第 14 章 エビデンスの質
著者: Patrick Ryan & Jon Duke
14.1 信頼できるエビデンスの属性
どんな旅も出発する前に、理想の目的地がどのようなものかを思い描いておくことが役に立つでしょう。データからエビデンスへの旅を支援するために、信頼できるエビデンスの質を裏付けることができる望ましい属性を本章では強調します。
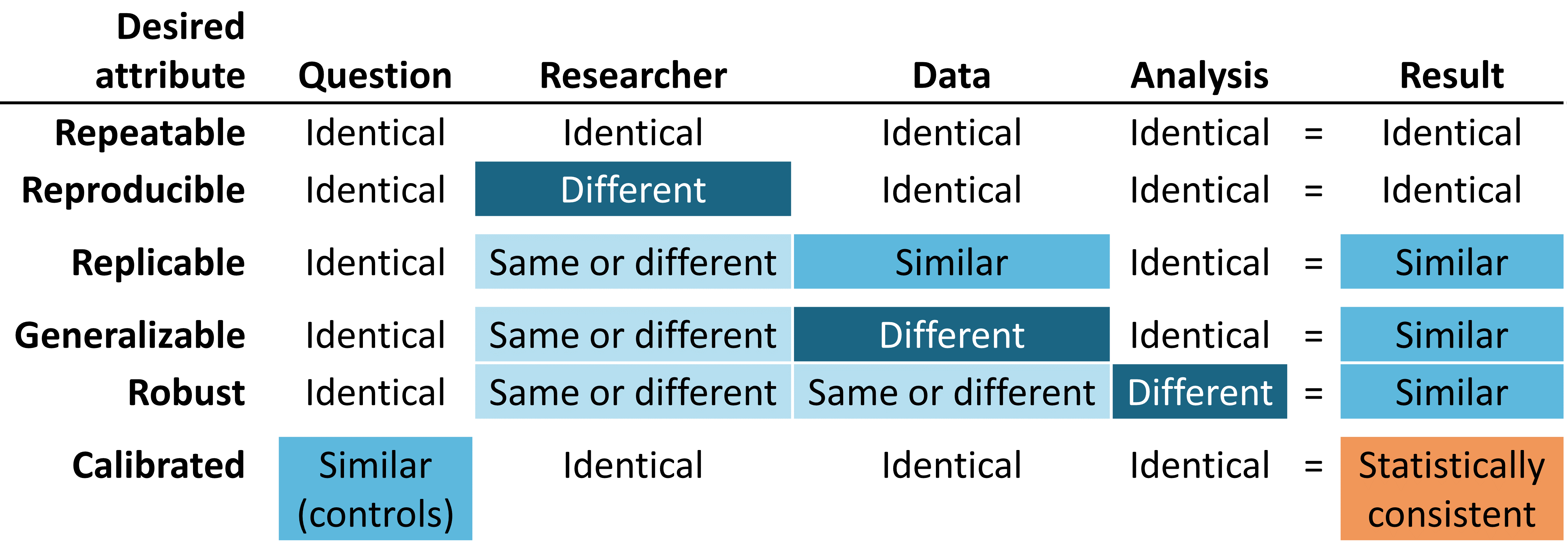
図 14.1: 信頼できる証拠の望ましい属性
信頼性の高いエビデンスは再現性があるであるべきであり、特定の質問に対して同じデータに同じ分析を適用した場合に、研究者は同一の結果が得られると期待すべきです。この最低限の要件には、エビデンスが定義されたプロセスの実行結果であり、その過程で事後的な意思決定による手動の介入があってはならないという考え方が暗黙のうちに含まれています。さらに理想的には、信頼できるエビデンスは再現可能であるべきであり、別の研究者が特定のデータベースで同じ分析を実行した場合でも、最初の研究者と同じ結果を期待するべきです。再現可能性とは、プロセスが完全に明記されており、人間が読める形式とコンピュータが実行可能な形式の両方であり、研究者の裁量に委ねられる余地がないことを意味します。再現性と反復性を実現する最も効率的な解決策は、入力と出力を定義した標準化された分析ルーチンを使用し、これらの手順をバージョン管理されたデータベースに対して適用することです。
私たちは、再現可能であることが示されれば、そのエビデンスが信頼できるものであると自信を持つ可能性が高くなります。例えば、ある大手民間保険会社の保険請求データベースに対する分析から生成されたエビデンスは、別の保険会社の保険請求データで再現されれば、より強固なものとなるでしょう。集団レベルの効果推定という文脈では、この特性は、一貫性に関するAustin Bradford Hill卿の因果関係に関する見解と一致します。「異なる人物、異なる場所、状況、時間において、繰り返し観察されたか?…偶然が説明なのか、真の危険性が明らかになったのかは、状況と観察を繰り返すことによってのみ答えられる場合がある」(Hill 1965)。 患者レベルの予測では、再現性は外部検証の価値と、異なるデータベースに適用した際の識別精度とキャリブレーションを観察することで、1つのデータベースで訓練されたモデルの性能を評価する能力とみなされます。同一の分析が異なるデータベースに対して実行され、依然として一貫して類似した結果を示す状況では、私たちのエビデンスが一般化可能であるという確信がさらに深まります。OHDSI研究ネットワークの重要な価値は、異なる集団、地理、データ収集プロセスによって表される多様性です。Madigan et al. (2013) は、効果推定値がデータの選択に敏感であることを示しました。各データソースには固有の限界や独特の偏りがあり、単一の調査結果に対する信頼性を制限する可能性があることを認識した上で、異なるタイプのデータセットにわたって類似したパターンを観察することには大きな意味があります。なぜなら、ソース固有の偏りだけで調査結果を説明できる可能性が大幅に低くなるからです。ネットワーク研究が、米国、ヨーロッパ、アジアの複数の保険請求データベースや電子的健康記録(EHR)データベースにわたって、一貫した集団レベルの効果推定値を示した場合、医療介入に関するより強力なエビデンスとして認められるべきであり、医療上の意思決定に影響を与える可能性はより広範囲に及びます。
信頼性の高い証拠は頑健であるべきであり、つまり、分析の中でなされる主観的な選択に過度に左右されない結果でなければなりません。特定の研究に対して、代替となる合理的な統計的手法が考えられる場合、異なる手法が類似の結果をもたらすことが確認できれば安心材料となり、逆に、食い違う結果が明らかになれば注意が必要となります(Madigan, Ryan, and Schuemie 2013)。 母集団レベルの効果推定では、感度分析には、コホート比較研究や自己対照ケースシリーズ研究のデザインを適用するかどうか、といった高度な研究デザインの選択が含まれる場合もあります。また、コホート比較研究の枠組みの中で、傾向スコアマッチング、層別化、または重み付けを交絡調整の方法として実行するかどうかといった、デザインに組み込まれた分析上の考慮事項に焦点を当てる場合もあります。
最後に、しかし最も重要なこととして、エビデンスはキャリブレーションされるべきです。未知の質問に対する回答を生成するエビデンス生成システムを保有しているだけでは不十分であり、そのシステムのパフォーマンスを検証できなければ意味がありません。クローズドシステムは、既知の動作特性を持つことが期待されるべきであり、その特性はシステムが生成する結果を解釈する上でのコンテクストとして測定および伝達できるものでなければなりません。統計的アーティファクトは、95%の信頼区間が95%の包含確率を持つ、または予測確率が10%のコホート集団において10%の事象の割合が観察されるなど、明確に定義された特性を持つことを実証できるべきです。観察研究には、常に、デザイン、方法、データに関する仮説を検証する研究診断を付随させる必要があります。これらの診断は、研究の妥当性に対する主な脅威である選択バイアス、交絡、測定エラーの評価に重点を置くべきです。 ネガティブコントロールは、観察研究における系統的エラーを特定し、軽減するための強力なツールであることが示されています(Schuemie et al. 2016, 2018; Schuemie, Ryan, et al. 2018)。
14.2 エビデンスの質の理解
しかし、研究結果が十分に信頼できるものであるかどうかを、どうすれば判断できるのでしょうか? 臨床現場での使用に耐えうるのでしょうか? 規制当局の意思決定に利用できるのでしょうか? 将来の研究の基礎として役立つのでしょうか? ランダム化比較試験、観察研究、その他の分析手法による研究であるかに関わらず、新しい研究が発表または公表されるたびに、読者はこれらの疑問を考慮しなければなりません。
観察研究や「リアルワールドデータ」の利用に関してよく挙げられる懸念事項のひとつに、データの質に関するものがあります(Botsis et al. 2010; Hersh et al. 2013; Sherman et al. 2016)。一般的に指摘されるのは、観察研究で使用されるデータはもともと研究目的で収集されたものではないため、不完全または不正確なデータ取得や、内在するバイアスに苦しむ可能性があるということです。こうした懸念から、データの品質を測定、特徴づけ、そして理想を言えば改善する方法に関する研究が増加しています(Michael G. Kahn et al. 2012; Liaw et al. 2013; Weiskopf and Weng 2013)。OHDSIコミュニティは、こうした研究の強力な推進者であり、コミュニティのメンバーは、OMOP CDMとOHDSIネットワークにおけるデータ品質を調査する多くの研究を主導し、または参加しています(Huser et al. 2016; Michael G. Kahn et al. 2015; Callahan et al. 2017; Yoon et al. 2016)。
この分野における過去10年間の調査結果を踏まえると、データ品質は完璧ではなく、今後も完璧になることはないということが明らかになっています。この考え方は、医療情報学の分野におけるパイオニアであるClem McDonald博士の次の言葉にうまく反映されています。
データの正確性が損なわれるのは、医師の頭脳からカルテにデータが移動する時点から始まります
したがって、コミュニティとして私たちは次のような問いかけをしなければなりません。不完全なデータが与えられた場合、信頼性の高いエビデンスをどのようにして得られるのか?
その答えは、「エビデンスの質」を全体的に見ることにあります。すなわち、データからエビデンスに至るまでの全過程を検証し、エビデンス生成プロセスを構成する各要素を特定し、各要素の質に対する信頼性をどのように構築するかを決定し、各段階で学んだことを透明性をもって伝えることです。エビデンスの質は、観察データの質だけでなく、観察分析で使用される方法、ソフトウェア、臨床定義の妥当性も考慮します。
次の章では、表 14.1 にリストされているエビデンスの質の4つのコンポーネントを探ります。
| エビデンスの質のコンポーネント | 測定するもの |
|---|---|
| データの質 | データが合意された構造と規約に準拠した形で、完全にキャプチャされ信憑性のある値を持つかどうか? |
| 臨床的妥当性 | 実施された分析が臨床的な意図とどの程度一致しているか? |
| ソフトウェアの妥当性 | データの変換および分析プロセスが意図した通りに機能するかどうか? |
| 方法の妥当性 | データの強みと弱点を考慮した上で、その方法論が研究の問いに適しているか? |