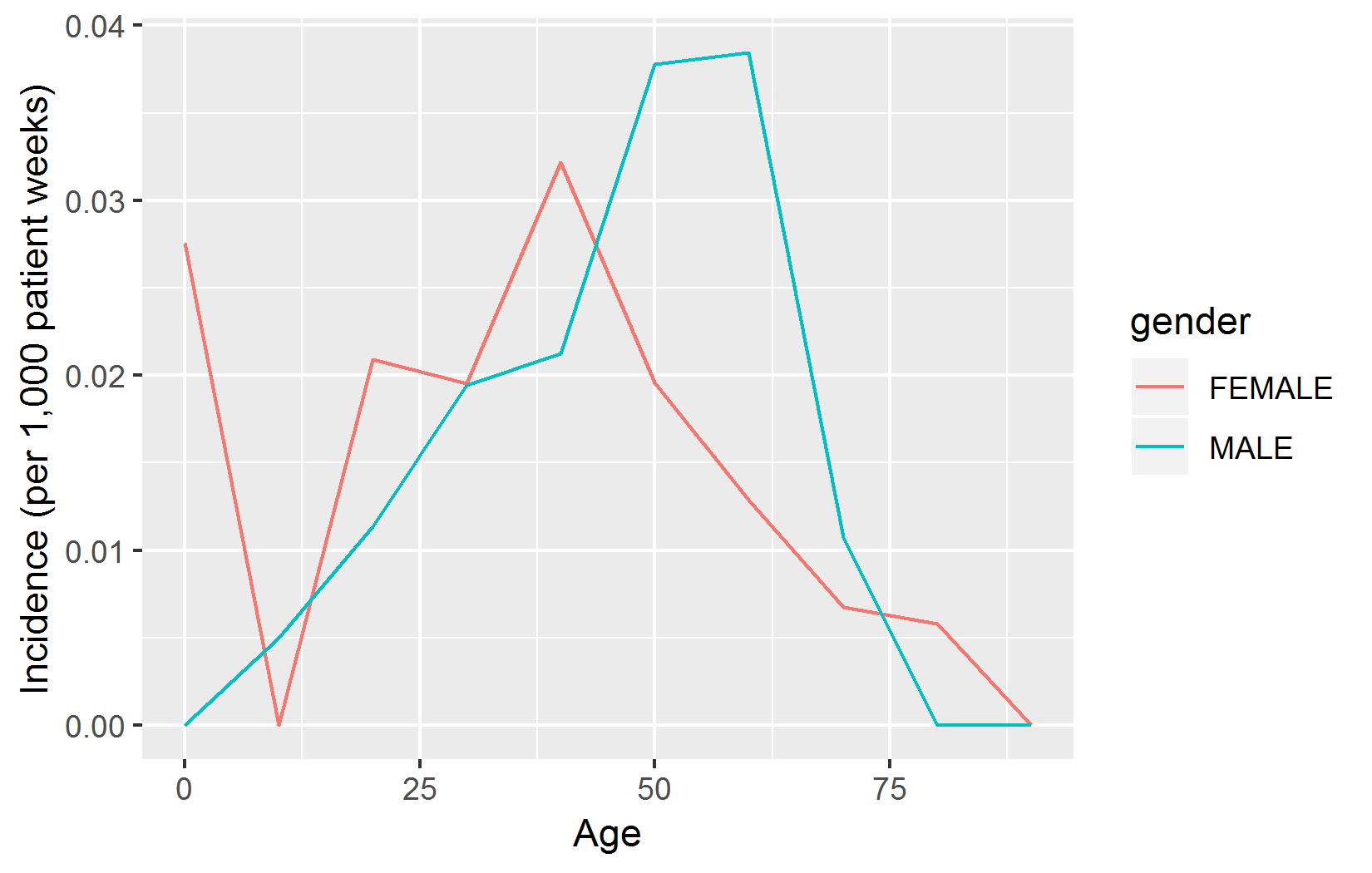
9.7.5 Compatibilité
Parce que nous utilisons OHDSI SQL avec DatabaseConnector et SqlRender partout, le code que nous avons examiné ici fonctionnera sur toutes les plateformes de base de données prises en charge par OHDSI.
Notez que, à des fins de démonstration, nous avons choisi de créer nos cohortes en utilisant du SQL écrit à la main. Il aurait probablement été plus pratique de construire la définition de la cohorte dans ATLAS, et d’utiliser le SQL généré par ATLAS pour instancier les cohortes. ATLAS produit également du SQL OHDSI et peut donc facilement être utilisé avec SqlRender et DatabaseConnector.
9.8 Résumé
SQL (Structured Query Language) est un langage standard pour interroger les bases de données, y compris celles qui sont conformes au Common Data Model (CDM).
Différentes plateformes de bases de données ont des dialectes SQL différents et nécessitent des outils différents pour les interroger.
Les packages R SqlRender et DatabaseConnector fournissent un moyen unifié pour interroger les données dans le CDM, permettant au même code d’analyse de s’exécuter dans différents environnements sans modification.
En utilisant R et SQL ensemble, nous pouvons mettre en œuvre des analyses personnalisées qui ne sont pas prises en charge par les outils OHDSI.
La QueryLibrary fournit une collection de requêtes SQL réutilisables pour le CDM.
9.9 Exercices
Prérequis
Pour ces exercices, nous supposons que R, R-Studio et Java ont été installés comme décrit dans la section 8.4.5. Les packages SqlRender, DatabaseConnector et Eunomia sont également nécessaires et peuvent être installés en utilisant :
install.packages(c("SqlRender", "DatabaseConnector", "remotes"))
remotes::install_github("ohdsi/Eunomia", ref = "v1.0.0")Le package Eunomia fournit un ensemble de données simulé dans le CDM qui s’exécute au sein de votre session R locale. Les détails de connexion peuvent être obtenus en utilisant :
Le schéma de la base de données CDM est “main”.
Exercice 9.1 En utilisant SQL et R, calculez combien de personnes se trouvent dans la base de données.
Exercice 9.2 En utilisant SQL et R, calculez combien de personnes ont au moins une prescription de célécoxib.
Exercice 9.3 En utilisant SQL et R, calculez combien de diagnostics d’hémorragie gastro-intestinale surviennent pendant l’exposition au célécoxib. (Indice : l’ID de concept pour l’hémorragie gastro-intestinale est 192671.)
Les réponses suggérées se trouvent dans l’Appendice ??.