第 4 章 共通データモデル
著者: Clair Blacketer
観察データは、患者が医療を受ける際に起こることを示すものです。このデータは世界中でますます多くの患者について収集し、保存されるため、ビッグヘルスデータと呼ばれることがあります。これらのデータ収集には3つの目的があります: 1)直接的に研究を支援するため(よくあるのはサーベイデータやレジストリデータの形で)、2) 医療の提供をサポートするため(いわゆる電子的健康記録(EHR))、3) 医療の費用を管理するため(いわゆる保険請求データ)。この3つの目的はすべて臨床研究に日常的に使用されており、後者の2つは二次利用データとして使用され、すべての目的で、データのコンテンツに関して独自の様式や符号化が使われています。
なぜ観察医療データに共通データモデル(common data model; CDM)が必要なのでしょうか?
それぞれの主たるニーズに応じて、それぞれの観察データベースは臨床イベントをすべて均等に捉えることはできません。そのため、潜在的な捕捉バイアスの影響を理解するには、多くの異なるデータソースから研究結果を導き出し、比較・対照する必要があります。さらに、統計的に有効な結論を導くには、多数の観察対象患者が必要です。これが、複数のデータソースを同時に評価・分析する必要性を説明するものです。そのためには、データを共通のデータ標準に統合する必要があります。さらに、患者データの高度な保護も必要です。従来のように分析目的でデータを抽出するには、厳格なデータ利用契約と複雑なアクセス制御が必要です。共通のデータ標準により抽出ステップを省略し、標準化された分析をネイティブ環境のデータ上で実行できるようにすることで、このニーズを軽減することができます。分析はデータにアクセスするのではなく、データが分析にアクセスするのです。
この標準を提供するのがCDMです。標準化されたコンテンツ(第5章参照)と組み合わせたCDMは、研究方法が体系的に適用され、意味のある比較可能な再現性のある結果を生成することを保証します。この章では、データモデルそのものの概要、デザイン、規約、一部のテーブルについて概説します。
CDMのすべてのテーブルの概要は、図 4.1に示されています。
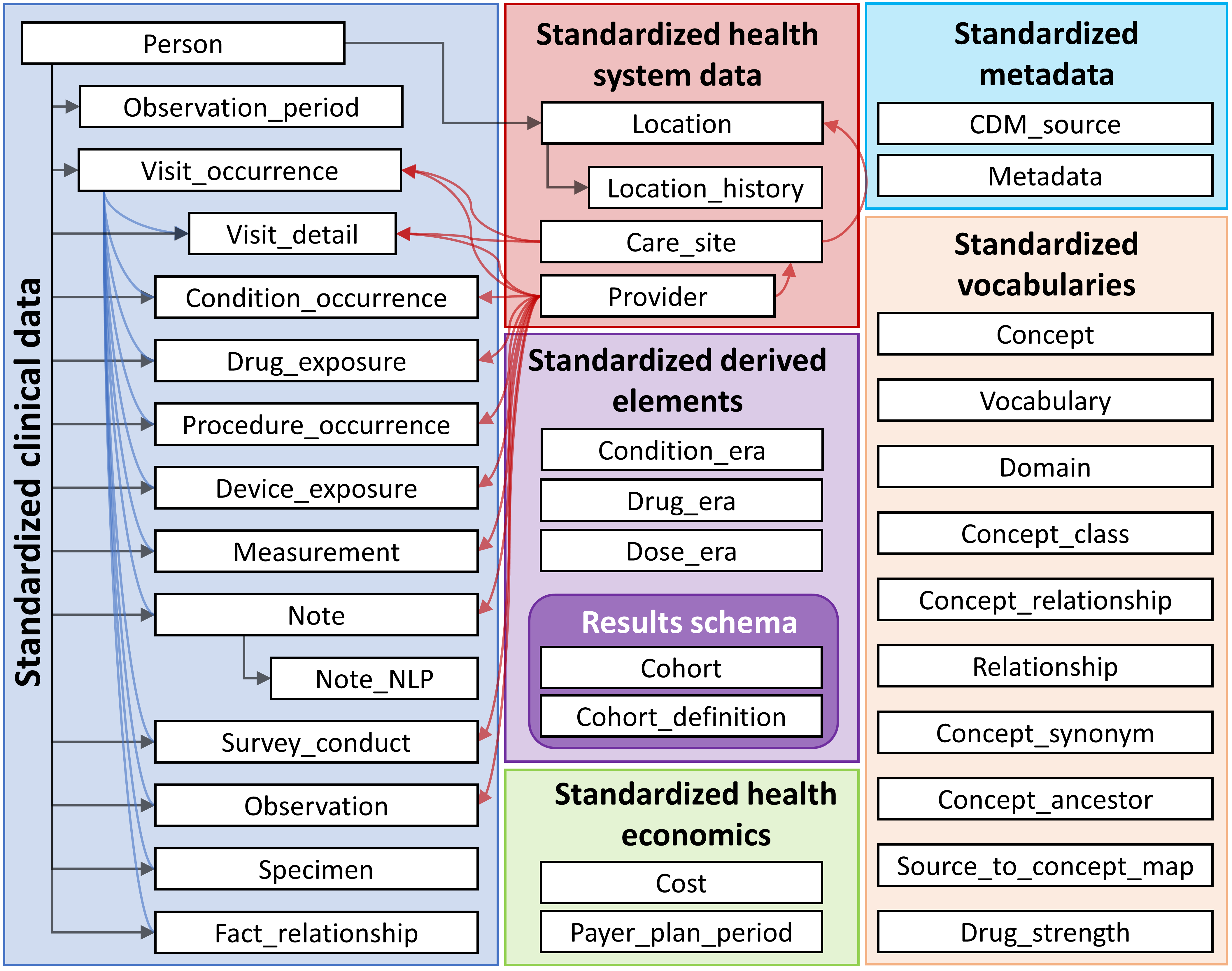
図 4.1: CDMバージョン6.0のすべてのテーブルの概要。テーブル間のすべての関係が示されているわけではありません。
4.1 デザイン原則
CDMは、以下の目的のために最適化されています。
- 特定の医療介入(薬剤曝露、処置(プロシージャー)、医療政策の変更など)やアウトカム(状態・疾患(コンディション)、プロシージャー、他の薬剤曝露など)を持つ患者集団を特定する。
- 人口統計情報、疾患の自然経過、医療の提供、利用、費用、疾患、治療や治療の順序などさまざまなパラメータに関して患者集団の特性を評価する。
- 個々の患者でアウトカムが発生する可能性を予測する(第13章参照)。
- これらの介入が集団に及ぼす影響を推定する(第12章参照)。
この目標を達成するために、CDMの開発は以下のデザイン要素に従います:
- 目的適合性: CDMは、医療従事者または保険者の運用ニーズを満たす目的ではなく、分析のために最適な形でデータを提供することを目指しています。
- データ保護: 名前や正確な誕生日など、患者の身元や保護を危うくする可能性のあるすべてのデータは制限されています。乳児の研究のために正確な誕生日が必要な場合など、研究でより詳細な情報が明示的に必要な場合は例外となることがあります。
- ドメインのデザイン: ドメインは、各レコードに最低限、個人の識別情報と日付が記録される、個人中心のリレーショナルデータモデルでモデル化されています。ここでいうリレーショナルデータモデルとは、主キーと外部キーでリンクされたテーブルの集合としてデータが表現されるものを指します。
- ドメインの根拠: ドメインは、分析のユースケースがある場合(たとえばコンディション)で、そのドメインが他のものには適用されない特定の属性を持つ場合に、エンティティーリレーションシップ(Entity-Relation;ER)図で特定され、個別に定義されます。他のデータはすべて、エンティティー属性ー値(Entity-Attribute-Value;EAV)構造のオブザベーション(観察)テーブルに保持できます。
- 標準化ボキャブラリ: それらの記録の内容を標準化するために、CDMは、標準的な医療コンセプトのすべてに対応する、必要かつ適切な標準化ボキャブラリに依存しています。
- 既存のボキャブラリの再利用: 可能な場合、米国国立医学図書館(The National Library of Medicine)、米国退役軍人省(The Department of Veterans’ Affairs)、米国疾病予防管理センター(The Center of Disease Control and Prevention)などの国立または業界の標準化やボキャブラリ定義を行う組織やイニシアティブのコンセプトを活用しています。
- ソースコードの保持: すべてのコードが標準化ボキャブラリにマッピングされている場合でも、CDMは元のソースコードも保持して、情報が失われないようにしています。
- 技術の中立性: CDMは特定のテクノロジーを必要としません。Oracle、SQL Serverなどのあらゆるリレーショナルデータベース、またはSAS分析データセットを得ることが出来ます。
- スケーラビリティ: CDMは、データベースに含まれる何億人もの人々や何十億件もの臨床観察データなど、さまざまな規模のデータソースに対応できるよう、データ処理と計算分析のために最適化されています。
- 後方互換性: これまでのCDMからの変更はすべてGithubリポジトリ(https://github.com/OHDSI/CommonDataModel)で明確に示されています。CDMの旧バージョンは現在のバージョンから簡単に作成でき、以前に存在していた情報が失われることはありません。
4.2 データモデルの規約
CDMでは、暗黙的および明示的な規約が数多く採用されています。CDMに対応するメソッドの開発者は、これらの規約を理解する必要があります。
4.2.1 モデルの一般的な規約
CDMは「人中心」のモデルと見なされており、すべての臨床イベントのテーブルがPERSONテーブルにリンクされています。日付または開始日と組み合わせることで、人ごとに医療関連イベントをすべて縦断的に見ることができます。このルールに対する例外は、標準化された医療システムデータテーブルで、これはさまざまなドメインのイベントに直接リンクされています。
4.2.2 スキーマの一般的な規約
スキーマ(または一部のシステムではデータベースユーザー)により、読み取り専用テーブルと読み取り/書き込みテーブルを分離することができます。臨床イベントやボキャブラリテーブルは「CDM」スキーマにあり、エンドユーザーや分析ツールからは読み取り専用と見なされます。ウェブベースのツールやエンドユーザーが操作する必要のあるテーブルは、「Results」スキーマに格納されます。「Results(結果)」スキーマの2つのテーブルは、COHORTとCOHORT_DEFINITIONです。これらのテーブルは、ユーザーが定義する可能性のあるグループを記述することを目的としています。詳細は第10章を参照ください。これらのテーブルは書き込み可能であり、実行時にCOHORTテーブルにコホートを保存することができます。すべてのユーザーに対して読み取り/書き込み可能なスキーマは1つだけなので、複数のユーザーアクセスをどのように構成し制御するかは、CDMの実装次第です。
4.2.3 データテーブルの一般的な規約
CDMはプラットフォームに依存しません。データ型はANSI SQLデータ型(VARCHAR、INTEGER、FLOAT、DATE、DATETIME、CLOB)を用いて一般的に定義されます。VARCHARには最小必要文字列長のみが指定され、具体的なCDMのインスタンス内で拡張できます。CDMは日付および日時の形式を規定しません。CDMに対する標準クエリは、ローカルインスタンスや日付/日時の設定によって異なる場合があります。
注意: CDM自体はプラットフォームに依存しませんが、それに対応するために構築された多くのツールは特定の仕様が必要です。詳細については、第8章をご覧ください。
4.2.4 ドメインの一般的な規約
異なる性質のイベントはドメインに整理されています。これらのイベントはドメイン固有のテーブルやフィールドに格納され、標準化ボキャブラリで定義されたドメイン固有の標準コンセプトによって表現されます(セクション 5.2.3参照)。 各標準コンセプトには一意のドメイン割り当てがあり、どのテーブルに記録されるかを定義します。正しいドメイン割り当てはコミュニティ内で議論の余地がありますが、この厳格なドメインテーブルフィールドの対応規約により、コードやコンセプトの記録場所が常に明確であることが保証されます。例えば、徴候、症状、診断のコンセプトはコンディションドメインに属し、CONDITION_OCCURRENCEテーブルのCONDITION_CONCEPT_IDに記録されます。いわゆる処置薬は、ソースデータでは通常プロシージャーテーブルにプロシージャーコードとして記録されます。一方、CDMでは対応する標準データモデルの規約37コンセプトにドメイン割り当て「Drug(薬剤)」が設定されているため、これらのレコードはDRUG_EXPOSUREテーブルに記録されます。ドメインの総数は30で、表 4.1 に示されています。
| コンセプト数 | ドメインID | コンセプト数 | ドメインID |
|---|---|---|---|
| 1731378 | 薬剤 (Drug) | 183 | 経路 (Route) |
| 477597 | デバイス (Device) | 180 | 通貨 (Currency) |
| 257000 | プロシージャー (Procedure) | 158 | 支払者 (Payer) |
| 163807 | コンディション (Condition) | 123 | ビジット(受診期間)(Visit) |
| 145898 | オブザベーション (Observation) | 51 | 費用 (Cost) |
| 89645 | メジャーメント(測定)(Measurement) | 50 | 人種 (Race) |
| 33759 | 特定の解剖学的部位 (Spec Anatomic Site) | 13 | プランの中断理由 (Plan Stop Reason) |
| 17302 | 測定値 (Meas Value) | 11 | プラン (Plan) |
| 1799 | 試料 (Specimen) | 6 | エピソード (Episode) |
| 1215 | 医療従事者の専門 (Provider Specialty) | 6 | スポンサー (Sponsor) |
| 1046 | 単位 (Unit) | 5 | 測定値符号 (Meas Value Operator) |
| 944 | メタデータ (Metadata) | 3 | 特定の疾患ステータス (Spec Disease Status) |
| 538 | 収益コード (Revenue Code) | 2 | 性別 (Gender) |
| 336 | タイプコンセプト (Type Concept) | 2 | 民族 (Ethnicity) |
| 194 | リレーションシップ (Relationship) | 1 | オブザベーションタイプ (Observation Type) |
4.2.5 コンテンツのコンセプトによる表現
CDMデータテーブル内の各レコードのコンテンツは完全に正規化され、コンセプトを通じて表現されます。コンセプトはCONCEPTテーブルへの外部キーであるCONCEPT_ID値とともにイベントテーブルに格納され、CONCEPTテーブルは一般的な参照テーブルとして機能します。CDMインスタンスはすべて、コンセプトの参照として同じCONCEPTテーブルを使用します。これにより、CDMとともにOHDSI研究ネットワークの基盤となる相互運用性の主要なメカニズムが提供されます。標準コンセプトが存在しない場合や特定できない場合、CONCEPT_IDの値は0に設定されます。これは、存在しないコンセプト、不明またはマッピング不可能な値を表します。
CONCEPTテーブルのレコードには、各コンセプトの詳細情報(コンセプト名、ドメイン、クラスなど)が含まれています。コンセプト、コンセプトリレーションシップ、コンセプトの上位層など、コンセプトに関連するその他の情報は、標準化ボキャブラリのテーブルに含まれています(第5章を参照)。
4.2.6 フィールドの一般的な命名規約
すべてのテーブルのフィールド名は1つの規約に従います。
| 記法 | 説明 |
|---|---|
| [Event]_ID | 各レコードの固有の識別子で、イベントテーブル間の関係を確立する外部キーとして機能します。例えば、PERSON_IDは各個人を一意に識別します。VISIT_OCCURRENCE_IDはビジットを一意に識別します。 |
| [Event]_CONCEPT_ID | CONCEPT参照テーブルの標準コンセプトレコードへの外部キーです。これはイベントの主要な表現として機能し、標準化された分析の主要な基礎となります。たとえば、CONDITION_CONCEPT_ID = 31967にはSNOMED(訳者注:The International Health Terminology Standards Development Organisationにより管理されているヘルスケアに関する多言語の包括的な用語集)コンセプトの「吐き気」の参照値が含まれています。 |
| [Event]_SOURCE_CONCEPT_ID | CONCEPT参照テーブルのレコードへの外部キーです。このコンセプトは、以下のソース値に相当し、標準コンセプトの場合、それは[Event]_CONCEPT_IDと同一になります。例えば、CONDITION_SOURCE_CONCEPT_ID = 45431665は「吐き気」というコンセプトを、Read用語(訳者注:英国の一般診療やプライマリケアで広く使用されるコーディング体系)で示し、同様のCONDITION_CONCEPT_IDは標準のSNOMED-CTコンセプト31967です。標準分析アプリケーションの場合、ソースコンセプトの使用は推奨されません。なぜなら、標準コンセプトだけがイベントの意味的なコンテンツを明確に示し、ソースコンセプトは相互運用可能ではないためです。 |
| [Event]_TYPE_CONCEPT_ID | ソース情報の出所を示す標準化ボキャブラリで、コンセプト参照テーブルのレコードへの外部キーです。フィールド名とは異なり、これはイベントやコンセプトの種類ではなく、このレコードを作成した取得メカニズムを宣言するものであることに留意ください。例として、DRUG_TYPE_CONCEPT_IDは、薬剤レコードが薬局での調剤イベント(「Pharmacy dispensing(薬局での調剤)」)から派生したものか、電子処方箋(Prescription written(処方箋発行))から派生したものかを区別します。 |
| [Event]_SOURCE_VALUE | ソースデータでこのイベントがどのように表現されていたかを反映する、逐語的なコードまたは自由形式の文字列です。これらのソース値はデータソース間で整合されていないため、標準的な分析アプリケーションでの使用は推奨されません。例えば、CONDITION_SOURCE_VALUEにはドットを省略した表記で書かれたICD-9コード787.02に対応する「78702」のレコードが含まれる可能性があります。 |
4.2.7 コンセプトとソース値の違い
多くのテーブルには、ソース値、ソースコンセプト、標準コンセプトとして、複数の場所に同等の情報が含まれています。
- ソース値は、ソースデータにおけるイベントレコードのオリジナル表現です。これらは、ICD9CM、全米医薬品コード(National Drug Code; NDC)、Readなどのように、広く使用されているがパブリックドメインであることが多いコーディング体系からのコード、CPT4(Common Procedural Technology)(訳者注:米国医師会が管理する請求用コーディング体系)、GPI(Generic Product Identifier)(訳者注:Wolters Kluwer社により作成されている医薬品のコーディング体系)、MedDRAなどの独自のコーディング体系、あるいは女性をF、男性をMのようにソースデータのみで使用される管理されたボキャブラリであることがあります。また、標準化も管理もされていない短い自由テキストのフレーズであることもあります。ソース値は、データテーブルの[Event]_SOURCE_VALUEフィールドに格納されます。
- コンセプトは、CDM特有のエンティティであり、臨床事実の意味を標準化します。ほとんどのコンセプトは、医療分野における既存の公開または独自仕様のコーディング体系に基づきますが、中には新規に作成されたものもあります(CONCEPT_CODEが「OMOP」で始まる)。コンセプトには、すべてのドメインにわたって一意のIDが割り当てられています。
- ソースコンセプトは、ソースで使用されるコードを表すコンセプトです。ソースコンセプトは、既存の公開または独自のコード体系に対してのみ使用され、OMOPで生成されたコンセプトには使用されません。ソースコンセプトはデータテーブル内の[Event]_SOURCE_CONCEPT_IDフィールドに格納されます。
- 標準コンセプトは、ソースで使用されるコードシステムとは無関係に、すべてのデータベースで臨床実態の意味を一意に定義するために使用されるコンセプトです。標準コンセプトは通常、既存の公開または専有のボキャブラリソースから取得されます。標準コンセプトと同等な意味を持つ非標準コンセプトは、標準化ボキャブラリにおいて標準コンセプトにマッピングされます。標準コンセプトはデータテーブルの[Event]_CONCEPT_IDフィールドで参照できます。
ソース値は、便宜上、品質保証(QA)の目的でのみ提供されます。ソース値には、特定のデータソースの文脈のみで意味を持つ情報が含まれる場合があります。ソース値やソースコンセプトの使用は任意ですが、ソースデータがコード体系を使用している場合には強く推奨されます。一方、標準コンセプトの使用は必須です。この標準コンセプトの使用が必須である理由は、すべてのCDMインスタンスが同じ言語を話すことができるようにするためです。例えば、図 4.2 で示されているように、コンディション「Pulmonary Tuberculosis(肺結核)」(TB)のICD9CMコードは011です。
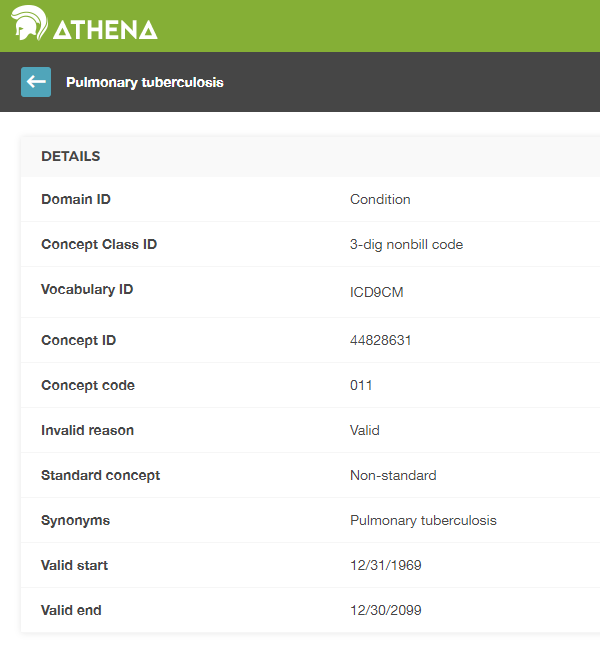
図 4.2: 肺結核のICD9CMコード
文脈がなければ、コード011は、UB04ボキャブラリでは「Hospital Inpatient (Including Medicare Part A)(病院入院患者(メディケアパートA を含む))」、DRGボキャブラリでは「Nervous System Neoplasms without Complications, Comorbidities(神経系新生物(合併症、併存症なし)」と解釈される可能性があります。 このような場合に、ソースと標準の両方のコンセプトIDが役立ちます。ICD9CMの011を表すCONCEPT_IDの値は44828631です。これにより、UBO4(訳者注:米国全国統一請求委員会(National Uniform Billing Committee:NUBC)が採用するU請求情報コーディング体系)とDRGとICD9CMが区別されます。ICD9CMでのTB のソースコンセプト は、図 4.3 に示されているように、「Non-standard to Standard map (OMOP)(非標準から標準へのマップ(OMOP)」というリレーションシップを通じて、SNOMED ボキャブラリーから 標準コンセプト 253954にマップされます。この同じマッピングリレーションシップは、Read、ICD10、CIEL(The Columbia International eHealth Laboratory. 訳者注:中低所得国における保健情報システムに関連する用語のコーディング体系)、MeSH コードなどにも存在するため、SNOMED 標準コンセプトを参照するあらゆる検索は、サポートされているすべてのソースコードを含みます。
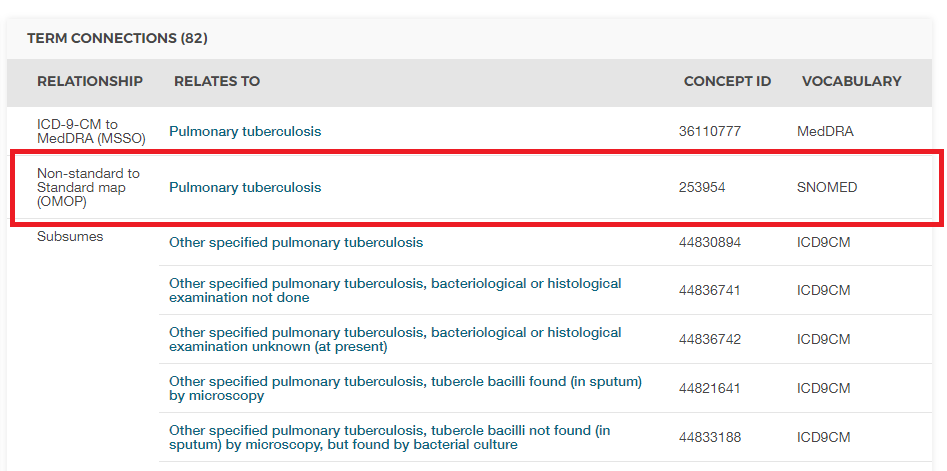
図 4.3: 肺結核のSNOMEDコード
標準コンセプトとソースコンセプトとのリレーションシップの例を表 4.7に示します。
4.3 CDM標準化テーブル
CDMには16の臨床イベントテーブル、10のボキャブラリテーブル、2つのメタデータテーブル、4つのヘルスシステムデータテーブル、2つの医療経済データテーブル、3つの標準化された派生要素、および2つの結果スキーマテーブルが含まれています。 これらのテーブルはCDM Wikiで詳しく説明されています18。
これらのテーブルが実際にどのように使用されるかを説明するために、本章の残りの部分ではある1人のデータを共通した例として使用します。
4.3.1 実際の例: 子宮内膜症
子宮内膜症は、通常女性の子宮内膜にある細胞が身体の他の場所に生じるために痛みを伴う状態です。重症になると、不妊症、腸や膀胱の問題を引き起こすことがあります。次のセクションでは、この病気にかかった患者の経験と、それが共通データモデルでどのように表現される可能性があるかを詳しく説明します。

この痛みを伴う旅のすべての段階で、どれほど痛みを感じているかを皆に納得させなければなりませんでした。
Laurenは何年も子宮内膜症の症状に悩まされてきましたが、診断を受けるまでには卵巣嚢腫の破裂を経験しています。Laurenについての詳細はhttps://endometriosis-uk.org/laurens-story をご覧ください。
4.3.2 PERSONテーブル
Laurenについてわかっていること
- 彼女は36歳の女性です
- 彼女の誕生日は1982年3月12日です
- 彼女は白人です
- 彼女はイギリス人です
これを踏まえると、彼女のPERSONテーブルは次のようになります:
| 列名 | 値 | 説明 |
|---|---|---|
| PERSON_ID | 1 | PERSON_IDはソースから直接であれ、ビルドプロセスの一部として生成されたものであれ、整数である必要があります。 |
| GENDER_CONCEPT_ID | 8532 | 女性性別を表すコンセプトIDは8532です。 |
| YEAR_OF_BIRTH | 1982 | |
| MONTH_OF_BIRTH | 3 | |
| DAY_OF_BIRTH | 12 | |
| BIRTH_DATETIME | 1982-03-12 00:00:00 | 時間が不明の場合は0時が使用されます。 |
| DEATH_DATETIME | ||
| RACE_CONCEPT_ID | 8527 | 白人を示すコンセプトIDは8527です。英国の民族は4093769です。どちらも正しいですが、後者は前者に包含されます。民族性は、ETHNICITY_CONCEPT_IDではなく、人種の一部としてここに格納されていることに留意ください。 |
| ETHNICITY_CONCEPT_ ID | 38003564 | これはヒスパニック系の人々を他の人々から区別するための米国特有の表記法で、「English(イギリス人)」という民族は、RACE_CONCEPT_ID に格納されます。米国以外ではこの区別は使用されません。38003564は「Not hispanic (非ヒスパニック)」を表します。 |
| LOCATION_ID | 彼女の住所は不明です。 | |
| PROVIDER_ID | 彼女のプライマリケア医療従事者は不明です。 | |
| CARE_SITE | 彼女の主な医療施設は不明です。 | |
| PERSON_SOURCE_ VALUE | 1 | 通常、これはソースデータでの彼女の識別子ですが、多くの場合、それはPERSON_IDと同じです。 |
| GENDER_SOURCE_ VALUE | F | ソースに表示されている性別値がここに格納されています。 |
| GENDER_SOURCE_ CONCEPT_ID | 0 | ソースの性別値が OHDSI がサポートするコーディング体系でコード化されている場合、そのコンセプトはここに格納されます。例えば、ソースの性別が「性別-F」であり、PCORNet ボキャブラリコンセプトに記載されている場合、44814665がこのフィールドに入ります。 |
| RACE_SOURCE_ VALUE | white | ソースに表示されてい人種値がここに格納されます。 |
| RACE_SOURCE_ CONCEPT_ID | 0 | 同様にGENDER_SOURCE_CONCEPT_IDの原則が適用されます。 |
| ETHNICITY_SOURCE_ VALUE | english | ソースに表示されている民族の値がここに格納されます。 |
| ETHNICITY_SOURCE_ CONCEPT_ID | 0 | 同様にGENDER_SOURCE_CONCEPT_IDの原則が適用されます。 |
4.3.3 OBSERVATION_PERIODテーブル
OBSERVATION_PERIODテーブルは、妥当な感度と特異度が期待されるソースシステムにおいて、少なくとも患者の人口統計、コンディション、プロシージャー、薬剤が記録される期間を定義するためにデザインされています。保険請求データの場合は、通常、患者の加入期間となります。電子的健康記録(EHR)の場合は、より複雑です。ほとんどの医療システムでは、どの医療機関または医療従事者を受診したかを特定しないためです。次善の策として、システム内の最初のレコードが観察期間の開始日と見なされ、最新のレコードが終了日と見なされることがよくあります。
Laurenの観察期間はどのように定義されているのですか?
表 4.4に示されるLaurenの情報がEHRに記録されているとしましょう。彼女の観察期間の元となる彼女の受診 (Encounter) は:
| 受診ID | 開始日 | 終了日 | タイプ |
|---|---|---|---|
| 70 | 2010-01-06 | 2010-01-06 | 外来患者 |
| 80 | 2011-01-06 | 2011-01-06 | 外来患者 |
| 90 | 2012-01-06 | 2012-01-06 | 外来患者 |
| 100 | 2013-01-07 | 2013-01-07 | 外来患者 |
| 101 | 2013-01-14 | 2013-01-14 | Ambulatory (通院施設) |
| 102 | 2013-01-17 | 2013-01-24 | 入院患者 |
受診レコードに基づいて彼女のOBSERVATION_PERIODテーブルは次のようになるかもしれません:
| 列名 | 値 | 説明 |
|---|---|---|
| OBSERVATION_ PERIOD_ID | 1 | これは通常、自動生成された値で、テーブル内の各レコードに一意の識別子を生成します。 |
| PERSON_ID | 1 | これはPERSONテーブルでLauraのレコードへの外部キーであり、PERSONをOBSERVATION_PERIODテーブルにリンクします。 |
| OBSERVATION_PERIOD_ START_DATE | 2010-01-06 | これは記録上、彼女の最初の受診の開始日です。 |
| OBSERVATION_PERIOD_ END_DATE | 2013-01-24 | これは記録上、彼女の最後の受診の終了日です。 |
| PERIOD_TYPE_ CONCEPT_ID | 44814725 | 「Obs Period Type (観察期間タイプ)」 コンセプトクラスを持つボキャブラリにおける最良のオプションは44814724で、Period covering healthcare encounters(ヘルスケア受診をカバーする期間)を表します。 |
4.3.4 VISIT_OCCURRENCE
VISIT_OCCURRENCEテーブルには、患者が医療システムを利用した際の情報が格納されています。OHDSIでは、これらの情報を「ビジット」と呼び、個別のイベントとして扱います。ビジットには12のトップカテゴリーがあり、医療が提供されるさまざまな状況を描写する広範な階層構造があります。最も多く記録されているビジットは、入院、外来、救急外来、医療機関以外の施設へのビジットです。
Laurenの受診がビジットとしてどのように表現されるでしょうか?
例として、入院受診をVISIT_OCCURRENCEテーブルで表現しましょう。
| 列名 | 値 | 説明 |
|---|---|---|
| VISIT_OCCURRENCE_ID | 514 | これは通常、自動生成された値で、各レコードに一意の識別子を生成します。 |
| PERSON_ID | 1 | これはPERSONテーブルのLaurenのレコードにリンクする外部キーです。 |
| VISIT_CONCEPT_ID | 9201 | 入院ビジットを参照するキーは9201です。 |
| VISIT_START_DATE | 2013-01-17 | ビジットの開始日です。 |
| VISIT_START_ DATETIME | 2013-01-17 00:00:00 | ビジットの日付と時間です。時間が不明なため、0時が使用されます。 |
| VISIT_END_DATE | 2013-01-24 | ビジットの終了日です。これは1日のビジットである場合、終了日は開始日と一致します。 |
| VISIT_END_DATETIME | 2013-01-24 00:00:00 | ビジットの終了日と時間です。時間が不明なため、0時が使用されます。 |
| VISIT_TYPE_ CONCEPT_ID | 32034 | ビジットレコードの出所を示します。保険請求、病院請求、EHRなど。これらの受診がEHRに似ている例として、32035(「Visit derived from EHR encounter record(EHR受診レコードから派生したビジット)」)のコンセプトIDが使用されています。 |
| PROVIDER_ID | NULL | 受診レコードに医療従事者が関連付けられている場合、その医療従事者のIDがこのフィールドに格納されます。これが医療従事者テーブルのPROVIDER_IDフィールドの内容であるはずです。 |
| CARE_SITE_ID | NULL | 受診レコードに関連する医療施設がある場合、その医療施設のIDがこのフィールドに入ります。これがCARE_SITEテーブルのCARE_SITE_IDであるはずです。 |
| VISIT_SOURCE_ VALUE | 入院 | ソースデータでどのように表示されるかに基づいてここに格納されます。Laurenのデータにはそれがありません。 |
| VISIT_SOURCE_ CONCEPT_ID | NULL | ソースデータがOHDSIによって認識されているボキャブラリを使用してコーディングされている場合、ソースコードを表すコンセプトIDがここに表示されます。Laurenのデータにはこの値がありません。 |
| ADMITTED_FROM_ CONCEPT_ID | NULL | わかる場合には、、患者が入院した元の場所を表すコンセプトが表示されます。このコンセプトのドメインは「ビジット」であるべきです。例えば、患者が自宅から病院に入院した場合には、コンセプトID 8536「Home(自宅)」が含まれます。 |
| ADMITTED_FROM_ SOURCE_CONCEPT_ID | NULL | 患者が入院した元の場所を表すソース値が表示されます。上記の例では「Home(自宅)」です。 |
| DISCHARGE_TO_ CONCEPT_ID | NULL | わかる場合、、患者が退院した先の場所を表すコンセプトが含まれます。このコンセプトのドメインは「ビジット」であるべきです。例えば、患者がAssisted living facility(介護付き生活施設)に退院した場合、コンセプトID 8615「Assisted living facility(介護付き生活施設)」となります。 |
| DISCHARGE_TO_ SOURCE_VALUE | NULL | 患者が退院した場所を表すソース値が含まれます。上記の例では「介護付き生活施設」となります。 |
| PRECEDING_VIS | NULL | 現在のビジットの直前のビジットを示します。ADMITTED_FROM_CONCEPT_IDとは対照的に、ビジットコンセプトではなく、実際のビジット発生記録にリンクします。また、注意すべきは後続のビジットがないことです。ビジット発生記録は、このフィールドを通じてのみリンクされます。 |
- 患者は、入院患者の場合によくあるように、1回のビジット中に複数の医療従事者とやりとりすることがあります。これらのやりとりは、VISIT_DETAILテーブルに記録することができます。この章では深く掘り下げませんが、VISIT_DETAILテーブルの詳細については、CDM Wikiを参照ください。
4.3.5 CONDITION_OCCURRENCE
CONDITION_OCCURRENCEテーブルのレコードは、医療従事者によって観察された、または患者によって報告された、コンディションの診断、徴候、または症状です。
Laurenのコンディションは何ですか?
彼女の記録を再確認すると、次のように述べられています。:
約3年前、それまでにも痛かった生理痛がますますひどくなっていることに気づきました。直腸のすぐ近くに鋭い突き刺すような痛みを感じ、尾骨と骨盤下部のあたりが圧痛と腫れを伴っていることに気づきました。生理痛がひどくなり、月に1~2日は仕事を休むほどでした。鎮痛剤で痛みを和らげられることもありましたが、あまり効果はありませんでした。
月経痛(月経困難症)のSNOMEDコードは266599000です。表 4.7 は、それがCONDITION_OCCURRENCEテーブルでどのように表現されるかを示しています。
| 列名 | 値 | 説明 |
|---|---|---|
| CONDITION_ OCCURRENCE_ID | 964 | これは通常、自動生成された値で、各レコードに一意の識別子を生成します。 |
| PERSON_ID | 1 | これは、PERSONテーブルのLauraのレコードへの外部キーであり、PERSONとCONDITION_OCCURRENCEをリンクしています。 |
| CONDITION_ CONCEPT_ID | 194696 | SNOMEDコード266599000を表す外部キーは194696です。 |
| CONDITION_START_ DATE | 2010-01-06 | コンディションが記録された日付です。 |
| CONDITION_START_ DATETIME | 2010-01-06 00:00:00 | コンディションが記録された日時です。時刻は不明なので、0時が使用されます。 |
| CONDITION_END_ DATE | NULL | コンディションが終了したと見なされる日付ですが、これはほとんど記録されていません。 |
| CONDITION_END_ DATETIME | NULL | わかる場合、コンディションが終了したと見なされる日時です。 |
| CONDITION_TYPE_ CONCEPT_ID | 32020 | この列は、レコードの由来に関する情報を提供することを目的としています。すなわち、保険請求、病院の請求記録、EHRなどから取得されたものであることを示すものです。この例では、受診が電子カルテに類似しているため、 32020「EHR encounter diagnosis(EHR受診診断)」というコンセプトが使用されています。このフィールドのコンセプトは、「Condition Type (コンディションタイプ)」のボキャブラリに属するべきです。 |
| CONDITION_STATUS_CONCEPT_ID | NULL | これが分かると、状況と理由がわかります。例えば、コンディションが入院時の診断であった場合には、、コンセプトID 4203942 が使用されます。 |
| STOP_REASON | NULL | わかる場合、ソースデータに示されているコンディションが存在しなくなった理由。 |
| PROVIDER_ID | NULL | コンディションレコードに診断を付けた医療従事者がリストされている場合、その医療従事者の ID がこのフィールドに入ります。これは、そのビジットの医療従事者を表すPROVIDERテーブルのprovider_idでなければなりません。 |
| VISIT_OCCURRENCE_ ID | 509 | コンディションが診断されたビジット(VISIT_OCCURRENCEテーブルのVISIT_OCCURRENCE_IDに対する外部キー)。 |
| CONDITION_SOURCE_ VALUE | 266599000 | これはコンディションを表す元のソース値です。Laurenの月経困難症の場合、そのコンディションのSNOMEDコードはここに格納され、そのコードを表すコンセプトはCONDITION_SOURCE_CONCEPT_IDに格納され、そこからマッピングされた標準コンセプトはCONDITION_CONCEPT_IDフィールドに格納されます。 |
| CONDITION_SOURCE_ CONCEPT_ID | 194696 | ソースからのコンディションの値が OHDSI で認識されるボキャブラリを使用してコード化されている場合、その値を表すコンセプトID がここに入ります。月経困難症の例では、ソース値はSNOMED コードなので、そのコードを表すコンセプトは 194696 です。この場合、CONDITION_CONCEPT_ID フィールドと同じ値になります。 |
| CONDITION_STATUS_ SOURCE_VALUE | 0 | もしソースからのコンディションステータス値が OHDSI がサポートするコーディング体系でコードされていれば、そのコンセプトはここに入ります。 |
4.3.6 DRUG_EXPOSURE
DRUG_EXPOSUREテーブルは、患者の体内への薬剤の意図的または実際の使用に関する記録を取得します。薬剤には、処方薬、市販薬、ワクチン、高分子生物学的製剤が含まれます。薬剤への曝露は、オーダーに関連する臨床イベント、処方箋発行、薬局での調剤、処置薬としての投与、およびその他の患者報告情報から推測されます。
Laurenの薬物への薬剤はどのように表現されますか?
月経困難症の痛みを改善するために、Laurenは2010年01月06日のビジット時に、375mgの経口投与のアセトアミノフェン(別名パラセタモール、例えば米国ではNDCコード69842087651で販売)を60錠、30日分が出されました。DRUG_EXPOSUREテーブルでは以下のようになります:
| 列名 | 値 | 説明 |
|---|---|---|
| DRUG_EXPOSURE_ID | 1001 | 通常、各レコードの一意な識別子を作成するために自動生成される値です。 |
| PERSON_ID | 1 | PERSONテーブルのLaurenのレコードに対する外部キーで、PERSONとDRUG_EXPOSUREをリンクしています。 |
| DRUG_CONCEPT_ID | 1127433 | 薬剤のコンセプト。アセトアミノフェンの NDC コードは RxNorm(訳者注:米国国立医学図書館で管理されている臨床薬剤ボキャブラリ)コード 313782 に対応し、コンセプト 1127433で表されます。 |
| DRUG_EXPOSURE_ START_DATE | 2010-01-06 | 薬剤曝露の開始日。 |
| DRUG_EXPOSURE_ START_DATETIME | 2010-01-06 00:00:00 | 薬剤曝露の開始日時。時間が不明なため0時を使用。 |
| DRUG_EXPOSURE_ END_DATE | 2010-02-05 | 薬剤曝露の終了日。様々な情報源によって、既知の日付または推測される日付となり、患者が薬剤に曝露されていた最後の日を示します。この場合、Laurenが30日分を持っていたことが分かっているので、この日付が推測されます。 |
| DRUG_EXPOSURE_ END_DATETIME | 2010-02-05 00:00:00 | 薬剤曝露の終了日時。DRUG_EXPOSURE_END_DATEと同様のルールが適用されます。時刻が不明な場合は0時が使用されます。 |
| VERBATIM_END_DATE | NULL | 情報源が実際の終了日を明確に記録している場合。推定される終了日は、患者によって全日数分が使用されたという仮定に基づいています。 |
| DRUG_TYPE_ CONCEPT_ID | 38000177 | この欄は、記録の由来に関する情報(保険請求や処方箋の記録など)を提供するためのものです。この例では、コンセプト 38000177 (「Prescription written(処方箋発行)」)が使用されています。 |
| STOP_REASON | NULL | 薬剤の投与が中止された理由。理由にはレジメンの終了、変更、削除などが含まれます。この情報はほとんど記録されません。 |
| REFILLS | NULL | 多くの国で処方システムの一部となっている、初回処方後の自動リフィル数。最初の処方はカウントされず、値は NULL から始まります。Lauren のアセトアミノフェンの場合、リフィルはなかったので、値は NULL です。 |
| QUANTITY | 60 | 最初の処方箋または調剤記録に記録された薬剤の量。 |
| DAYS_SUPPLY | 30 | 処方された薬の処方日数。 |
| SIG | NULL | 元の処方箋または調剤記録に記録されている(米国の薬剤処方システムでは容器に印刷されている)薬剤処方箋の指示(「signetur」)。signetur は CDM ではまだ標準化されておらず、逐語的に提供されます。 |
| ROUTE_CONCEPT_ID | 4132161 | このコンセプトは、患者が曝露された薬剤の投与経路を表すものです。Laurenはアセトアミノフェンを経口摂取したので、コンセプトID 4132161(「Oral(経口)」)が使用されています. |
| LOT_NUMBER | NULL | 製造業者から薬剤の特定の数量またはロットに割り当てられた識別子。この情報はほとんど取得されません。 |
| PROVIDER_ID | NULL | 薬剤レコードに処方した医療従事者が記録されている場合、その医療従事者のIDがこのフィールドに入ります。その場合、このフィールドにはPROVIDERテーブルのPROVIDER_IDが入ります。 |
| VISIT_OCCURRENCE_ ID | 509 | 薬剤が処方された VISIT_OCCURRENCE テーブルへの外部キー。 |
| VISIT_DETAIL_ID | NULL | 薬剤が処方された VISIT_DETAIL テーブルへの外部キー。 |
| DRUG_SOURCE_ VALUE | 69842087651 | ソースデータに表示される薬剤のソースコードです。Laurenの場合、NDCコードがここに格納されています。 |
| DRUG_SOURCE_ CONCEPT_ID | 750264 | 薬剤のソースデータでの値を表すコンセプトです。コンセプト 750264 NDCコードで「Acetaminophen 325 MG Oral Tablet(アセトアミノフェン 325 MG 経口錠)」を表します。 |
| ROUTE_SOURCE_ VALUE | NULL | ソースデータに詳述されている投与経路に関する逐語的な情報。 |
4.3.7 PROCEDURE_OCCURRENCE
PROCEDURE_OCCURRENCEテーブルには、医療従事者が診断または治療目的で患者に関してオーダーした、または実施した活動やプロセスの記録が含まれます。プロシージャーは様々なデータソースに様々な形で存在し、標準化のレベルも様々です。例えば、
- 実施されたプロシージャーを含む提供された医療サービスの保険請求の一部として提出される医療保険請求データ
- オーダーとしてプロシージャーを捕捉するEHR
Laurenはどのプロシージャーを受けたのでしょうか?
彼女の記述から、2013年01月14日に左卵巣の超音波検査を受け、4x5cmの嚢胞があることがわかりました。PROCEDURE_OCCURRENCEテーブルでは、このように表示されます:
| 列名 | 値 | 説明 |
|---|---|---|
| PROCEDURE_ OCCURRENCE_ID | 1277 | これは通常、各レコードの一意な識別子を作成するために自動生成される値です。 |
| PERSON_ID | 1 | これはPERSONテーブルのローラのレコードに対する外部キーで、PERSONとPROCEDURE_OCCURRENCEをリンクしています。 |
| PROCEDURE_ CONCEPT_ID | 4127451 | 骨盤超音波検査のSNOMEDプロシージャーコードは304435002で、コンセプト4127451で表されます。 |
| PROCEDURE_DATE | 2013-01-14 | プロシージャーが実施された日付。 |
| PROCEDURE_ DATETIME | 2013-01-14 00:00:00 | プロシージャーが行われた日時。時刻が不明な場合は0時を使用します。 |
| PROCEDURE_TYPE_ CONCEPT_ID | 38000275 | この列はプロシージャーの記録の由来に関する情報を提供することを目的としています。すなわち、保険請求、EHRオーダーなどによるものかどうかです。この例では、プロシージャーの記録がEHRによるのものであるため、コンセプトID 38000275 (EHR order list entry (EHRオーダー入力))が使用されています。 |
| MODIFIER_CONCEPT_ ID | 0 | これはプロシージャーの修飾子を表すコンセプトID を意味します。例えば、CPT4 のプロシージャーが両側で行われたと記録されている場合、コンセプト ID 42739579(Bilateral procedure(両側プロシージャー))が使用されます。 |
| QUANTITY | 0 | オーダーされた、または実施されたプロシージャーの数。欠測値、0、および1はすべて同じ意味です。 |
| PROVIDER_ID | NULL | プロシージャーレコードに医療従事者がリストされている場合、その医療従事者のIDがこのフィールドに入ります。これはPROVIDERテーブルのPROVIDER_IDに対する外部キーでなければなりません。 |
| VISIT_OCCURRENCE_ ID | 740 | 情報がある場合には、これはプロシージャーが施行されたビジットです(VISIT_OCCURRENCEテーブルから取得したVISIT_occurrence_idとして表されます)。 |
| VISIT_DETAIL_ID | NULL | 情報がある場合、プロシージャーが実施されたビジット詳細です(VISIT_DETAIL テーブルから VISIT_detail_id として取得)。 |
| PROCEDURE_SOURCE_ VALUE | 304435002 | ソース・データに表示されているプロシージャーのコードまたは情報。 |
| PROCEDURE_SOURCE_ CONCEPT_ID | 4127451 | プロシージャーのソースデータの値を表すコンセプトです。 |
| MODIFIER_SOURCE_ VALUE | NULL | ソースデータに表示される修飾子のソースコード。 |
4.4 追加情報
本章では、CDMに用意されている表の一部のみを取り上げ、データの表現方法の例として紹介しています。 より詳しい情報については、Wiki 19をご覧ください。
4.5 まとめ
CDMは広範囲の観察研究活動をサポートするようにデザインされています。
CDMは人中心のモデルです。
CDMはデータの構造を標準化するだけでなく、標準化ボキャブラリを通じてコンテンツの表現も標準化します。
完全な追跡可能性を確保するために、ソースコードはCDMで管理されています。
4.6 演習
前提条件
これらの最初の練習問題のために、以前に議論されたCDMテーブルを確認する必要があり、ATHENA20またはATLAS21を通じて語彙内のコンセプトを調べる必要があります。
演習 4.1 Johnは1974年8月4日生まれのアフリカ系アメリカ人男性です。この情報をエンコードするPERSONテーブルに入力する情報を定義してください。
演習 4.2 Johnは2015年1月1日に現在の保険に加入しました。彼の保険請求データは2019年7月1日に抽出されました。この情報を表現するOBSERVATION_PERIODテーブルに入力する情報を定義してください。
演習 4.3 Johnは2019年5月1日にイブプロフェン200 MG経口錠剤(NDCコード:76168009520)の30日分を処方されました。この情報を表現するためのDRUG_EXPOSUREテーブルに入力する情報を定義してください。
前提条件
最後の3つの課題には、セクション 8.4.5 で説明されているようにR、R-Studio、およびJavaがインストールされていることが前提となります。また、SqlRender、DatabaseConnector、およびEunomiaパッケージも必要で、以下のコマンドでインストールできます:
install.packages(c("SqlRender", "DatabaseConnector", "remotes"))
remotes::install_github("ohdsi/Eunomia", ref = "v1.0.0")Eunomiaパッケージは、ローカルのRセッション内で実行されるCDM内の模擬データセットを提供します。接続の詳細は以下を参照してください:
CDMデータベーススキーマは「main」です。これはCONDITION_OCCURRENCEテーブルの一行を取得するためのSQLクエリの例です:
library(DatabaseConnector)
connection <- connect(connectionDetails)
sql <- "SELECT *
FROM @cdm.condition_occurrence
LIMIT 1;"
result <- renderTranslateQuerySql(connection, sql, cdm = "main")演習 4.4 SQLとRを使用して、コンディション「Gastrointestinal hemorrhage (消化管出血)」(コンセプトID192671)のすべてのレコードを取得してください。
演習 4.5 SQLとRを使用して、ソースコードを使用して、コンディション「Gastrointestinal hemorrhage (消化管出血)」のすべてのレコードを取得してください。このデータベースはICD-10を使用しており、関連するICD-10コードは 「K92.2」です。
演習 4.6 SQLとRを使用して、PERSON_ID 61に該当する人の観察期間を取得してください。
解答例は、付録 E.1を参照ください。