第 16 章 臨床的妥当性
著者: Joel Swerdel, Seng Chan You, Ray Chen & Patrick Ryan
物質をエネルギーに変える可能性は、鳥がほとんどいない国で暗闇の中で鳥を撃つようなものだ。アインシュタイン、1935年
OHDSIのビジョンは、「観察研究によって健康と疾病に関する包括的な理解が得られる世界」です。レトロスペクティブデザインは、既存のデータを使用する研究の手段を提供しますが、第14章で説明したように、妥当性のさまざまな側面に対する脅威に満ちている可能性があります。臨床的妥当性をデータ品質や統計的手法から切り離すことは容易ではありませんが、ここでは臨床的妥当性の観点から3つの側面に焦点を当てます。すなわち、医療データベースの特徴、コホートの検証、エビデンスの一般化可能性です。集団レベルの推定の例に戻りましょう(第12章)。「ACE阻害薬は、サイアザイドまたはサイアザイド様利尿薬と比較して血管性浮腫を引き起こすか?」という質問に答えようと試みました。その例では、ACE阻害薬はサイアザイドまたはサイアザイド様利尿薬よりも血管性浮腫を引き起こすことを示唆しました。本章では、「実施された分析はどの程度臨床的意図に一致しているか?」という質問に答えることに専念します。
16.1 医療データベースの特性
私たちが発見したのは、ACE阻害薬の処方と血管性浮腫の関係であり、ACE阻害薬の使用と血管性浮腫の関係ではない可能性があることです。データの質については、すでに前章(第15章)で議論しました。Common Data Model(CDM)に変換されたデータベースの質は、元のデータベースを超えることはできません。ここでは、ほとんどの医療用データベースの特性について取り上げます。OHDSIで使用される多くのデータベースは、保険請求または電子的健康記録(EHR)から派生しています。保険請求とEHRではデータ取得プロセスが異なり、いずれも研究を主な目的としていません。保険請求レコードのデータ要素は、医療提供者から患者に提供されたサービスが、責任当事者による支払い合意を可能にするのに十分な正当性があることを示す、臨床医と保険者間の償還、財務取引を目的として取得されます。EHRのデータ要素は、臨床ケアと管理業務をサポートするために収集され、通常は、特定の医療システム内の医療提供者が、現在のサービスを文書化し、その医療システム内での今後のフォローアップケアに必要な背景情報を提供するために必要だと考える情報のみが反映されます。 それらのデータは患者の完全な病歴を表しているとは限らず、また、複数の医療システムにまたがるデータを統合しているとは限りません。
観察データから信頼性の高いエビデンスを生成するには、患者が治療を求めた瞬間から、その治療を反映するデータが分析に使用される瞬間までのデータの経過を研究者が理解することが有用です。例えば、「薬剤曝露」は、臨床医による処方箋、薬局の調剤記録、病院での処置管理、または患者による服薬歴の自己申告など、さまざまな観察データから推測することができます。データのソースは、どの患者が薬を使用したか、あるいは使用しなかったか、またいつ、どのくらいの期間使用したかについて、私たちが導き出す推論の信頼性に影響を与える可能性があります。データの収集プロセスでは、無料サンプルや市販薬が記録されない場合など、曝露が過小評価される可能性もあります。また、処方箋が患者によって服用されない場合や、処方された薬が患者によって忠実に使用されない場合など、曝露が過大評価される可能性もあります。曝露と結果の確認における潜在的な偏りを理解し、さらに理想的には、これらの測定誤差を定量化して調整することで、入手可能なデータから導き出されるエビデンスの妥当性に対する信頼性を向上させることができます。
16.2 コホート検証
G. Hripcsak and Albers (2017) は、「表現型とは、生物の遺伝的構成から導かれる遺伝子型とは区別される、生物の観察可能な、潜在的に変化する状態の仕様である」と説明しています。表現型という用語は、EHRデータから推測される患者特性にも適用できます。研究者たちは、構造化データと非構造化データの両方から、インフォマティクスの初期からEHRのフェノタイピングを実施してきました。その目的は、EHRの生データ、保険請求データ、またはその他の臨床的に関連するデータに基づいて、対象となるコンセプトについての結論を導き出すことです。フェノタイプアルゴリズム、すなわちフェノタイプを識別または特徴づけるアルゴリズムは、知識工学の最近の研究を含め、ドメインエキスパートや知識エンジニアによって生成されることがあります。また、多様な形態の機械学習を通じて生成されることもあります。
この説明は、臨床的妥当性を検討する際に強化すべきいくつかの属性を強調しています。1)観察可能なもの(したがって、観察データに捕捉可能なもの)について話していることが明確であること。2)表現型仕様には時間という概念が含まれていること(人の状態は変化しうるため)。3)表現型アルゴリズムは、意図の実現であるのに対し、表現型は意図そのものであるという区別があること。
OHDSIでは、一定期間にわたって1つ以上の適格基準を満たす人々の集合を定義するために、「コホート」という用語を採用しています。「コホート定義」は、観察データベースに対してコホートを具体化するために必要な論理を表します。この点において、コホート定義(または表現型アルゴリズム)は、表現型を表すことを目的としたコホートを生成するために使用されます。
臨床的特性、集団レベルの影響の推定、患者レベルの予測など、ほとんどの観察分析では、研究プロセスの一部として1つまたは複数のコホートを確立する必要があります。これらの分析によって得られたエビデンスの妥当性を評価するには、各コホートについて、次のような質問を考慮する必要があります。コホート定義と利用可能な観察データに基づいてコホート内で特定された対象者は、真に表現型に属する対象者をどの程度正確に反映しているでしょうか?
集団レベルの推定の例(第12章)「ACE阻害薬は、サイアザイドまたはサイアザイド様利尿薬と比較して血管性浮腫を引き起こすでしょうか?」に戻ると、3つのコホートを定義する必要があります。ACE阻害薬の新規ユーザー、サイアザイド利尿薬の新規ユーザー、血管性浮腫を発症した人の3つです。ACE阻害薬またはサイアザイド系利尿薬の使用がすべて完全に把握されているため、過去の(観察されていない)使用を懸念することなく、最初の観察された曝露によって「新規ユーザー」を特定できると、どの程度確信できるでしょうか?ACE阻害薬の薬物曝露記録がある人は実際にその薬物に曝露されており、薬物曝露記録のない人は実際に曝露されていないと、自信を持って推論できるでしょうか?「ACE阻害薬使用」の状態に分類される期間を定義する際に、不確実性はないでしょうか。薬剤の開始時にコホートへの組入れを推測する場合、または薬剤の中止時のコホートからの離脱を推測する場合のいずれにおいても不確実性はないでしょうか。「血管性浮腫」の症状発現記録を持つ患者は、実際に他の皮膚アレルギー反応と区別される皮膚下の急速な腫れを経験しているでしょうか。血管性浮腫を発症した患者のうち、コホート定義に基づいてこれらの臨床例を特定するために使用された、観察データを生み出すような医療措置を受けた患者の割合はどの程度でしょうか? 薬剤誘発の可能性がある血管性浮腫事象を、食物アレルギーやウイルス感染など、他の原因によって生じることが知られている事象からどの程度明確に区別できるでしょうか? 曝露状況と結果の発生率との間に時間的な関連性を導くことに自信が持てるほど、疾患の発症が十分に把握されているでしょうか?こうした疑問に答えることが、臨床的妥当性の核心です。
本章では、コホート定義の妥当性を検証する方法について説明します。まず、コホート定義の妥当性を測定するために使用される評価基準について説明します。次に、これらの評価基準を推定する2つの方法について説明します。1)原資料の検証による臨床判定、2)診断予測モデリングを使用する半自動化された方法であるPheValuator。
16.2.1 コホート評価指標
対象コホートの定義が確定すると、その妥当性を評価することができます。妥当性を評価する一般的なアプローチは、定義されたコホートの一部またはすべてを基準となる「ゴールドスタンダード」と比較し、その結果を混同行列(2×2分割表)で表現することです。混同行列は、ゴールドスタンダードの分類とコホート定義内の適格性に基づいて対象を層別化します。図 16.1 は、混同行列の要素を示しています。

図 16.1: 混同行列
コホート定義による真の結果と偽の結果は、その定義をある集団に適用することで決定されます。定義に含まれる人は、その健康状態を陽性と見なされ、「真」とラベル付けされます。コホート定義に含まれない人々は、健康状態が陰性と見なされ、「偽」とラベル付けされます。コホート定義で考慮される個人の健康状態の絶対的な真実は非常に判断が難しいですが、参照用ゴールドスタンダードを確立する方法は複数あり、そのうちの2つは本書の後半で説明します。使用する手法に関わらず、これらの人々に対するラベル付けは、コホート定義で説明したものと同じです。 表現型指定の二値表示におけるエラーに加えて、健康状態のタイミングも不正確である可能性があります。例えば、コホート定義が表現型に属する人々を正しくラベル付けしている場合でも、その定義が、健康状態ではない人が健康状態にある人となった日時を不正確に指定している可能性があります。このエラーは、効果測定値として生存分析結果(例えば、ハザード比)を用いる研究にバイアスを加えることになります。 次のステップは、ゴールドスタンダードとコホート定義の一致度を評価することです。ゴールドスタンダード法とコホート定義の両方で「真」と判定された人を「真陽性」と呼びます。ゴールドスタンダード法で「偽」と判定され、コホート定義で「真」と判定された人を「偽陽性」と呼びます。つまり、コホート定義では、これらの人は疾患を有していないにもかかわらず、疾患を有していると誤分類されています。ゴールドスタンダード法とコホート定義の両方で「偽」と判定された人は「真の陰性」と呼ばれます。ゴールドスタンダード法で「真」と判定され、コホート定義で「偽」と判定された人は「偽の陰性」と呼ばれ、すなわち、コホート定義がこれらの人を、実際にはその人が表現型に属しているにもかかわらず、その状態に該当しないと誤って分類したことになります。混同行列の4つのセルのカウント値を用いれば、ある集団における表現型の状態を分類する際のコホート定義の精度を定量化することができます。コホート定義の性能を測定するための標準的な性能指標があります。
コホート定義の感度 - 集団内の表現型に真に属する人のうち、コホート定義に基づいて健康アウトカムを持つと正しく特定された人の割合はどの程度か?これは以下の式で求められます。
感度 = 真陽性 / (真陽性 + 偽陰性)
コホート定義の特異度 - 集団内の表現型に属さない人のうち、コホート定義に基づいて健康アウトカムを持たないと正しく特定された人の割合はどの程度か?これは以下の式で求められます。
特異度 = 真の陰性数 / (真の陰性数 + 偽陽性数)
コホート定義の陽性的中率(PPV) - コホート定義によって健康状態にあると特定された人のうち、実際にその健康状態にある人の割合はどの程度か。これは以下の式で求められます。
PPV = 真の陽性数 / (真の陽性数 + 偽陽性数)
コホート定義の陰性的中率(NPV) - コホート定義によって特定された健康状態ではないとされた人のうち、実際にその表現型に属さない人の割合はどの程度か?これは以下の式で求められます。
NPV = 真陰性 / (真陰性 + 偽陰性)
これらの指標の満点は100%です。観察データの性質上、満点は通常、標準からかけ離れた値となります。 Rubbo et al. (2015) は、心筋梗塞のコホート定義を検証した研究をレビューしました。彼らが調査した33件の研究のうち、PPVの満点を得たコホート定義は1つのデータセットにおける1つのコホート定義のみでした。全体として、33件の研究のうち31件がPPV ≥ 70%と報告しています。しかし、33件の研究のうち感度を報告しているのは11件のみ、特異度を報告しているのは5件のみでした。PPVは感度、特異度、有病率の関数です。有病率の値が異なるデータセットでは、感度と特異度を一定に保ったままPPVの値が異なるものとなります。感度と特異度がなければ、不完全なコホート定義によるバイアスを補正することはできません。さらに、健康状態の誤分類は差異があるかもしれません。つまり、比較群と比較してある集団においてコホート定義が異なる結果となる場合、または両方の比較群においてコホート定義が同様の結果となる場合、差異がない場合です。以前のコホート定義の検証研究では、潜在的な差異のある誤分類をテストしていませんが、これは効果推定値に強い偏りをもたらす可能性があります。
コホート定義の性能指標が確立された後は、これらの定義を使用する研究の結果を調整するためにそれらを活用することができます。理論的には、これらの推定値の測定誤差を用いて研究結果を調整することは十分に確立されています。しかし実際には、パフォーマンス特性を入手することが困難であるために、このような調整はほとんど考慮されません。ゴールドスタンダードを決定するために使用される方法は、このセクションの後半の部分で説明されています。
16.3 ソースレコード検証
コホートの定義を検証するために一般に用いられる方法は、ソースレコードの検証による臨床判定です。これは、対象とする臨床状態または特徴を適切に分類するのに十分な知識を有する1人または複数の専門家の下で、個人の記録を徹底的に調査するものです。一般にカルテのレビューは以下の手順に従って行われます。
カルテレビューを含む調査を実施するため、必要に応じて現地のIRB(Institutional Review Board)および/または関係者から許諾を得る。
評価対象のコホートの定義を用いてコホートを生成する。コホート全体を審査するのに十分なリソースがない場合は、対象者のサブセットをサンプリングし、手作業で審査する。
対象者の記録をレビューするのに十分な臨床的専門知識を有する1人または複数の人物を特定する。
対象者が対象とする臨床状態または特性について陽性または陰性であるかを判定するためのガイドラインを決定する。
臨床専門家がサンプル内の対象者について、利用可能なすべてのデータを検証および判定し、各対象者が表現型に属するかどうかを分類する。
コホートの定義分類や臨床判定分類に従って対象者を混同行列に分類し、収集したデータから可能な性能特性を算出する。
チャートレビューの結果は、通常、1つの性能特性である陽性的中率(PPV)の評価に限定されます。これは、評価対象のコホート定義によって、望ましい状態または特性を持つと見なされる集団のみが生成されるためです。したがって、コホートのサンプル内の各人は、臨床判定に基づいて真陽性または偽陽性のいずれかに分類されます。集団全体の表現型内のすべての人(コホート定義で特定されない人を含む)に関する知識がなければ、偽陰性を特定することはできず、それにより残りの性能特性を生成するための混乱行列の残りの部分を埋めることはできません。集団全体の表現型のすべての人を特定する可能性のある方法としては、データベース全体のチャートレビューが考えられますが、これは一般に、対象となる集団が小規模でない限りは実行不可能です。あるいは、腫瘍レジストリ(下記参照)など、真の症例がすべてフラグ付けされ、判定済みの包括的な臨床レジストリを利用する方法もあります。あるいは、コホート定義に該当しない人々をサンプリングし、予測される陰性のサブセットを作成し、その後、上記の チャートレビューのステップ3から6を繰り返して、これらの患者が本当に臨床的に関心のある状態や特徴を欠いているかどうかを確認することで、真の陰性または偽陰性を特定することができます。これにより、陰性的中率(NPV)を推定することができ、表現型有病率の適切な推定値が利用可能であれば、感度と特異度を推定することができます。
ソース記録の検証による臨床判定には、多くの限界があります。前述の通り、PPVのような単一の指標の評価だけでも、カルテのレビューは非常に時間とリソースを要するプロセスになり得ます。この限界は、完全な混同行列を記入するために集団全体を評価する実用性を著しく妨げます。さらに、上記のプロセスには複数のステップがあり、研究結果にバイアスが生じる可能性があります。例えば、EHRで記録が均等にアクセスできない場合、EHRが存在しない場合、または個々の患者の同意が必要な場合、評価対象のサブセットは真にランダムではなく、サンプリングや選択バイアスが入り込む可能性があります。さらに、手動による判定はヒューマンエラーや誤分類の影響を受けやすく、完璧に正確な評価基準とは言えない可能性があります。個人の記録のデータが曖昧であったり、主観的であったり、質が低かったりするために、臨床審査員の間で意見が分かれることもよくあります。多くの研究では、このプロセスでは多数決による合意決定が採用されており、評価者間の意見の相違を反映しない二値分類が個人に対して行われています。
16.3.1 ソースレコード検証の例
コロンビア大学アーヴィング医療センター(CUIMC)による研究では、米国国立がん研究所(NCI)の実現可能性調査の一環として、複数の癌に関するコホート定義の検証が行われました。この研究から、カルテレビューによるコホート定義の検証プロセス例が提供されています。この例では、前立腺癌の検証プロセスは以下の通りです。
OHDSI がんフェノタイピング研究のための提案を提出し、IRB の承認を取得しました。
前立腺がんの集団定義を開発:ボキャブラリを調査するために ATHENA と ATLAS を使用し、前立腺悪性腫瘍(コンセプトID 4163261)の発生状態の患者をすべて含み、前立腺二次新生物(コンセプトID 4314337)または前立腺非ホジキンリンパ腫(コンセプトID 4048666)を除く集団定義を作成しました。
ATLAS を使用して生成されたコホートから、手動レビュー用に 100 人の患者を無作為に抽出し、マッピングテーブルを使用して各 PERSON_ID を患者 MRN にマッピングしました。100 人の患者は、PPV のパフォーマンス指標について、望ましいレベルの統計的精度を達成するよう抽出されました。
無作為に抽出されたサブセット内の人が真陽性か偽陽性かを判断するために、入院患者と外来患者の両方のさまざまな EHR の記録を手動で確認しました。
手動レビューと臨床判定は1人の医師によって実施されました(ただし、将来、理想的には合意と評価者間の信頼性を評価するために、より多くのレビュー担当者によってより厳密な検証研究が行われることになります)。
参照基準の決定は、入手可能な電子的な患者記録のすべてに記録されている臨床記録、病理報告書、検査、投薬、処置に基づいて行われました。
患者は、1)前立腺がん、2)前立腺がんではない、3)判断不能、のいずれかに分類されました。
前立腺がん/(前立腺がんではない + 判断不能)という計算式で、PPVの控えめな推定値が算出されました。
次に、腫瘍登録を追加のゴールドスタンダードとして使用し、CUIMC 全体の集団における基準標準を特定しました。腫瘍レジストリにおいて、コホート定義にり正確に特定された人数と特定されなかった人数を数え、これらの値を真陽性および偽陰性として感度を推定しました。
推定された感度、陽性適中率、および有病率を用いて、このコホート定義の特異度を推定することができました。前述の通り、このプロセスは時間を要し、労力を要するものでした。各コホート定義を個別に評価し、また、すべての性能指標を特定するために、手作業によるチャートレビューとCUIMC腫瘍レジストリとの照合を行う必要があったためです。IRBの承認プロセス自体は、腫瘍レジストリへのアクセスを得るための迅速審査にもかかわらず数週間を要し、手作業によるカルテレビューのプロセス自体にもさらに数週間を要しました。
Rubbo et al. (2015) らによる心筋梗塞(MI)コホート定義の妥当性評価のレビューでは、研究で使用されたコホート定義、および妥当性評価の方法と報告された結果に著しい異質性があることが判明しました。著者らは、急性心筋梗塞については、利用可能なゴールドスタンダードのコホート定義はないと結論づけました。また、そのプロセスは費用と時間がかかることも指摘しています。この限界により、ほとんどの研究では検証のサンプルサイズが小さくなり、性能特性の推定値に大きなばらつきが生じることとなりました。また、33件の研究のうち、すべての研究で陽性適中率が報告されていた一方で、感度が報告されていたのは11件の研究のみ、特異度が報告されていたのは5件の研究のみでした。前述の通り、感度と特異度の推定値がなければ、誤分類バイアスに対する統計的補正を行うことはできないのです。
16.4 PheValuator
OHDSIコミュニティは、診断予測モデルを用いてゴールドスタンダードを構築する別のアプローチを開発しました(Swerdel, Hripcsak, and Ryan 2019)。一般的な考え方は、臨床医がソースレコードの検証で実施するのと同様の方法で健康アウトカムの確認をエミュレートすることですが、規模を拡大して適用できる自動化された方法です。このツールは、オープンソースのRパッケージであるPheValuatorとして開発されています58。PheValuatorは、Patient Level Predictionパッケージの機能を使用しています。
プロセスは以下の通り:
極めて特異的な(「xSpec」)コホートを作成する:診断予測モデルのトレーニング時にノイズの多い陽性ラベルとして使用される、対象となる結果を持つ可能性が極めて高い人物のセットを決定する。
極めて感度の高い(「xSens」)コホートを作成する:結果が得られる可能性のある人をすべて含むべき集団を決定します。このコホートは、その逆数(結果が得られないと確信できる人の集合)を特定するために使用され、診断予測モデルのトレーニング時にノイズを含むネガティブラベルとして使用されます。
xSpecとxSensコホートを使用して予測モデルを適合:第13章で説明したように、幅広い患者の特徴量を予測因子として使用してモデルを適合し、その人物がxSpecコホート(結果が出ると考えられる人々)に属するのか、あるいはxSensコホート(結果が出ないと考える人々)の逆数に属するのかを予測することを目指します。
コホート定義の性能を評価するために使用される、除外された人々のセットに対して、結果の確率を推定するために適合されたモデルを適用します:モデルからの予測因子セットを個人のデータに適用して、その個人が表現型に属する確率を予測します。これらの予測を確率的なゴールドスタンダードとして使用します。
コホート定義の性能特性を評価します:予測確率をコホート定義の二値分類と比較します(混同行列のテストコンディション)。テストコンディションと真のコンディションの推定値を使用して、混同行列を完全に作成し、感度、特異度、予測値など、性能特性の全体的なセットを推定する。
このアプローチを使用する際の主な限界は、健康アウトカムのある人の確率の推定がデータベース内のデータに制限されることです。データベースによっては、臨床医のメモなどの重要な情報が利用できない場合があります。
診断予測モデリングでは、疾患を持つ人と持たない人を識別するモデルを作成します。患者レベルの予測(第13章)で説明されているように、予測モデルは対象コホートと結果コホートを使用して開発されます。対象コホートには、健康アウトカムを持つ人と持たない人が含まれます。結果コホートは、対象コホートの中で健康アウトカムを持つ人を特定します。PheValuator プロセスでは、予測モデルのアウトカムコホートを決定するために、非常に特異的なコホート定義である「xSpec」コホートを使用します。xSpec コホートは、定義を使用して、対象疾患の罹患確率が極めて高い人を見つけ出します。xSpec コホートは、対象の健康アウトカムについて複数のコンディション発生記録を持つ人々として定義されることがあります。例えば、心房細動の場合、心房細動の診断コードが10件以上ある人を対象とします。急性心筋梗塞のような急性疾患の場合は、心筋梗塞の発生を5件とし、入院による発生が少なくとも2件あることを要件に含めることができます。予測モデルの対象コホートは、対象とする健康アウトカムの発生可能性が低い人々とxSpecコホートの人々を合わせたものから構築されます。対象となる健康アウトカムの可能性が低い人を決定するために、データベース全体からサンプルを抽出し、通常はxSpecコホートを定義する際に使用されるコンセプトを含むレコードを持つ人物を除外することで、表現型に属する可能性を示唆する何らかの証拠を持つ人を除外します。この方法には限界があり、xSpecコホートの人物は、その疾患を持つ他の人々とは異なる特性を持っている可能性があります。また、これらの人物は、初期診断後の観察期間が平均的な患者よりも長かった可能性もあります。LASSOロジスティック回帰を使用して、確率的なゴールドスタンダードを生成するための予測モデルを作成します(Suchard et al. 2013)。このアルゴリズムは簡潔なモデルを生成し、通常、データセット全体に存在する可能性がある共線性の共変量の多くを削除します。PheValuatorソフトウェアの現行バージョンでは、アウトカムの状態(はい/いいえ)は、その人に関するすべてのデータ(すべての観察期間)に基づいて評価され、コホート開始日の正確性は評価されません。
16.4.1 PheValuatorによる検証例
PheValuator を使用して、急性心筋梗塞を患ったことがある人を特定する必要がある研究で使用されるコホート定義の完全なパフォーマンス特性を評価することがあります。
PheValuator を使用して心筋梗塞のコホート定義をテストする手順は以下の通りです。
ステップ 1: xSpec コホートの定義
MIの可能性が高いものを特定します。心筋梗塞またはその下位層のコンセプトを持つコンディション発生レコードで、5日以内の入院ビジットから1回以上のMI発生が記録され、365日以内の患者レコードで4回以上のMI発生が記録されているものが必要とされました。図 16.2 は、ATLASにおけるMIのこのコホート定義を示しています。
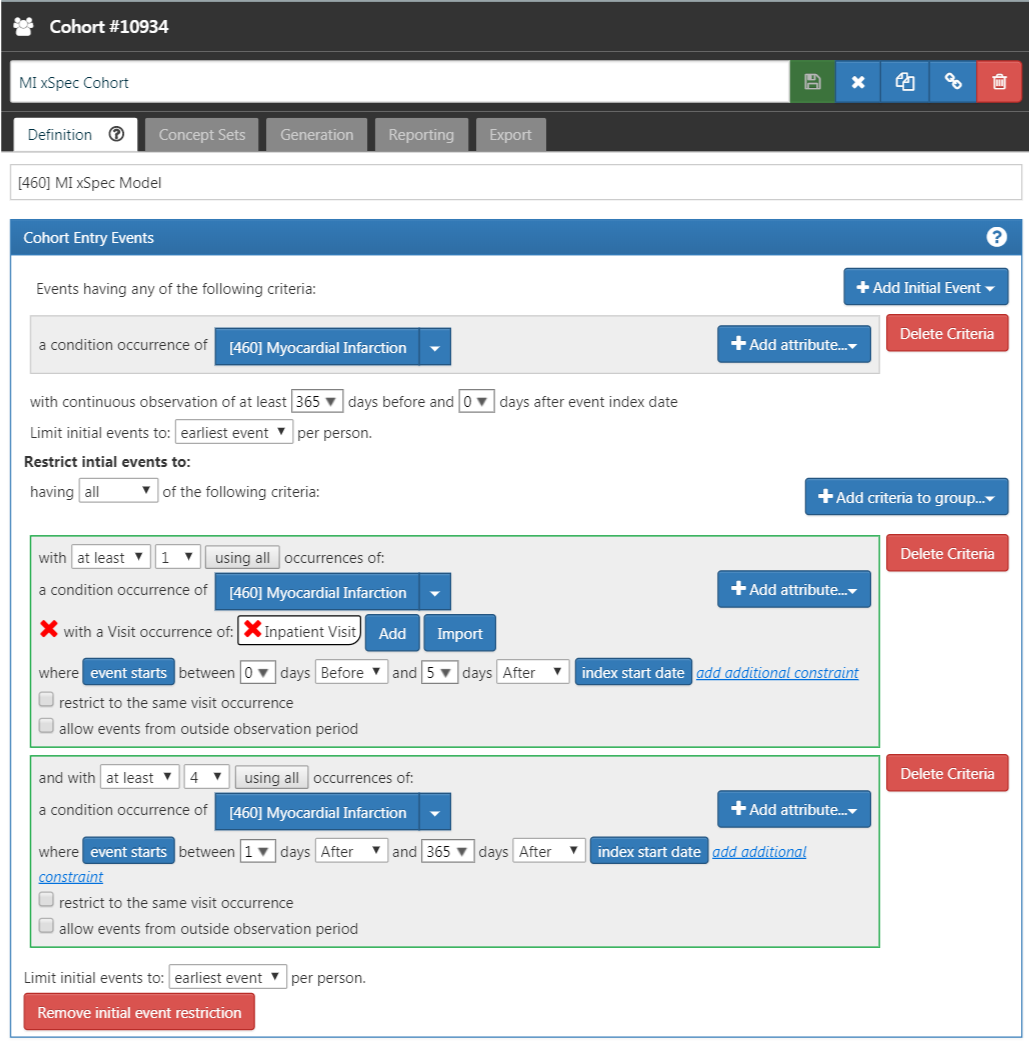
図 16.2: 心筋梗塞の極めて特異的なコホート定義(xSpec)
ステップ 2: xSens コホートの定義
次に、極めて感度の高いコホート(xSens)を開発します。このコホートは、MIについては、病歴の任意の時点で心筋梗塞のコンセプトを含む少なくとも1つの疾患発生記録を持つ人々として定義することができます。図 16.3 は、ATLASにおけるMIのxSensコホート定義を示しています。
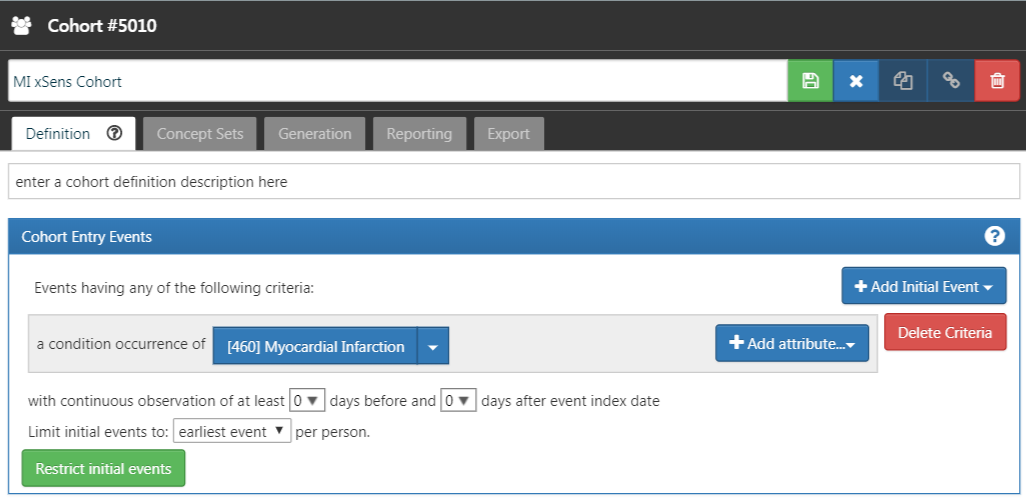
図 16.3: 心筋梗塞の極度に感度の高いコホート定義(xSens)
ステップ 3: 予測モデルの適合
関数createPhenoModelは、評価コホートにおいて対象の健康アウトカムとなる確率を評価するための診断予測モデルを開発します。この関数を使用するには、ステップ1と2で開発したxSpecコホートとxSensコホートを利用します。xSpecコホートは、関数のxSpecCohortパラメータとして入力します。xSens コホートは、モデリングプロセスで使用されるターゲットコホートから除外すべきであることを示すために、exclCohortパラメータとして関数に入力します。この除外方法を使用すると、健康アウトカムの可能性が低い人物を特定することができます。このグループを「ノイズネガティブ」な人々、すなわち、健康アウトカムがネガティブである可能性が高いが、健康結果がポジティブである人も若干含まれる可能性があるグループと考えることができます。また、xSensコホートを関数のprevCohortパラメータとして使用することもできます。このパラメータは、母集団における健康結果のおおよその有病率を決定するプロセスで使用されます。通常、データベースから抽出した多数のランダムサンプルから、データベースにおける結果の有病率とほぼ同等の割合で、対象とするアウトカムを持つ人を含む人々の集団が生成されるはずです。ここで説明した方法を用いると、人々のランダムサンプルはもはや存在せず、結果を持つ人々と結果を持たない人々の割合をリセットして予測モデルを再キャリブレーションする必要があります。
xSpec コホートを定義するために使用されたすべてのコンセプトは、モデリングプロセスから除外する必要があります。これを実行するには、excludedConceptsパラメータをxSpec定義で使用されたコンセプトのリストに設定します。例えば、MIの場合、心筋梗塞のコンセプトと、そのすべての下位層のコンセプトを使用して、ATLASでコンセプトセットを作成します。この例では、excludedConceptsパラメータを4329847(心筋梗塞のコンセプトID)に設定し、さらにaddDescendantsToExcludeパラメータもTRUEに設定して、除外されたコンセプトの下位層も除外されるようにします。
モデリングプロセスに含まれる人物の特徴を指定するために使用できるパラメータがいくつかあります。モデリングプロセスに含まれる人物の年齢を指定するには、lowerAgeLimitをモデルで希望する年齢の下限に、upperAgeLimitを上限に設定します。計画中の研究のコーホート定義を特定の年齢グループに対して作成する場合は、この設定を行うとよいでしょう。例えば、研究で使用するコホート定義が小児の1型糖尿病である場合、診断予測モデルの開発に使用する年齢を、例えば5歳から17歳に限定したいと考えるかもしれません。そうすることで、テスト対象のコホート定義によって選択された人々により密接に関連する可能性が高い特徴量を持つモデルが作成されます。また、genderパラメータを男性または女性のコンセプト ID に設定することで、モデルに含める性別を指定することもできます。デフォルトでは、パラメータは男性と女性の両方を含めるように設定されています。この機能は、前立腺がんなどの性別特有の健康アウトカムに役立つ場合があります。startDateおよびendDateパラメータをそれぞれ日付範囲の下限および上限に設定することで、その人物のレコードにおける最初のビジットに基づいて、人物の包含期間を設定することができます。最後に、mainPopnCohortパラメータを使用して、対象および結果コホート内のすべての人物が選択される大規模な母集団コホートを指定することができます。ほとんどの場合、このパラメータは0に設定され、対象およびアウトカムコホート内の人物の選択に制限がないことを示します。ただし、このパラメータがより優れたモデルの構築に役立つ場合もあります。例えば、健康アウトカムの発生率が極めて低い場合、おそらく0.01%以下の場合です。 次の例を参照してください:
setwd("c:/temp")
library(PheValuator)
connectionDetails <- createConnectionDetails(
dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
phenoTest <- createPhenoModel(
connectionDetails = connectionDetails,
xSpecCohort = 10934,
cdmDatabaseSchema = "my_cdm_data",
cohortDatabaseSchema = "my_results",
cohortDatabaseTable = "cohort",
outDatabaseSchema = "scratch.dbo", #書き込み権限が必要
trainOutFile = "5XMI_train",
exclCohort = 1770120, #xSens コホート
prevCohort = 1770119, #有病率決定のコホート
modelAnalysisId = "20181206V1",
excludedConcepts = c(312327, 314666),
addDescendantsToExclude = TRUE,
cdmShortName = "myCDM",
mainPopnCohort = 0, #全人口を使用
lowerAgeLimit = 18,
upperAgeLimit = 90,
gender = c(8507, 8532),
startDate = "20100101",
endDate = "20171231")この例では、「my_results」データベースで定義されたコホートを使用し、コホートテーブルの場所(cohortDatabaseSchema、cohortDatabaseTable - 「my_results.cohort」)と、モデルにコンディション、薬物曝露などを知らせる場所(cdmDatabaseSchema - 「my_cdm_data」)を指定しました。モデルに含まれる対象者は、CDMにおける初回ビジット日が2010年1月1日から2017年12月31日の間の人です。また、xSpecコホートを作成するために使用されたコンセプトID 312327、314666、およびそれらの下位層は、除外しています。これらの初回ビジット時の年齢は18歳から90歳の間です。上記のパラメータを使用した場合、このステップで出力される予測モデルの名前は次のようになります。「c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds」
ステップ 4: 評価コホートの作成
関数createEvalCohortは、パッケージ関数applyModelを使用して、対象とする健康アウトカムの予測確率をそれぞれ持つ多数の人々からなるコホートを作成します。この関数では、xSpecコホートを指定する必要があります(xSpecCohortパラメータをxSpecコホートIDに設定します)。また、前のステップで行ったように、評価コホートに含まれる人々の特性を指定することもできます。これには、下限および上限の年齢(それぞれ、 lowerAgeLimitおよびupperAgeLimit引数として年齢を設定)、性別(genderパラメータを男性および/または女性のコンセプトIDに設定)、開始日および終了日(それぞれstartDateおよびendDate引数として日付を設定)、および対象とする母集団から対象者を選択する際に使用する母集団のIDとしてmainPopnCohortを設定することによって指定できます。
例えば:
setwd("c:/temp")
connectionDetails <- createConnectionDetails(
dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
evalCohort <- createEvalCohort(
connectionDetails = connectionDetails,
xSpecCohort = 10934,
cdmDatabaseSchema = "my_cdm_data",
cohortDatabaseSchema = "my_results",
cohortDatabaseTable = "cohort",
outDatabaseSchema = "scratch.dbo",
testOutFile = "5XMI_eval",
trainOutFile = "5XMI_train",
modelAnalysisId = "20181206V1",
evalAnalysisId = "20181206V1",
cdmShortName = "myCDM",
mainPopnCohort = 0,
lowerAgeLimit = 18,
upperAgeLimit = 90,
gender = c(8507, 8532),
startDate = "20100101",
endDate = "20171231")この例では、パラメータにより、関数がモデルファイル「c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds」を使用して評価コホートファイル「c:/temp/lr_results_5XMI_eval_myCDM_ePPV0.75_20181206V1.rds」を生成することが指定されています。このステップで作成されたモデルファイルと評価用コホートファイルは、次のステップで提供されるコホート定義の評価に使用されます。
ステップ 5: コホート定義の作成とテスト
次のステップは、評価対象のコホート定義を作成し、テストすることです。 望ましい性能特性は、対象とする研究課題に対処するためのコホートの使用目的によって異なる場合があります。 特定の研究課題には非常に感度の高いアルゴリズムが必要となる場合もありますが、より特異的なアルゴリズムが必要となる場合もあります。 PheValuator を使用してコホート定義の性能特性を決定するプロセスを図 16.4 に示します。
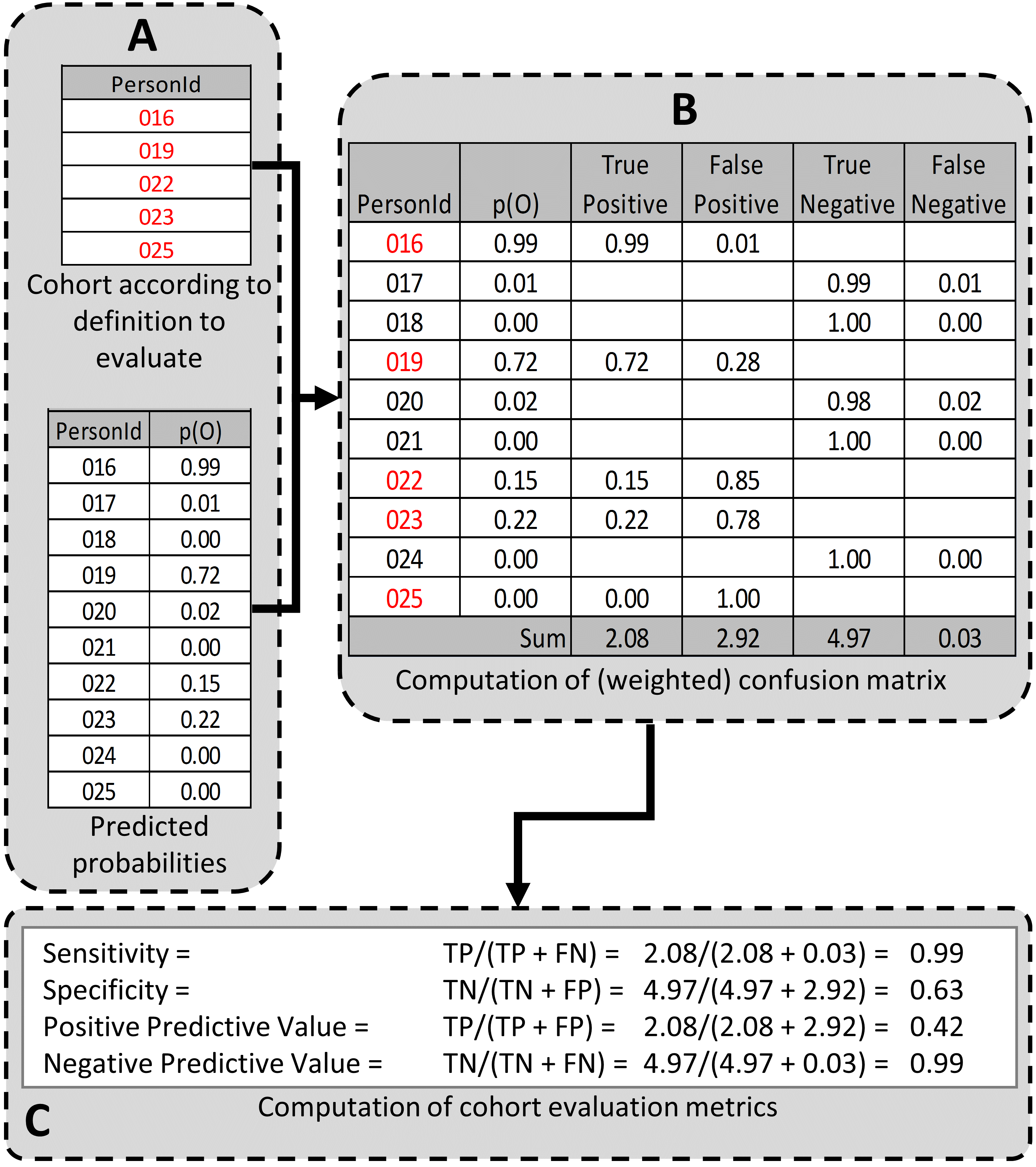
図 16.4: PheValuatorを使用したコホート定義の性能特性の決定 p(O) = 結果の確率; TP = 真陽性; FN = 偽陰性; TN = 真陰性; FP = 偽陽性
図 16.4 のパートAでは、私たちは、テスト対象となるコホート定義の人物を調査し、コホート定義に含まれる評価コホート(前のステップで作成)の人物(人物ID 016、019、022、023、025)と、含まれない評価コホートの人物(人物ID 017、018、020、021、024)を見つけました。これらの対象者/非対象者それぞれについて、予測モデルを使用して健康アウトカムの確率を事前に決定していました(p(O))。
真陽性、真陰性、偽陽性、偽陰性の値は、以下のように推定しました(図 16.4 のパートB):
コホート定義に評価コホートに属する人物が含まれていた場合、すなわち、コホート定義がその人物を「陽性」とみなした場合。健康アウトカムの予測確率は、その人物が真陽性に寄与するカウント数の期待値を示し、1から確率を引いた値は、その人物が偽陽性に寄与するカウント数の期待値を示します。人物ごとのすべてのカウント数の期待値を合計します。例えば、PersonId 016 の健康結果の存在の予測確率は 99% であり、0.99 が真陽性(カウントの期待値に 0.99 を追加)に追加され、1.00 – 0.99 = 0.01 が偽陽性(0.01 の期待値)に追加されました。この処理は、コホート定義に含まれる評価コホートの全人物(すなわち、PersonIds 019、022、023、および 025)に対して繰り返されました。
同様に、コホート定義が評価コホートに属する人物を含んでいなかった場合、すなわちコホート定義がその人物を「陰性」とみなした場合、その人物の表現型に対する予測確率を1から引いた値が「真陰性」に寄与するカウントの期待値となり、それに加えられます。また、並行して、表現型に対する予測確率は「偽陰性」に寄与するカウントの期待値となり、それに加えられます。例えば、PersonId 017 の健康アウトカムの存在に対する予測確率は 1%(および、対応する健康アウトカムの不在は 99%)であり、1.00 – 0.01 = 0.99 が真陰性に、0.01 が偽陰性に追加されました。この手順を、コホート定義に含まれない評価コホートの全対象者(すなわち、PersonIds 018、020、021、024)に対して繰り返しました。
これらの値を評価コホート内の全対象者について加算した後、4つのセルに各セルの期待値を記入し、感度、特異度、陽性適中率などのPAの性能特性の点推定値を作成することができました(図 16.4 のパートC)。これらの期待セルカウントは、推定値の分散を評価するために使用することはできず、点推定値のみに使用できることを強調しておきます。この例では、感度、特異度、陽性適中率、陰性適中率はそれぞれ0.99、0.63、0.42、0.99でした。
コホート定義の性能特性を決定するには、関数testPhenotypeを使用します。この関数は、モデルと評価コホートを作成した前の2つのステップからの出力を使用します。この例では、createPhenoModel関数からのRDSファイル出力である「c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds」にmodelFileNameパラメータを設定します。この例では、createEvalCohort 関数から出力された RDS ファイル「c:/temp/lr_results_5XMI_eval_myCDM_ePPV0.75_20181206V1.rds」に結果ファイル名パラメータを設定します。研究で使用するコホート定義をテストするために、cohortPhenoをそのコホート定義のコホート ID に設定します。phenTextパラメータを、コホート定義として人が読める説明文で設定します。例えば、「MI発症、入院患者」などです。testTextパラメータを、xSpec定義の人が読める説明文で設定します。例えば、「5 x MI」などです。このステップの出力は、テストされたコホート定義の性能特性を含むデータフレームです。
cutPointsパラメータの設定は、性能特性の結果を導き出すために使用される値のリストです。性能特性は通常、図 16.1 で説明されているように「期待値」を使用して計算されます。期待値に基づく性能特性を取得するには、cutPointsパラメータのリストに「EV」を含めます。また、特定の予測確率、すなわちカットポイントに基づく性能特性を確認したい場合もあります。例えば、予測確率が0.5以上の場合は健康状態が良好と見なされ、予測確率が0.5未満の場合は健康状態が不良と見なされる場合の性能特性を確認したい場合、cutPointsパラメータのリストに「0.5」を追加します。例えば:
setwd("c:/temp")
connectionDetails <- createConnectionDetails(
dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
phenoResult <- testPhenotype(
connectionDetails = connectionDetails,
cutPoints = c(0.1, 0.2, 0.3, 0.4, 0.5, "EV", 0.6, 0.7, 0.8, 0.9),
resultsFileName =
"c:/temp/lr_results_5XMI_eval_myCDM_ePPV0.75_20181206V1.rds",
modelFileName =
"c:/temp/lr_results_5XMI_train_myCDM_ePPV0.75_20181206V1.rds",
cohortPheno = 1769702,
phenText = "All MI by Phenotype 1 X In-patient, 1st Position",
order = 1,
testText = "MI xSpec Model - 5 X MI",
cohortDatabaseSchema = "my_results",
cohortTable = "cohort",
cdmShortName = "myCDM")この例では、予測閾値の幅広い範囲(cutPoints)が提供されており、期待値(「EV」)も含まれています。パラメータ設定を前提として、このステップからの出力は、期待値計算を用いた場合と同様に、各予測閾値におけるパフォーマンス特性(感度、特異度など)を提供します。評価には、前のステップで作成された評価コホートの予測情報が使用されます。このステップで作成されたデータフレームは、検証用にCSVファイルに保存することができます。 このプロセスを使用すると、表 16.1 は、5つのデータセットにおけるMIの4つのコホート定義の性能特性を示します。Cutrona氏らによって評価されたものと同様のコホート定義「>=1 X HOI, In-Patient」では、平均PPVは67%(範囲:59%~74%)であることが分かりました。
| Phenotype Algorithm | Database | Sens | PPV | Spec | NPV |
|---|---|---|---|---|---|
| >=1 X HOI | CCAE | 0.761 | 0.598 | 0.997 | 0.999 |
| Optum1862 | 0.723 | 0.530 | 0.995 | 0.998 | |
| OptumGE66 | 0.643 | 0.534 | 0.973 | 0.982 | |
| MDCD | 0.676 | 0.468 | 0.990 | 0.996 | |
| MDCR | 0.665 | 0.553 | 0.977 | 0.985 | |
| >= 2 X HOI | CCAE | 0.585 | 0.769 | 0.999 | 0.998 |
| Optum1862 | 0.495 | 0.693 | 0.998 | 0.996 | |
| OptumGE66 | 0.382 | 0.644 | 0.990 | 0.971 | |
| MDCD | 0.454 | 0.628 | 0.996 | 0.993 | |
| MDCR | 0.418 | 0.674 | 0.991 | 0.975 | |
| >=1 X HOI, In-Patient | CCAE | 0.674 | 0.737 | 0.999 | 0.998 |
| Optum1862 | 0.623 | 0.693 | 0.998 | 0.997 | |
| OptumGE66 | 0.521 | 0.655 | 0.987 | 0.977 | |
| MDCD | 0.573 | 0.593 | 0.995 | 0.994 | |
| MDCR | 0.544 | 0.649 | 0.987 | 0.980 | |
| 1 X HOI, In-Patient, 1st Position | CCAE | 0.633 | 0.788 | 0.999 | 0.998 |
| Optum1862 | 0.581 | 0.754 | 0.999 | 0.997 | |
| OptumGE66 | 0.445 | 0.711 | 0.991 | 0.974 | |
| MDCD | 0.499 | 0.666 | 0.997 | 0.993 | |
| MDCR | 0.445 | 0.711 | 0.991 | 0.974 |
16.5 エビデンスの一般化可能性
コホートは、特定の観察データベースの文脈内で明確に定義され、十分に評価される可能性がありますが、臨床的有効性は、結果が対象とする母集団に一般化可能とみなされる程度によって制限されます。同じテーマに関する複数の観察研究は、異なる結果をもたらす可能性があり、その原因は、研究デザインや分析方法だけでなく、データソースの選択にもある Madigan et al. (2013) は、データベースの選択が観察研究の結果に影響を与えることを実証しました。彼らは、10の観察研究データベースにわたる53の薬物とアウトカムの組み合わせ、および2つの研究デザイン(コホート研究と自己対照ケースシリーズ)について、結果の異質性を系統的に調査しました。研究デザインを一定に保ったにもかかわらず、効果推定値にかなりの異質性が観察されました。 OHDSIネットワーク全体を見ると、観察データベースは、対象とする集団(例えば、小児対高齢者、民間保険加入者対公的保険失業者)、データ収集のケア環境(例えば、入院患者対外来患者、プライマリケア対二次医療/専門医療)、データ収集プロセス(例えば、保険請求、EHR、臨床レジストリ)、ケアの基盤となる全国と地域の医療システムにおいて、かなり異なっています。これらの相違は、疾患や医療介入の効果を研究する際に観察される異質性として確認される場合があり、また、ネットワーク研究におけるエビデンスとなる各データソースの品質に対する信頼性に影響を与える可能性もあります。OHDSIネットワーク内のすべてのデータベースはCDMに標準化されていますが、標準化によって集団全体に存在する真の固有の異質性が減少するわけではなく、単にネットワーク全体にわたる異質性を調査し、より深く理解するための一貫した枠組みが提供されるだけであることを理解しておくことが重要です。OHDSI研究ネットワークは、世界中のさまざまなデータベースに同じ解析プロセスを適用できる環境を提供しており、研究者は他の方法論的側面を一定に保ちながら、複数のデータソースにわたる結果を解釈することができます。OHDSIネットワーク研究におけるオープンサイエンスへの協調的アプローチでは、参加するデータパートナーの研究者が臨床分野の知識を持つ研究者や分析の専門知識を持つ方法論者と協力して作業を行います。これは、ネットワーク全体のデータの臨床的有効性に対する理解を集合的に高めるための方法のひとつであり、このデータを使用して生成されたエビデンスに対する信頼性を構築するための基盤となるべきものです。
16.6 まとめ
- 臨床的妥当性は、基礎となるデータソースの特性を理解し、分析内のコホートの性能特性を評価し、研究の対象集団への一般化可能性を評価することによって確立できます。
- コホートの定義は、コホートの定義と利用可能な観察データに基づいてコホート内で特定された人が、真に表現型に属する人をどの程度正確に反映しているかという観点で評価できます。
- コホート定義の検証には、感度、特異度、陽性適中率など、複数の性能特性を推定して、測定誤差を完全に要約し、調整できるようにすることが必要です。
- ソースレコードの検証とPheValuatorによる臨床判定は、コホート定義の検証を推定するための2つの代替アプローチです。
- OHDSIネットワーク研究は、データソースの異質性を調査し、実証結果の一般化可能性を拡大して、リアルワールドのエビデンスの臨床的有効性を改善するメカニズムを提供します。