第 11 章 特性評価
著者: Anthony Sena & Daniel Prieto-Alhambra
観察医療データベースは、さまざまな特性に基づく集団の差異を理解するための貴重なリソースとなります。記述統計を用いて集団の特性を把握することは、健康と疾患の決定要因に関する仮説を生成するための重要な第一歩です。本章では特性評価の方法について説明します:
- データベースの特性評価:データベース全体のデータプロファイルを全体的に理解するための、トップレベルの要約統計のセットを提供します。
- コホート特性評価:集団をその累積的な医療履歴に基づいて記述します。
- 治療経路:特定の期間に受けた一連の介入を説明します。
- 発生率:リスク期間における集団のアウトカムの発生率を測定する。
データベースレベルの特性評価を除き、これらの方法は「インデックス日」と呼ばれるイベントに対して集団を記述することを目的としています。この対象集団は、第10章で説明されているようにコホートとして定義されます。コホートは対象集団内の各人のインデックス日を定義します。インデックス日をアンカー(基点)として、インデックス日以前の時間をベースライン期間と定義し、インデックス日以降のすべての時間をポストインデックス期間と呼びます。
特性評価のユースケースには、疾患の自然経過、治療の利用状況、品質向上などが含まれます。本章では特性評価の方法を説明します。高血圧症患者の集団を例に、ATLASとRを使用してこれらの特性評価のタスクを実行する方法を示します。
11.1 データベースレベルの特性評価
関心集団についての特性評価の問いに答える前に、使用するデータベースの特性をまず理解する必要があります。データベースレベルの特性評価では、データベースレベルの特性評価では、時間的傾向と分布の観点からデータベースの全体像を説明しようとします。 データベースの定量的評価には、通常、以下のような質問が含まれます:
- このデータベースには全体で何人が含まれていますか?
- 年齢分布は?
- このデータベースで観察されている期間は?
- 時間の経過とともに{治療、状態・疾患(コンディション)、処置(プロシージャー)など}が記録・処方された人の割合は?
これらのデータベースレベルの記述統計は、研究者がデータベースに欠けている可能性のあるデータを理解するのにも役立ちます。第15章では、データ品質についてさらに詳しく説明します。
11.2 コホート特性評価
コホート特性評価は、コホート内の人々のベースラインとポストインデックスの特徴を記述します。OHDSIは、個人の履歴に存在するすべてのコンディション、薬剤やデバイスへの曝露、処置(プロシージャー)、その他の臨床観察の記述統計によって特徴を分析します。また、インデックス日時点でのコホートメンバーの社会人口統計学的属性も要約します。このアプローチは対象集団の完全な要約を提供します。重要なのは、これによりデータのばらつきを考慮しながらコホートを十分に探索でき、潜在的に欠損値となりうる値も特定できるということです。
コホートの特性評価の方法は、特定の治療を受けている患者の適応症や禁忌の有病率を推定する個人レベルの薬剤使用実態研究(Drug Utilization Study;DUS)にも使用できます。このコホート特性評価の普及は、観察研究における推奨されるベストプラクティスであり、Strengthening the Reporting of Observation Studies in Epidemiology(STROBE)ガイドラインで詳述されています(Elm et al. 2008)。
11.3 治療経路
集団の特性を評価するもう一つの方法は、インデックス後の期間における治療シーケンスを記述することが挙げられます。たとえば、George Hripcsak et al. (2016) は、OHDSIの共通データ標準を利用して、2型糖尿病、高血圧症、うつ病に対する治療経路を特性づける記述統計を作成しました。この分析アプローチを標準化することにより、Hripcsakらは、同じ分析をOHDSIネットワーク全体で実行して、これらの対象集団の特徴を記述することができました。
経路分析は、特定のコンディションを診断された人が最初の薬剤処方/調剤を受けた治療(イベント)を要約することを目的としています。この研究では、治療はそれぞれ2型糖尿病、高血圧症およびうつ病の診断後に記述されました。その後、各人のイベントは集計され、各コンディション、各データベースに対して要約統計として視覚化されました。
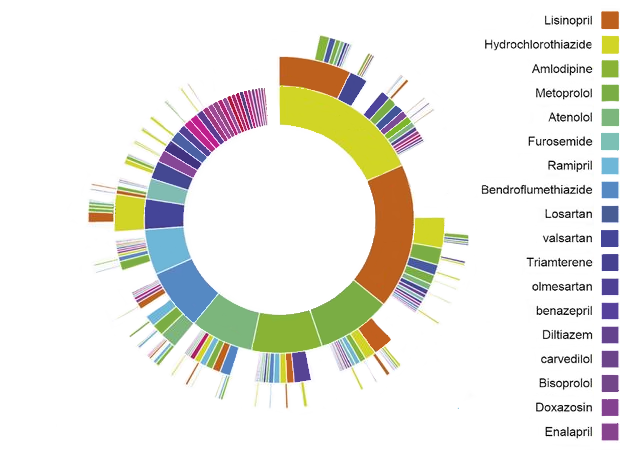
図 11.1: 高血圧症のOHDSI治療経路「サンバースト」グラフ
例として、図 11.1 は高血圧症治療を開始する患者集団を表しています。中央にある最初の円は、第一選択治療に基づいた人々の割合を示しています。この例では、ヒドロクロロチアジドがこの集団で最も一般的な最初の治療法です。ヒドロクロロチアジドの部分から延びるボックスは、コホート内の患者に対して記録された2番目および3番目の治療法を示しています。
経路分析は、集団における治療利用に関する重要なエビデンスを提供します。この分析から、最初の治療法として最も一般的に利用される第一選択治療、治療を中止する人、治療を変更する人、または治療を強化する人の割合を記述することができます。経路分析を使用して、George Hripcsak et al. (2016) はメトホルミンが糖尿病治療に対して最も一般的に処方されている薬剤であることを確認し、米国内分泌学会の糖尿病治療アルゴリズムの第一選択推奨が一般的に採用されていることを確認されました。さらに、糖尿病患者の10%、高血圧症患者の24%、うつ病患者の11%が、いずれのデータソースにおいても共通しない治療経路をたどっていたことが明らかになりました。
従来のDUS(薬剤使用実態研究)用語では、治療経路分析は、指定された集団における一つまたは複数の薬剤の使用の普及率などの集団レベルのDUS推定値や継続性やさまざまな治療法間の切り替えの測定などの個人レベルのDUSを含みます。
11.4 発生率
発生率および発生割合は、時間の経過とともに集団における新たなアウトカムの発生を評価するための公衆衛生の統計です。図 11.2 は、単一の人に対する発生率の計算要素を示すことを目的としています:
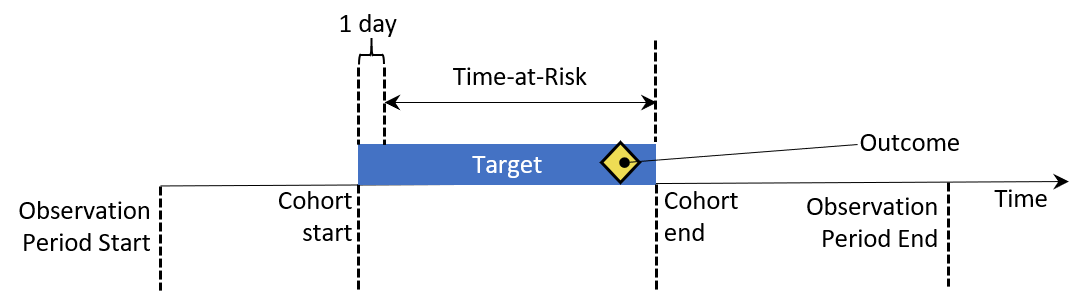
図 11.2: 発生率計算要素の人単位のビュー。この例では、リスク時間はコホート開始の翌日に始まり、コホート終了時に終了します。
図 11.2 では、人がデータで観察される期間が観察開始と終了時間によって示されています。次に、個人がいくつかの適格基準を満たしてコホートに組入れられる時点と離脱する時点があります。リスク時間ウィンドウは、アウトカムの発生を理解しようとする期間を示しています。アウトカムがリスク時間内に発生した場合、それをアウトカムの発生としてカウントします。
発生率を計算するための2つの尺度があります:
\[ 発生割合 = \frac{\#\;リスク時間中に新しいアウトカムが発生したコホート内の人数}{\#\;リスク時間を持つコホート内の人数} \]
発生割合は、リスク時間中に集団内で発生した新規のアウトカムの割合を提供します。別の言い方をすると、これは定義された時間内に対象集団内でアウトカムを得た割合を示します。
\[ 発生率 = \frac{\#\;リスク時間中に新規のアウトカムが発生したコホート内の人数}{コホート内の人によって提供されたリスク時間の人年} \]
発生率は、集団の累積的なリスク時間内に新規のアウトカムの数を測定する指標です。リスク時間中にある人がアウトカムを経験した場合、その人のリスク時間への寄与はアウトカムの発生時点で停止します。累積的なリスク時間は人年と呼ばれ、日、月、または年単位で表現されます。
治療に対して計算される場合、発生割合および発生率は、特定の治療の使用における集団レベルのDUSの古典的な尺度です。
11.5 高血圧症患者の特性評価
世界保健機関(WHO)の高血圧症に関するグローバル概要(Who 2013)によると、高血圧症の早期発見、適切な治療、良好な管理には、健康と経済上の両面で大きな利益がもたらされるとしています。WHOの概要は、高血圧症についての概観を提供し、各国における疾病負担の特性を評価しています。WHOは、地理的地域、社会経済的階級、性別ごとに高血圧症の記述統計を提供しています。
観察研究のデータソースは、WHOが行ったように高血圧症患者集団の特性を評価する方法を提供します。本章の後のセクションでは、ATLASとRを使用してデータベースを探索し、高血圧症患者集団を研究するための構成を理解する方法を探ります。その後、これらのツールを使用して、高血圧症患者集団の自然経過と治療パターンを記述します。
11.6 ATLASにおけるデータベースの特性評価
ここでは、ACHILLES で作成されたデータベースの特性評価統計を調査するために、ATLASのデータソースモジュールを使用する方法を示します。まず、ATLASの左側のバーにある  をクリックして開始します。ATLASに表示される最初のドロップダウンリストで、調査するデータベースを選択します。次に、データベースの下のドロップダウンを使用してレポートの探索を始めます。これを行うには、レポートドロップダウンリストから「Condition Occurrence」を選択し、データベースに存在するすべての症状のツリーマップを表示します:
をクリックして開始します。ATLASに表示される最初のドロップダウンリストで、調査するデータベースを選択します。次に、データベースの下のドロップダウンを使用してレポートの探索を始めます。これを行うには、レポートドロップダウンリストから「Condition Occurrence」を選択し、データベースに存在するすべての症状のツリーマップを表示します:
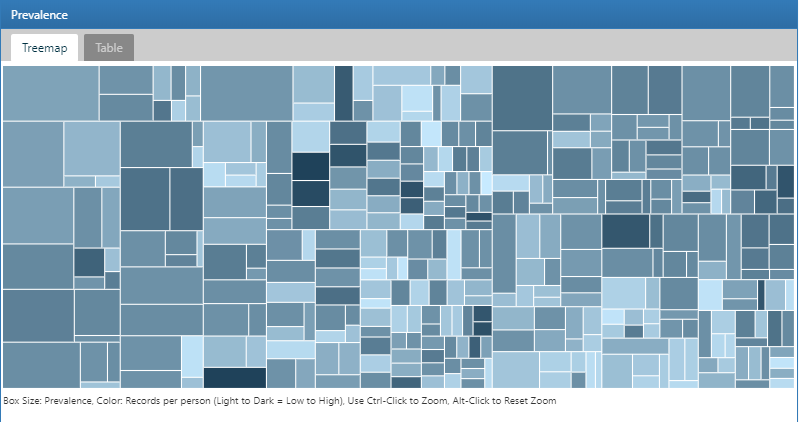
図 11.3: ATLASデータソース: コンディション出現のツリーマップ
特定の関心のあるコンデションを検索するには、テーブルタブをクリックして、データベース内のすべてのコンディションのリストを表示し、人数、有病率、個人ごとのレコード数を確認します。上部のフィルターボックスを使用して、コンセプト名に「hypertension(高血圧)」を含む項目に基づいてリストをフィルタリングできます:
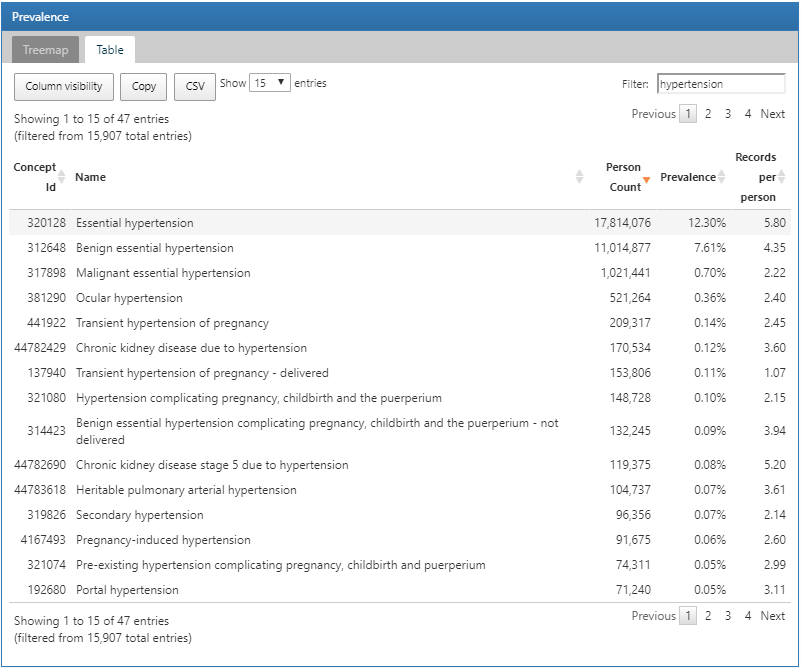
図 11.4: ATLASデータソース: コンセプト名に 「hypertension (高血圧)」が含まれるコンディション
特定のコンディションの詳細なドリルダウンレポートを表示するには、行をクリックします。ここでは、「essential hypertension(本態性高血圧)」を選択し、選択されたコンディションの経時的および性別ごとの傾向、月ごとの有病率、記録された病型、診断の初回発生時の年齢の分布を確認します:
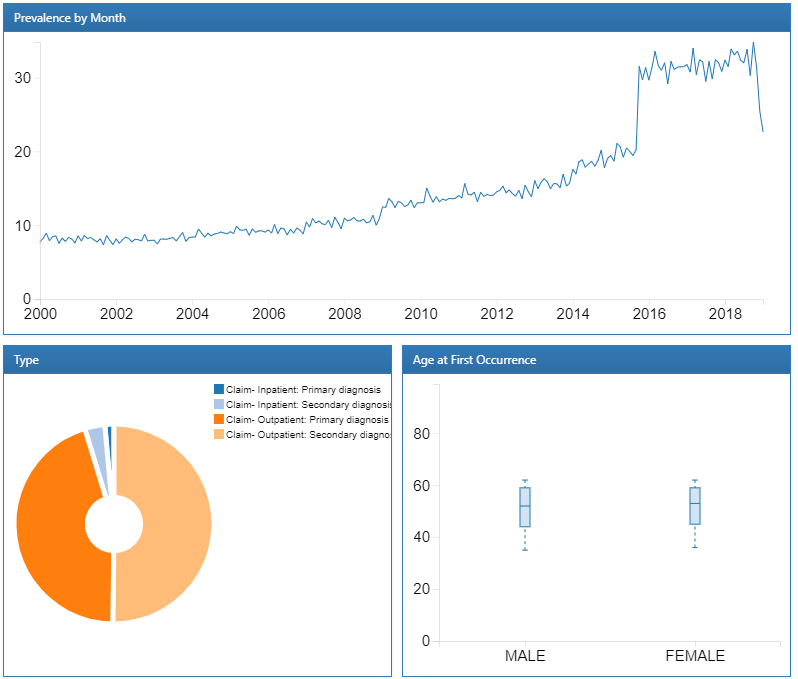
図 11.5: ATLASデータソース: 本態性高血圧ドリルダウンレポート
高血圧症のコンセプトの有無と経時的な傾向についてデータベースの特性を確認した後、高血圧症患者の治療に使用される薬剤を調査することもできます。これを行うには、同じ手順に従い、RxNormの成分に要約された薬剤の特性を確認するため、「Drug Era(薬剤曝露期間)」レポートを使用します。データベースの特性を探索して関心のある項目を確認し、高血圧症患者を特性化するためのコホートの構築を進める準備を整えます。
11.7 ATLASにおけるコホート特性分析
ここでは、ATLASを使用して複数のコホートの大規模な特性評価を行う方法を示します。左側のバーにある をクリックし、新しい特性評価を作成します。分析に名前を付け、
をクリックし、新しい特性評価を作成します。分析に名前を付け、 ボタンを使用して保存します。
ボタンを使用して保存します。
11.7.1 デザイン
特性評価には、少なくとも1つのコホートと少なくとも1つの特性が必要です。この例では、2つのコホートを使用します。最初のコホートでは、その前の1年間に少なくとも1つの高血圧症診断を受けた人をインデックス日と定義します。また、このコホートに属する人が治療開始後少なくとも1年間の観察期間があることも必要です(付録 B.6)。2つ目のコホートは、最初のコホートと同様ですが、1年間の代わりに少なくとも3年間の観察期間を必要とします(付録 B.7)。
コホート定義
図 11.6: 特性設計タブ - コホート定義の選択
コホートは既にATLASで作成されていると仮定しています(第10章を参照)。 をクリックし、図 11.6 に示すようにコホートを選択します。次に、これらのコホートを特性評価するために使用する特性を定義します。
をクリックし、図 11.6 に示すようにコホートを選択します。次に、これらのコホートを特性評価するために使用する特性を定義します。
特徴量の選択
ATLASにはOMOP CDMでモデル化された臨床ドメイン全体で特性評価を行うため、約100の事前設定された特徴量分析が備わっています。これらのそれぞれの事前に規定された特徴量分析は、各ターゲットコホートに対して臨床観察を集約および要約する機能を提供します。これらの計算は、コホートのベースラインおよびポストインデックス特性を説明するために、潜在的に数千の特徴量を提供します。この元で、ATLASは、各コホートの特性評価を行うために、OHDSIのFeatureExtraction Rパッケージを利用しています。次のセクションでは、FeatureExtractionとRの使用について詳しく説明します。
をクリックして、特性評価をするための特徴量を選択します。以下は、これらのコホートを特性評価するために使用する特徴量のリストです:
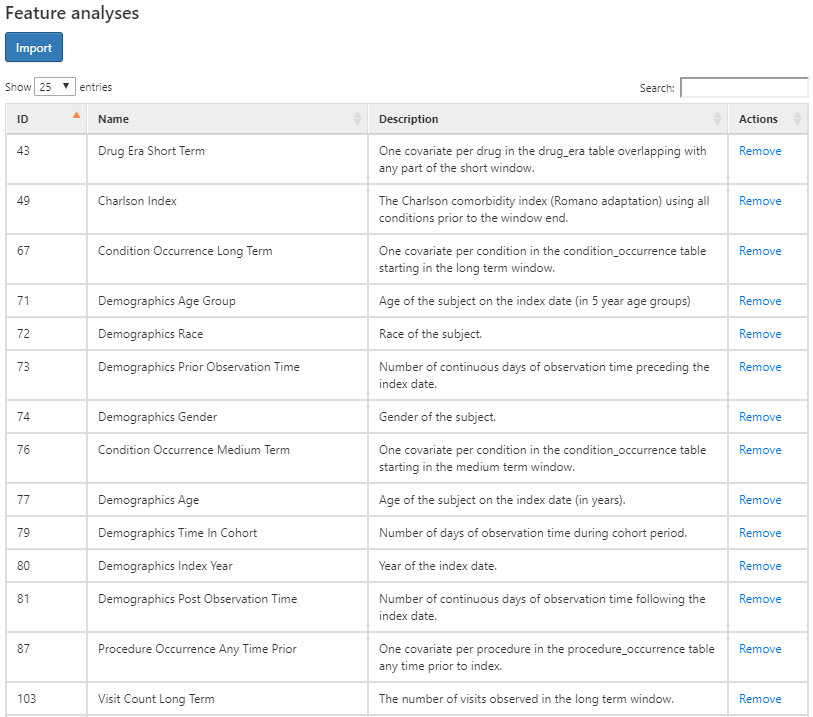
図 11.7: 特性設計タブ - 特徴量の選択
上の図は、選択された特徴量のリストと、各特徴量が各コホートについて何を特性評価するかの説明を示しています。 「Demographics(人口動態的特性)」で始まる特徴量は、コホート開始日における各人の人口統計情報を計算します。ドメイン名(例:ビジット、プロシージャー、コンディション、薬剤など)で始まる特徴量は、そのドメインにおけるすべての記録された観測値を特徴づけます。各ドメインの特徴量には、コホート開始前の時間ウィンドウとして、以下の4つの選択肢があります:
- Any time prior(任意の期間): コホート開始前のすべての利用可能な期間で、その人の観察期間に該当するものを使用。
- Long term(長期): コホート開始日を含む最大365日前まで。
- Medium term(中期): コホート開始日を含む最大180日前まで。
- Short term(短期): コホート開始日を含む最大30日前まで。
11.7.2 実行
特性評価のデザインが完了したら、環境内の1つ以上のデータベースに対してこのデザインを実行できます。実行タブに移動し、「Generate(生成)」ボタンをクリックしてデータベースで分析を開始します:
図 11.9: 特性評価設計の実行 - CDMソース選択
分析が完了したら、「All Executions(すべてを実行)」ボタンをクリックしてレポートを表示し、実行リストから「View Reports(レポートを見る)」を選択します。あるいは、「View latest result(最新の結果を見る)」をクリックして、最後に実行されたアウトカムを表示することもできます。
11.7.3 結果
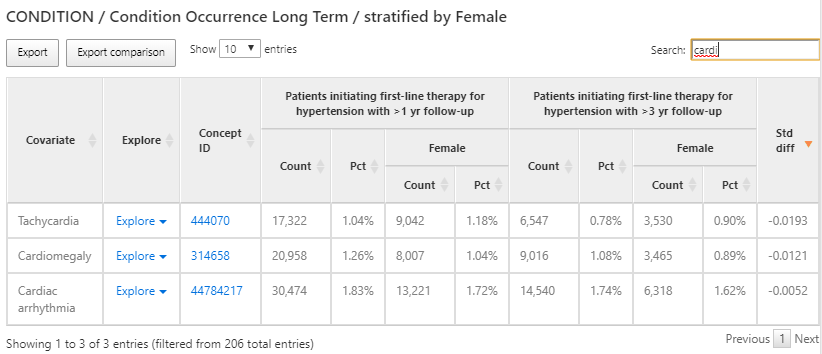
図 11.10: 特性アウトカム - 過去1年間のコンディションの発生
結果は、デザインで選択した各コホートについて、さまざまな特徴量を一覧表示します。図 11.10 では、コホート開始日の前の365日間に存在するすべてのコンディションの概要が提供されています。各共変量には、コホートごとおよび定義した女性サブグループのカウントと割合が表示されています。
検索ボックスを使用してアウトカムをフィルターし、「cardiac arrhythmia(不整脈)」の既往を持つ人の割合を確認することで、集団でどのような心血管関連診断が観察されるかを理解しようとしました。「Explore」リンクをクリックして新しいウィンドウを開き、単一コホートのコンセプトに関する詳細を表示することができます(図 11.11 参照)。
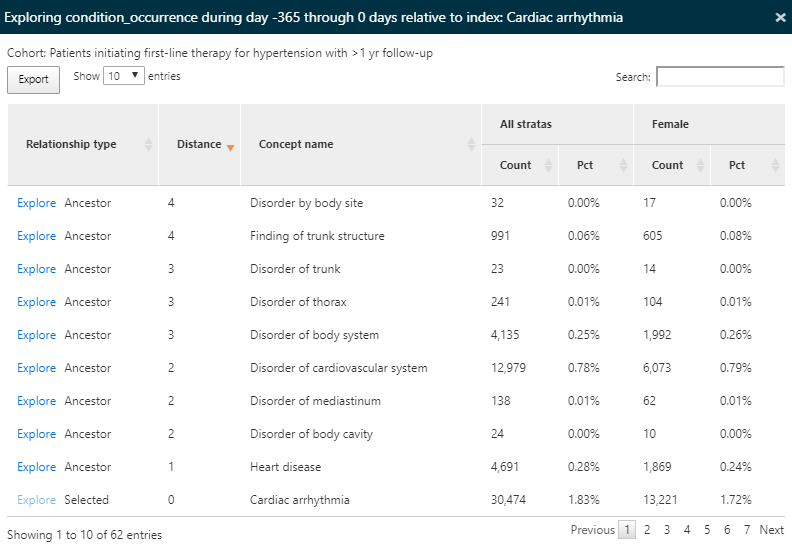
図 11.11: 特性アウトカム - 単一コンセプトの探索
コホートのすべてのコンディションコンセプトを特性評価したため、「explore(探索する)」オプションを使用して、選択されたコンセプト(この場合は不整脈)のすべての上位層と下位層に含まれるコンセプトを表示します。この探索により、高血圧症のある人に現れる可能性のある他の心疾患を探索するためのコンセプトの階層をナビゲートすることができます。要約表示と同様に、カウントとパーセンテージが表示されます。
この特性結果を用いて、高血圧症治療に禁忌のあるコンディション(例:血管性浮腫)を見つけることもできます。これを行うには、上記と同じ手順を実行しますが、今回は「edema(浮腫)」を検索します(図 11.12 を参照)。
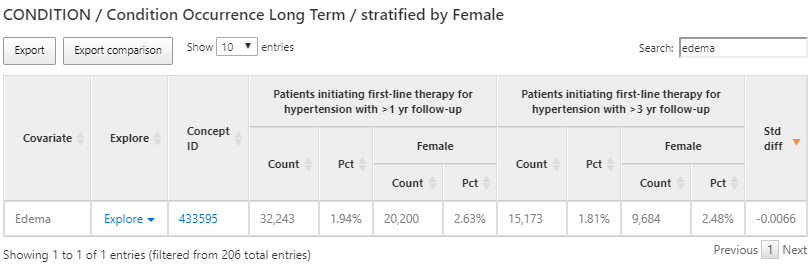
図 11.12: 特性評価の結果 - 禁忌コンディションの探索
再度、特徴量を「explore(探索する)」を使用して、高血圧症集団における浮腫の特性を調べ、血管性浮腫の有病率を確認します:
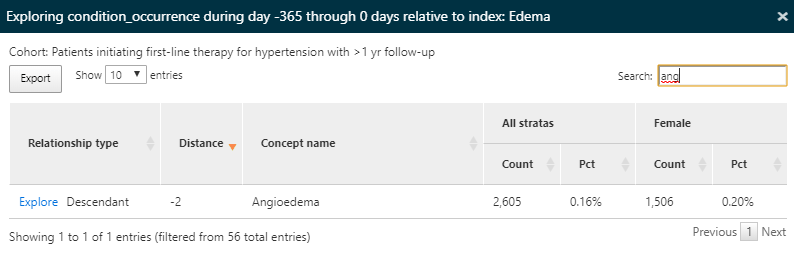
図 11.13: 特性アウトカム - 禁忌コンディションの詳細を探索
ここでは、降圧薬を開始する前の1年間に血管性浮腫の既往歴がこの集団の一部にあることが確認されました。
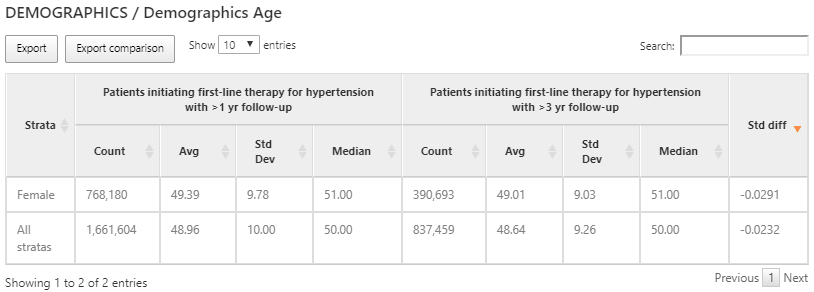
図 11.14: 各コホートとサブグループの年齢特性アウトカム
ドメイン共変量は、コホート開始前の時間枠にコードの記録が存在したかどうかを示す二元指標を用いて計算されますが、一部の変数はコホート開始時の年齢のように連続変数として提供されます。上の例では、人数、平均年齢、中央値、標準偏差などで表現された、2つのコホートの年齢を示しています。
11.7.4 カスタム特徴量の定義
既定の特徴量に加えて、ATLASはユーザー定義のカスタム特徴量を用いることもできます。これを行うには、左側のメニューの Characterization(特性評価)をクリックし、Feature Analysis(特徴量分析)タブをクリックして、New Feature Analysis(新規の特徴量分析)ボタンをクリックします。カスタム特性に名前を付け、ボタンを使用して保存します。
この例では、コホート内で、ACE阻害剤の服用歴が各コホート開始後にある人数を特定するカスタム特徴量を定義します:
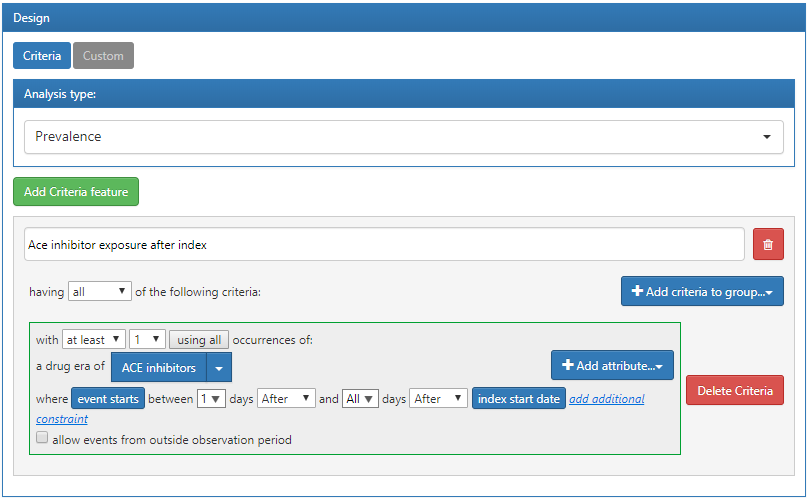
図 11.15: ATLASでのカスタム特徴量定義
上で定義した基準は、コホート開始日に適用されることを前提としています。基準を定義し保存したら、前のセクションで作成した特徴量の評価にこの基準を適用できます。特徴量の評価のデザインを開き、Feature Analysis(特徴量分析)セクションに移動します。ボタンをクリックし、メニューから新しいカスタム特徴量を選択します。これで、特性評価デザインのリストに表示されます。前述のように、このデザインをデータベースに対して実行して、このカスタム特徴量による特性評価を実行することができます:

図 11.16: カスタム機能の結果表示
11.8 Rでのコホートの特性評価
Rを使用してコホートをの特性を評価することもできます。このセクションでは、OHDSI RパッケージであるFeatureExtractionを使用して、高血圧症コホートのベースライン特徴量を生成する方法について説明します。FeatureExtractionは、3つの方法で共変量を構築する機能を提供します。
- デフォルトの共変量セットを選択する
- 事前に指定された分析セットから選択する
- カスタム分析セットを作成する
FeatureExtractionは、個人レベルの特徴量と集約特徴の2つの異なる方法で共変量を作成します。個人レベルの特徴量は機械学習アプリケーションで有用です。本セクションでは、対象とするコホートを説明するベースライン共変量を生成するのに有用な集約統計量の使用に焦点を当てます。さらに、事前に指定された分析とカスタム分析という2つの方法で共変量を構築する方法に焦点を当て、デフォルトのセットを使用する方法は読者への課題として残します。
11.8.1 コホートのインスタンス化
最初に、特性を評価するためにコホートをインスタンス化する必要があります。コホートのインスタンス化は、第10章で説明されています。この例では、高血圧症に対して一次治療を開始し、1年間のフォローアップを行う人を使用します(付録 B.6)。付録 B の他のコホートの特性評価は、読者への練習問題として残しておきます。ここでは、コホートがscratch.my_cohortsというテーブルでインスタンス化され、コホート定義IDが1であると仮定します。
11.8.2 データ抽出
まず、Rにサーバーへの接続方法を指示する必要があります。FeatureExtractionはDatabaseConnectorパッケージを使用し、createConnectionDetailsという関数を提供します。さまざまなデータベース管理システム(DBMS)に必要な特定の設定については、?createConnectionDetailsを参照ください。例えば、次のコードでPostgreSQLデータベースに接続できます:
library(FeatureExtraction)
connDetails <- createConnectionDetails(dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
cdmDbSchema <- "my_cdm_data"
cohortsDbSchema <- "scratch"
cohortsDbTable <- "my_cohorts"
cdmVersion <- "5"最後の4行は、cdmDbSchema、cohortsDbSchema、cohortsDbTable変数、およびCDMバージョンを定義します。これらはの変数は、CDM形式のデータがどこにあるか、対象とするコホートがどこに作成されたか、どのCDMバージョンが使用されているか、をRに通知します。Microsoft SQL Serverの場合、データベーススキーマはデータベースとスキーマの両方を指定する必要があることに注意ください。したがって、例えばcdmDbSchema <- "my_cdm_data.dbo"となります。
11.8.3 事前に指定された分析の使用
createCovariateSettings関数は、ユーザーが定義済みの多くの共変量から選択できるようにします。利用可能なオプションの概要については、?createCovariateSettingsを入力して参照ください。例えば、以下のようになります:
settings <- createCovariateSettings(
useDemographicsGender = TRUE,
useDemographicsAgeGroup = TRUE,
useConditionOccurrenceAnyTimePrior = TRUE)これにより、性別、年齢(5歳との年齢グループ)、およびコホート開始日までの期間(開始日を含む)のcondition_occurenceテーブルで観測された各コンセプトのバイナリ共変量が作成されます。
多くの事前に指定された分析は、短期、中期、長期の時間枠を参照しています。デフォルトでは、これらの枠は次のように定義されています:
- 長期: コホート開始日を含む365日前まで
- 中期: コホート開始日を含む180日前まで
- 短期: コホート開始日を含む30日前まで
ただし、ユーザーはこれらの値を変更できます。例を以下に示します:
settings <- createCovariateSettings(useConditionEraLongTerm = TRUE,
useConditionEraShortTerm = TRUE,
useDrugEraLongTerm = TRUE,
useDrugEraShortTerm = TRUE,
longTermStartDays = -180,
shortTermStartDays = -14,
endDays = -1)これは、長期ウィンドウをコホート開始日の180日前から当日まで(当日を含まず)と再定義し、短期ウィンドウをコホート開始日の14日前から当日まで(当日を含まず)と再定義します。 また、共変量を構築する際に使用すべき、または使用すべきでないコンセプトIDを指定することもできます:
settings <- createCovariateSettings(useConditionEraLongTerm = TRUE,
useConditionEraShortTerm = TRUE,
useDrugEraLongTerm = TRUE,
useDrugEraShortTerm = TRUE,
longTermStartDays = -180,
shortTermStartDays = -14,
endDays = -1,
excludedCovariateConceptIds = 1124300,
addDescendantsToExclude = TRUE,
aggregated = TRUE)11.8.4 集約共変量の作成
次のコードブロックは、コホートの集計統計を生成します:
covariateSettings <- createDefaultCovariateSettings()
covariateData2 <- getDbCovariateData(
connectionDetails = connectionDetails,
cdmDatabaseSchema = cdmDatabaseSchema,
cohortDatabaseSchema = resultsDatabaseSchema,
cohortTable = "cohorts_of_interest",
cohortId = 1,
covariateSettings = covariateSettings,
aggregated = TRUE)
summary(covariateData2)出力は次のようになります:
## CovariateData Object Summary
##
## Number of Covariates: 41330
## Number of Non-Zero Covariate Values: 4133011.8.5 出力形式
集計されたcovariateDataオブジェクトの主なコンポーネントは、二値および連続の共変量に対してそれぞれcovariatesとcovariatesContinuousです:
11.8.6 カスタム共変量
FeatureExtractionは、カスタム共変量を定義および利用する機能も提供します。これらの詳細は高度なトピックであり、ユーザードキュメントに記載されています:http://ohdsi.github.io/FeatureExtraction/
11.9 ATLASにおけるコホート経路分析
経路分析の目標は、1つまたは複数の対象とするコホート内で治療がどのように順序づけられているかを理解することです。適用される方法は George Hripcsak et al. (2016) によって報告されたデザインに基づいています。これらの方法は一般化され、ATLASのCohort Pathwaysという機能に組み込まれました。
コホート経路の目的は、1つまたは複数の対象とするコホートのコホート開始日以降のイベントを要約する分析機能を提供することです。そのために、対象となる集団の臨床イベントを特定するためのイベントコホートと呼ばれるコホートセットを作成します。これが対象とするコホート内の人物に対してどのように見えるかを例として示します。

図 11.17: 単一の人物におけるパスウェイ分析の文脈
図 11.17 では、その人物が開始日と終了日が定義された対象コホートに属していることを示しています。その後、番号付きの線分は、その人物が特定の期間、イベントコホートで特定され他期間を示しています。イベントコホートは、CDMに表された任意の臨床イベントを記述することができるため、単一のドメインまたはコンセプトに対してパスウェイを作成する必要はありません。
まず、ATLASの左側のバーで  をクリックして、新しいコホートパスウェイスタディを作成します。分かりやすい名前を入力し、保存ボタンを押します。
をクリックして、新しいコホートパスウェイスタディを作成します。分かりやすい名前を入力し、保存ボタンを押します。
11.9.1 デザイン
まず、高血圧症の第一選択療法を開始するコホートと、1年および3年間のフォローアップ(付録 B.6、 B.7)を引き続き使用します。ボタンを使用して、2つのコホートをインポートします。
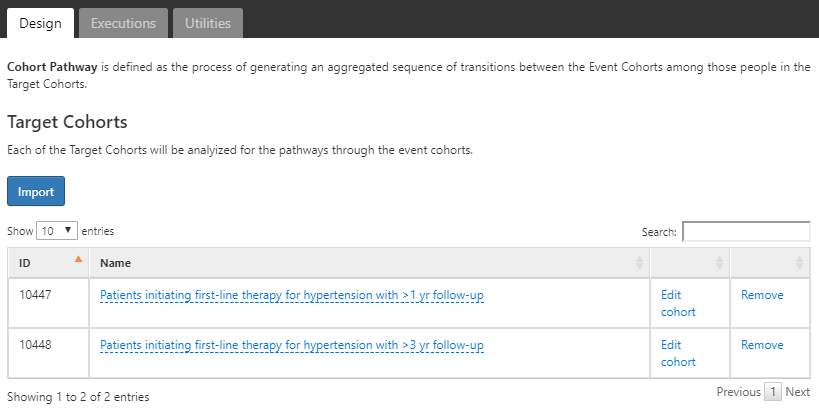
図 11.18: 対象コホートを選択したパスウェイ分析
次に、対象となる各第一選択の降圧薬のイベントコホートを作成して、イベントコホートを定義します。まず、ACE阻害薬使用者のコホートを作成し、コホートの終了日を継続曝露の終了日と定義します。同様に他の8つの降圧薬のコホートも作成します。これらの定義は付録 B.8 ~ B.16 に記載されていることを確認ください。完了したら、 ボタンをクリックして、これらの定義を経路デザインのイベントコホートセクションにインポートします。
図 11.19: 初回第一選択降圧治療を開始するためのイベントコホート
完了すると、デザインは上記のようになるはずです。次に、いくつかの追加の分析設定を決定する必要があります:
- 組み合わせウィンドウ: この設定では、イベント間の重複がイベントの組み合わせと見なされる日数の期間を定義できます。たとえば、2つのイベントコホート(イベントコホート1およびイベントコホート2)で表される2つの薬剤が組み合わせウィンドウ内で重複する場合、パスウェイアルゴリズムはそれらを「イベントコホート1 + イベントコホート2」として組み合わせます。
- 最小セル数: この人数に満たないイベントコホートは、プライバシー保護のため、出力から削除されます。
- 最大経路長: 分析の対象となる一連のイベントの最大数を指します。
11.9.2 実行
パスウェイ分析のデザインが完了すると、環境内の1つ以上のデータベースに対してこのデザインを実行できます。これは、ATLASでのコホートの特性評価で説明したのと同じ方法で機能します。完了したら、分析の結果を確認できます。
11.9.3 結果の表示
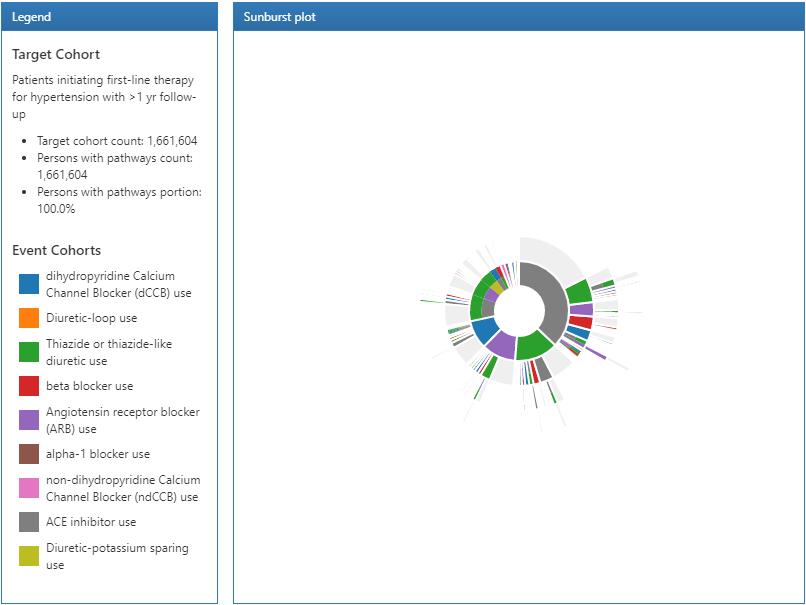
図 11.20: 経路結果の凡例とサンバースト図
パスウェイ分析の結果は3つのセクションに分かれています:凡例セクションでは、対象コホートの総人数と、パスウェイ分析で1つ以上のイベントがあった人数が表示されます。その下には、サンバーストプロットの中央セクションに表示される各コホートの色分けが表示されます。
サンバースト図は、時間の経過に伴うさまざまなイベント経路を視覚的に表現したものです。図の中心はコホートへの組入れを表しており、最初の色分けは各イベントコホートにいる人の割合を示しています。例では、円の中心は第一選択薬による治療を開始した高血圧症患者を表しています。次に、サンバースト図の最初のリングは、イベントコホートによって定義された第一選択薬の種類(すなわち、ACE阻害薬、アンジオテンシン受容体拮抗薬など)。2番目のリングセットは、人々にとって2番目のイベントコホートを表しています。特定のイベントシーケンスでは、データで2番目のイベントコホートが観察されない場合があり、その割合はリングの灰色の部分で表されます。
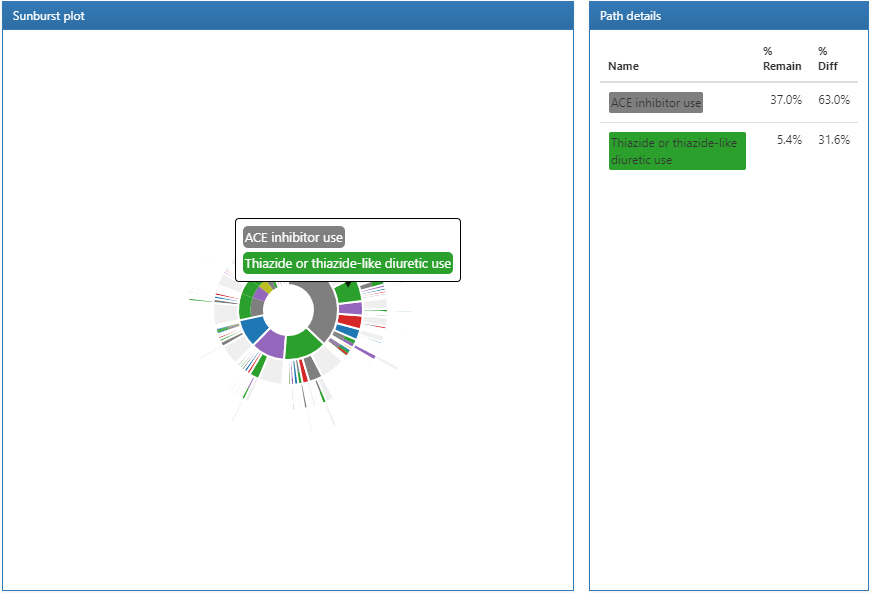
図 11.21: 経路の詳細を表示するパスウェイアウトカム
サンバーストプロットのセクションをクリックすると、右側に経路の詳細が表示されます。ここでは、対象コホートにおける大多数の人がACE阻害薬による第一選択療法を開始し、そのグループからさらに少数の人がサイアザイドまたはサイアザイド様利尿薬による治療を開始していることが分かります。
11.10 ATLAS における発生率分析
発生率の算出では、以下の内容を記述しますク期間中に、対象コホートに属する人の中で、アウトカムコホートを経験した人。ここでは、ACE阻害薬(ACEi)、サイアザイドおよびサイアザイド様利尿薬(THZ)の新規使用者における血管性浮腫および急性心筋梗塞のアウトカムを特徴づける発生率の分析をデザインします。対象者が薬剤に曝露されたTAR期間中のこれらのアウトカムを評価します。さらに、アンジオテンシン受容体拮抗薬(ARB)への曝露による転帰を追加し、対象コホート(ACEiおよびTHZ)への曝露期間中のARBの新規使用の発生率を測定します。このアウトカム定義により、対象集団におけるARBの利用状況を把握することができます。
まず、ATLAS の左側のバーにある  をクリックし、新規の発生率分析を作成します。分かりやすい名前を入力し、保存ボタン をクリックします。
をクリックし、新規の発生率分析を作成します。分かりやすい名前を入力し、保存ボタン をクリックします。
11.10.1 デザイン
本例で使用されるコホートは、既にATLASに作成されていると仮定します(第10章で説明)。付録には、対象コホート(付録 B.2、B.5) およびアウトカムコホート(付録 B.4、B.3、B.9)の完全な定義が記載されています。

図 11.22: 対象およびアウトカム定義の発生率
定義タブで、「New users of ACE inhibitors(ACE阻害薬の新規ユーザー)」コホートと「New users of Thiazide or Thiazide-like diuretics (サイアザイドまたはサイアザイド様利尿薬の新規ユーザー)」コホートをクリックして選択します。ダイアログを閉じて、これらのコホートが追加されたことを確認します。次に、アウトカムコホートを追加するためにクリックし、ダイアログボックスから「acute myocardial infarction events(急性心筋梗塞イベント)」、 「angioedema events(血管性浮腫イベント)」、および「Angiotensin receptor blocker (ARB) use(アンジオテンシン受容体拮抗薬(ARB)の新規ユーザー)」のアウトカムコホートを選択します。再びウィンドウを閉じて、これらのコホートがアウトカムコホートセクションに追加されたことを確認します。
図 11.23: 対象およびアウトカム定義の発生率
次に、分析のリスク期間を定義します。上に示すように、リスク期間はコホートの開始日とび終了日を基準として定義されます。ここでは、対象コホートの開始日の翌日をリスク期間の開始として定義します。次に、リスク期間終了日をコホートの終了日に終了するよう定義します。この場合、ACEi および THZ コホートの定義には、薬剤曝露が終了する時点をコホート終了日としています。
ATLAS では、分析仕様の一部として対象コホートを層別化する方法も提供しています:
図 11.24: 女性における発生率の層別定義
これを行うには、「New Stratify Criteria(新規層別化基準)」ボタンをクリックし、本章で説明されている手順に従います。設計が完了したので、一つまたは複数のデータベースに対して設計を実行します。
11.10.2 実行
「Generation (生成)」タブをクリックし、 ボタンをクリックして、分析を実行するデータベースの一覧を表示します:
ボタンをクリックして、分析を実行するデータベースの一覧を表示します:
図 11.25: 発生率分析実行
一つ以上のデータベースを選択し、「Generation」ボタンをクリックして、指定された対象コホートとアウトカムのすべての組み合わせの分析を開始します。
11.10.3 結果の表示
「Generation」タブでは、画面の上部でターゲットおよびアウトカムを選択してアウトカムを表示することができます。そのすぐ下には、分析で使用された各データベースの発生率のサマリーが表示されます。
それらのドロップダウンリストからACE阻害薬ユーザーの対象となるコホートと急性心筋梗塞(AMI)を選択します。 ボタンをクリックして発生率分析の結果を表示します:
ボタンをクリックして発生率分析の結果を表示します:

図 11.26: 発生率分析の出力 - AMI のアウトカムを持つ新規 ACE阻害薬ユーザー
データベースの要約は、リスク時間中に観察されたコホート内の総人数と総症例数を示します。割合は1000人当たりの症例数を示しています。対象コホートのリスク期間は年単位で計算されます。発生率は1000人年当たりの症例数として表されます。
設計で定義した層の発生率メトリクスも見ることができます。上記のメトリクスは各層についても計算されます。さらに、ツリーマップの視覚化は、それぞれの層が表す割合をボックスエリアとして視覚的に表示します。色は、下部の目盛りで示されるスケールに沿って発生率を示しています。
ACEi 集団の中で ARB 新規使用の発生率を確認するために、同じ情報を収集することができます。画面上部のドロップダウンでアウトカムを ARB 使用に変更し、 ボタンをクリックして詳細を確認します。
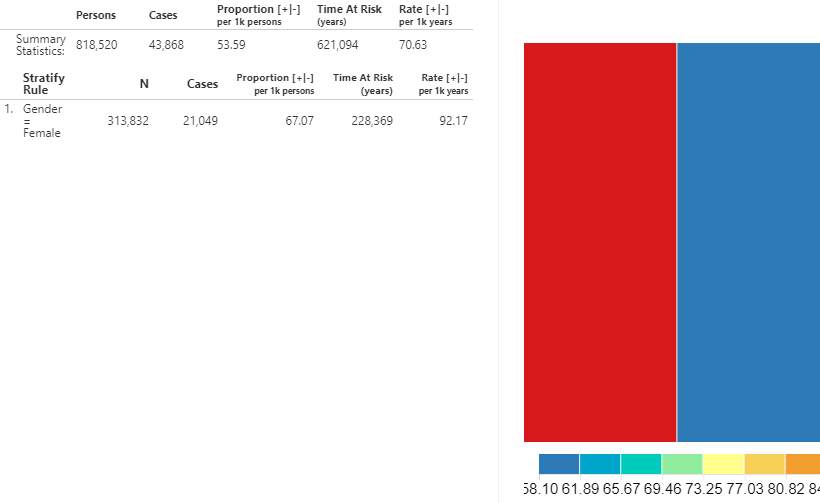
図 11.27: 発生率 - ACEi 曝露中に ARB 処理を受けている新規 ACE阻害薬ユーザー
示されているように、算出されたメトリクスは同じですが、解釈は異なります。なぜなら、入力(ARB 使用)が健康アウトカムではなく薬剤使用量の推定値を参照しているためです。
11.11 まとめ
OHDSI は、データベース全体または対象とするコホートの特性を評価するためのツールを提供しています。
コホートの特徴付けは、インデックス日(ベースライン)前およびインデックス日後(ポストインデックス)の期間に対象とするコホートを記述します。
ATLAS の特徴付けモジュールと OHDSI Methods Libraryは、複数の時間枠の基準特性を算出する機能を提供します。
ATLAS の経路および発生率モジュールは、ポストインデックス期間中の記述統計を提供します。
11.12 演習
前提条件
これらの演習には、ATLAS インスタンスへのアクセスが必要です。http://atlas-demo.ohdsi.org のインスタンスや、アクセス可能なその他のインスタンスを使用できます。
演習 11.1 セレコキシブがリアルワールドでどのように使用されているかを理解したいと思います。 まず、このデータベースがこの薬についてどのようなデータを持っているかを理解したいと思います。 ATLASデータソースモジュールを使用して、セレコキシブに関する情報を検索します。
演習 11.2 セレコキシブの使用者の疾患の自然経過について、より深く理解したいと思います。 365日間のウォッシュアウト期間を使用して、セレコキシブの新規使用者の単純なコホートを作成し(作成方法の詳細については、第10章を参照してください)、ATLASを使用して、併存疾患と薬剤曝露を示すこのコホートの特性を作成します。
演習 11.3 セレコキシブ処方開始後に消化管出血 がどのくらいの頻度で発生するのかに興味があります。192671 (「消化管出血」) またはその下位層に含まれるいずれかのコンセプトの発生として単純に定義される 消化管出血ベントのコホートを作成します。前の演習で定義した曝露コホートを使用して、セレコキシブ開始後のこれらの 消化管出血イベントの発生率を計算してください。
解答例は付録E.7 を参照ください。