Chapter 1 The OHDSI Community
Chapter leads: Patrick Ryan & George Hripcsak
Coming together is a beginning; staying together is progress; working together is success. Henry Ford
1.1 The Journey from Data to Evidence
Everywhere in healthcare, all across the world, within academic medical centers and private practices, regulatory agencies and medical product manufacturers, insurance companies and policy centers, and at the heart of every patient-provider interaction, there is a common challenge: how do we apply what we’ve learned from the past to make better decisions for the future?
For more than a decade, many have argued for the vision of a learning healthcare system, “designed to generate and apply the best evidence for the collaborative healthcare choices of each patient and provider; to drive the process of discovery as a natural outgrowth of patient care; and to ensure innovation, quality, safety, and value in healthcare”. (Olsen et al. 2007) A chief component of this ambition rests on the exciting prospect that patient-level data captured during the routine course of clinical care could be analyzed to produce real-world evidence, which in turn could be disseminated across the healthcare system to inform clinical practice. In 2007, the Institute of Medicine Roundtable on Evidence-Based Medicine issued a report which established a goal that “By the year 2020, 90 percent of clinical decisions will be supported by accurate, timely, and up-to-date clinical information, and will reflect the best available evidence.” (Olsen et al. 2007) While tremendous progress has been made on many different fronts, we still fall well short of these laudable aspirations.
Why? In part, because the journey from patient-level data to reliable evidence is an arduous one. There is no single defined path from data to evidence, and no single map that can help to navigate along the way. In fact, there is no single notion of “data,” nor is there a singular notion of “evidence.”
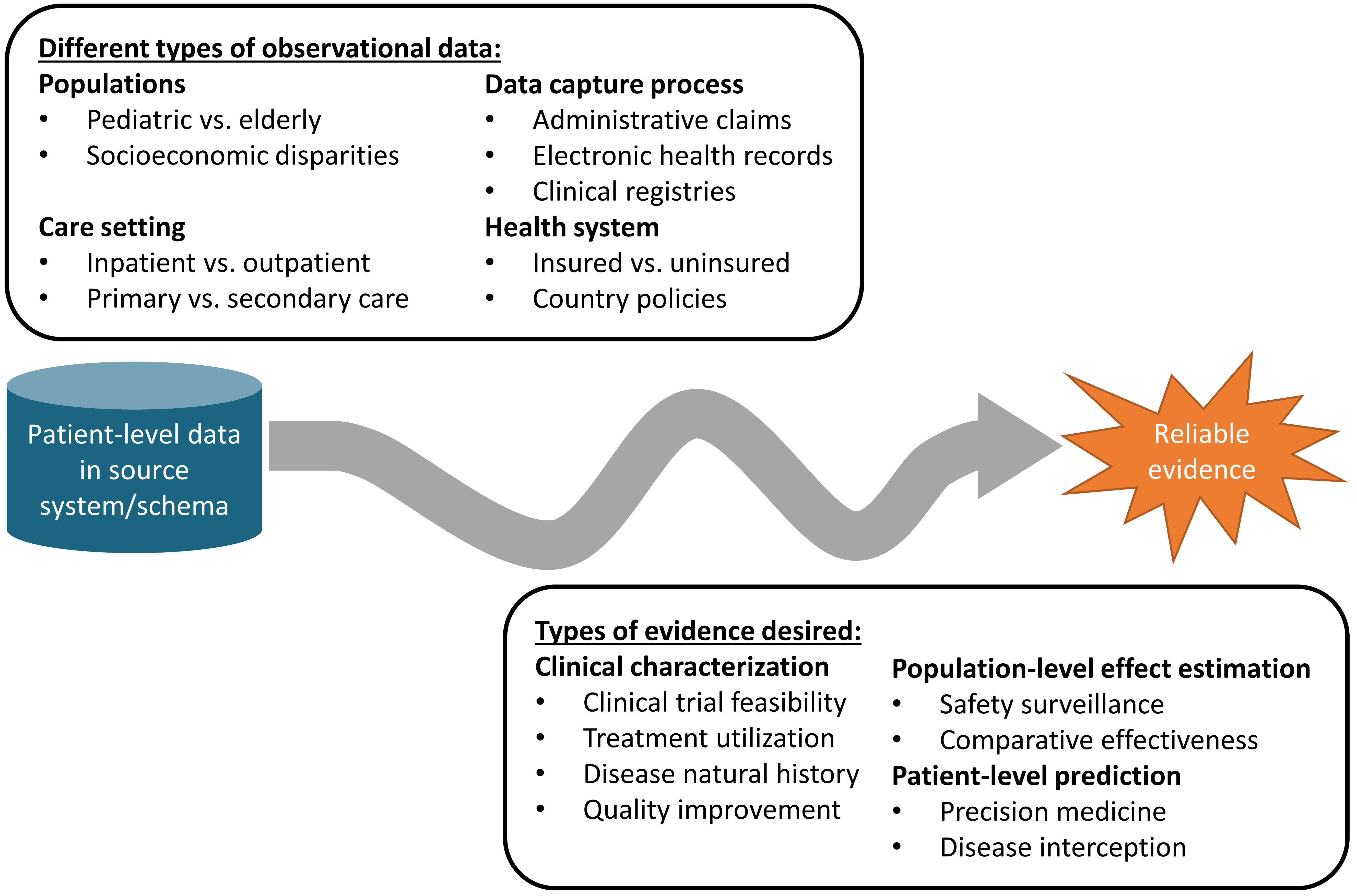
Figure 1.1: The journey from data to evidence
There are different types of observational databases which capture disparate patient-level data in source systems. These databases are as diverse as the healthcare system itself, reflecting different populations, care settings, and data capture processes. There are also different types of evidence that could be useful to inform decision-making, which can be classified by the analytic use cases of clinical characterization, population-level effect estimation, and patient-level prediction. Independent from the origin (source data) and desired destination (evidence), the challenge is further complicated by the breadth of clinical, scientific, and technical competencies that are required to undertake the journey. It requires a thorough understanding of health informatics, including its full provenance of the source data from the point-of-care interaction between a patient and provider through the administrative and clinical systems and into final repository, with an appreciation of the biases that can arise as part of the health policies and behavioral incentives associated with the data capture and curation processes. It requires mastery of epidemiologic principles and statistical methods to translate a clinical question into an observational study design properly suited to produce a relevant answer. It requires the technical ability to implement and execute computationally-efficient data science algorithms to datasets containing millions of patients with billions of clinical observations over years of longitudinal follow-up. It requires the clinical knowledge to synthesize what has been learned across an observational data network with evidence from other information sources, and to determine how this new knowledge should impact health policy and clinical practice. Accordingly, it is quite rare that any one individual would possess the requisite skills and resources to successfully trek from data to evidence alone. Instead, the journey often requires collaboration across multiple individuals and organizations to ensure that the best available data are analyzed using the most appropriate methods to produce the evidence that all stakeholders can trust and use in their decision-making processes.
1.2 Observational Medical Outcomes Partnership
A notable example of collaboration in observational research was the Observational Medical Outcomes Partnership (OMOP). OMOP was a public-private partnership, chaired by the US Food and Drug Administration, administered by the Foundation for the National Institutes of Health, and funded by a consortium of pharmaceutical companies that collaborated with academic researchers and health data partners to establish a research program that sought to advance the science of active medical product safety surveillance using observational healthcare data. (Stang et al. 2010) OMOP established a multi-stakeholder governance structure and designed a series of methodological experiments to empirically test the performance of alternative epidemiologic designs and statistical methods when applied to an array of administrative claims and electronic health records databases for the task of identifying true drug safety associations and discriminating them from false positive findings.
Recognizing the technical challenges of conducting research across disparate observational databases in both a centralized environment and a distributed research network, the team designed the OMOP Common Data Model (CDM) as a mechanism to standardize the structure, content and semantics of observational data and to make it possible to write statistical analysis code once that could be re-used at every data site. (Overhage et al. 2012) The OMOP experiments demonstrated it was feasible to establish a common data model and standardized vocabularies that could accommodate different data types from different care settings and represented by different source vocabularies in a manner that could facilitate cross-institutional collaboration and computationally-efficient analytics.
From its inception, OMOP adopted an open-science approach, placing all of its work products, including study designs, data standards, analysis code, and empirical results, in the public domain to promote transparency, build confidence in the research that OMOP was conducting, but also to provide a community resource that could be repurposed to advance others’ research objectives. While OMOP’s original focus was drug safety, the OMOP CDM continually evolved to support an expanded set of analytical use cases, including comparative effectiveness of medical interventions and health system policies.
And while OMOP was successful in completing its large-scale empirical experiments, (Ryan et al. 2012, 2013) developing methodological innovations, (Schuemie et al. 2014) and generating useful knowledge that has informed the appropriate use of observational data for safety decision-making, (Madigan et al. 2013; Madigan, Ryan, and Schuemie 2013) the legacy of OMOP may be more remembered for its early adoption of open-science principles and its stimulus that motivated the formation of the OHDSI community.
When the OMOP project had completed, having fulfilled its mandate to perform methodological research to inform the FDA’s active surveillance activities, the team recognized the end of the OMOP journey needed to become the start of a new journey together. In spite of OMOP’s methodological research providing tangible insights into scientific best practices that could demonstrably improve the quality of evidence generated from observational data, adoption of those best practices was slow. Several barriers were identified, including: 1) fundamental concerns about observational data quality that were felt to be higher priority to address before analytics innovations; 2) insufficient conceptual understanding of the methodological problems and solutions; 3) inability to independently implement solutions within their local environment; 4) uncertainty over whether these approaches were applicable to their clinical problems of interest. The one common thread to every barrier was the sense that one person alone didn’t have everything they needed to enact change by themselves, but with some collaborative support all issues could be overcome. But several areas of collaboration were needed:
- Collaboration on establishing open-community data standards, standardized vocabularies and ETL (Extract-Transform-Load) conventions that would increase confidence in the underlying data quality and promote consistency in structure, content, and semantics to enable standardized analytics.
- Collaboration on methodological research beyond drug safety to establish best practices more broadly for clinical characterization, population-level effect estimation, and patient-level prediction. Collaboration on open-source analytics development, to codify the scientific best practices proven through methodological research and make accessible as publicly available tools that can be easily adopted by the research community.
- Collaboration on clinical applications that address important health questions of shared interest across the community by collectively navigating the journey from data to evidence.
From this insight, OHDSI was born.
1.3 OHDSI as an Open-Science Collaborative
Observational Health Data Sciences and Informatics (OHDSI, pronounced “Odyssey”) is an open-science community that aims to improve health by empowering the community to collaboratively generate the evidence that promotes better health decisions and better care. (Hripcsak et al. 2015) OHDSI conducts methodological research to establish scientific best practices for the appropriate use of observational health data, develops open-source analytics software that codify these practices into consistent, transparent, reproducible solutions, and applies these tools and practices to clinical questions to generate evidence that can guide healthcare policy and patient care.
1.3.1 Our Mission
To improve health by empowering a community to collaboratively generate the evidence that promotes better health decisions and better care.
1.3.2 Our Vision
A world in which observational research produces a comprehensive understanding of health and disease.
1.3.3 Our Objectives
Innovation: Observational research is a field which will benefit greatly from disruptive thinking. We actively seek and encourage fresh methodological approaches in our work.
Reproducibility: Accurate, reproducible, and well-calibrated evidence is necessary for health improvement.
Community: Everyone is welcome to actively participate in OHDSI, whether you are a patient, a health professional, a researcher, or someone who simply believes in our cause.
Collaboration: We work collectively to prioritize and address the real-world needs of our community’s participants.
Openness: We strive to make all our community’s proceeds open and publicly accessible, including the methods, tools and the evidence that we generate.
Beneficence: We seek to protect the rights of individuals and organizations within our community at all times.
1.4 OHDSI’s Progress
OHDSI has grown since its inception in 2014 to include over 2,500 collaborators on its online forums from different stakeholders, including academia, medical product industry, regulators, government, payers, technology providers, health systems, clinicians, patients, and representing different disciplines, including computer science, epidemiology, statistics, biomedical informatics, health policy, and clinical sciences. A listing of self-identified OHDSI collaborators is available on the OHDSI website.1 The OHDSI collaborator map (Figure 1.2) highlights the breadth and diversity of the international community.
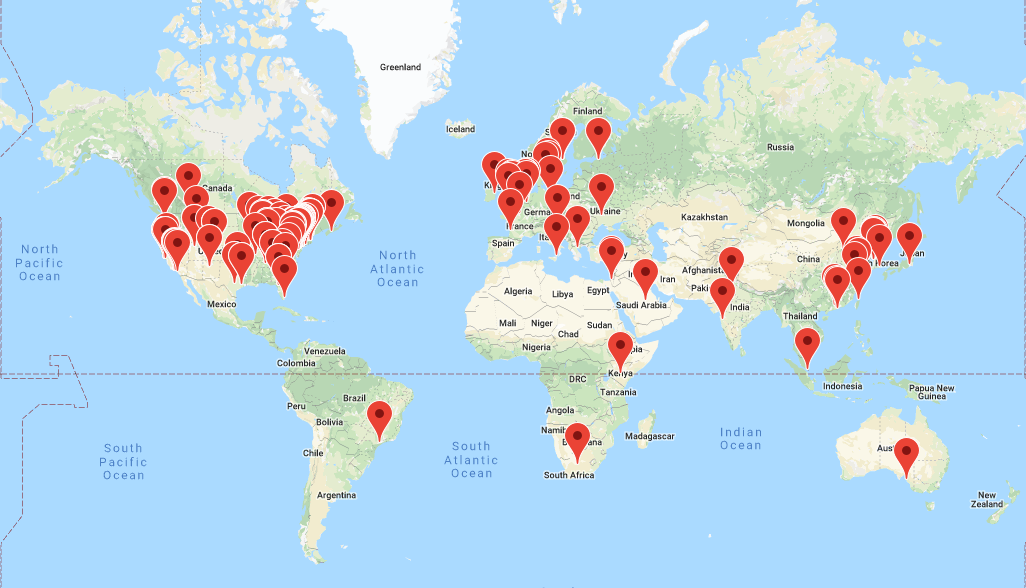
Figure 1.2: Map of OHDSI collaborators as of August, 2019
As of August, 2019, OHDSI has also established a data network of over 100 different healthcare databases from over 20 countries, collectively capturing over one billion patient records by applying a distributed network approach using an open-community data standard it maintains, the OMOP CDM. A distributed network means that patient-level data are not required to be shared between individuals or organizations. Instead, research questions are asked by individuals within the community in the form of a study protocol and accompanied by analysis code that generates evidence as a set of aggregated summary statistics, and only these summary statistics are shared amongst the partners who opt to collaborate in the study. With the OHDSI distributed network, each data partner retains full autonomy over the use of their patient-level data, and continues to observe the data governance policies within their respective institutions.
The OHDSI developer community has created a robust library of open-source analytics tools atop the OMOP CDM to support 3 use cases: 1) clinical characterization for disease natural history, treatment utilization, and quality improvement; 2) population-level effect estimation to apply causal inference methods for medical product safety surveillance and comparative effectiveness; and 3) patient-level prediction to apply machine learning algorithms for precision medicine and disease interception. OHDSI developers have also developed applications to support adoption of the OMOP CDM, data quality assessment, and facilitation of OHDSI network studies. These tools include back-end statistical packages built in R and Python, and front-end web applications developed in HTML and Javascript. All OHDSI tools are open source and publicly available via Github.2
OHDSI’s open science community approach, coupled with its open-source tools, has enabled tremendous advances in observational research. One of the first OHDSI network analyses examined treatment pathways across three chronic diseases: diabetes, depression, and hypertension. Published in the Proceedings of the National Academy of Science, it was one of the largest observational studies ever conducted, with results from 11 data sources covering more than 250 million patients and revealed tremendous geographic differences and patient heterogeneity in treatment choices that had never been previously observable. (Hripcsak et al. 2016) OHDSI has developed new statistical methods for confounding adjustment (Tian, Schuemie, and Suchard 2018) and evaluating the validity of observational evidence for causal inference, (Schuemie, Hripcsak, et al. 2018) and it has applied these approaches in multiple contexts, from an individual safety surveillance question in epilepsy (Duke et al. 2017) to comparative effectiveness of second-line diabetes medications (Vashisht et al. 2018) to a large-scale population-level effect estimation study for comparative safety of depression treatments. (Schuemie, Ryan, et al. 2018) The OHDSI community has also established a framework for how to responsibly apply machine learning algorithms to observational healthcare data, (Reps et al. 2018) which has been applied across various therapeutic areas. (Johnston et al. 2019; Cepeda et al. 2018; Reps, Rijnbeek, and Ryan 2019)
1.5 Collaborating in OHDSI
Since OHDSI is a community aimed to empower collaboration to generate evidence, what does it mean to be an OHDSI collaborator? If you are someone who believes in OHDSI’s mission and is interested in making a contribution anywhere along the journey from data to evidence, then OHDSI can be the community for you. Collaborators can be individuals who have access to patient-level data who are interested in seeing that data put to use to generate evidence. Collaborators can be methodologists interested in establishing scientific best practices and evaluating alternative approaches. Collaborators can be software developers who are interested in applying their programming skills to create tools that can be used by the rest of the community. Collaborators can be clinical researchers who have important public health questions and are seeking to provide the evidence to those questions to the broader healthcare community through publication and other forms of dissemination. Collaborators can be individuals or organizations who believe in this common cause for public health and wish to provide resources to ensure that the community can sustain itself and continue its mission, including hosting community activities and training sessions around the world. No matter your disciplinary background or stakeholder affiliation, OHDSI seeks to be a place where individuals can work together towards a common purpose, each making their individual contributions which collectively can advance healthcare. If you are interested in joining the journey, check out Chapter 2 (“Where To Begin”) for how to get started.
1.6 Summary
OHDSI’s mission is to improve health by empowering a community to collaboratively generate the evidence that promotes better health decisions and better care.
Our vision is a world in which observational research produces a comprehensive understanding of health and disease, which will be achieved through our objectives of innovation, reproducibility, community, collaboration, openness, and beneficence.
OHDSI collaborators are focused on open-community data standards, methodological research, open-source analytics development, and clinical applications to improve the journey from data to evidence.
References
Cepeda, M. S., J. Reps, D. Fife, C. Blacketer, P. Stang, and P. Ryan. 2018. “Finding treatment-resistant depression in real-world data: How a data-driven approach compares with expert-based heuristics.” Depress Anxiety 35 (3): 220–28.
Duke, J. D., P. B. Ryan, M. A. Suchard, G. Hripcsak, P. Jin, C. Reich, M. S. Schwalm, et al. 2017. “Risk of angioedema associated with levetiracetam compared with phenytoin: Findings of the observational health data sciences and informatics research network.” Epilepsia 58 (8): e101–e106.
Hripcsak, George, Jon D Duke, Nigam H Shah, Christian G Reich, Vojtech Huser, Martijn J Schuemie, Marc A Suchard, et al. 2015. “Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers.” Studies in Health Technology and Informatics 216: 574–78. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4815923/.
Hripcsak, George, Patrick B. Ryan, Jon D. Duke, Nigam H. Shah, Rae Woong Park, Vojtech Huser, Marc A. Suchard, et al. 2016. “Characterizing treatment pathways at scale using the OHDSI network.” Proceedings of the National Academy of Sciences 113 (27): 7329–36. https://doi.org/10.1073/pnas.1510502113.
Johnston, S. S., J. M. Morton, I. Kalsekar, E. M. Ammann, C. W. Hsiao, and J. Reps. 2019. “Using Machine Learning Applied to Real-World Healthcare Data for Predictive Analytics: An Applied Example in Bariatric Surgery.” Value Health 22 (5): 580–86.
Madigan, D., P. B. Ryan, and M. Schuemie. 2013. “Does design matter? Systematic evaluation of the impact of analytical choices on effect estimates in observational studies.” Ther Adv Drug Saf 4 (2): 53–62.
Madigan, D., P. B. Ryan, M. Schuemie, P. E. Stang, J. M. Overhage, A. G. Hartzema, M. A. Suchard, W. DuMouchel, and J. A. Berlin. 2013. “Evaluating the impact of database heterogeneity on observational study results.” Am. J. Epidemiol. 178 (4): 645–51.
Olsen, LeighAnne, Dara Aisner, J Michael McGinnis, and others. 2007. The Learning Healthcare System: Workshop Summary. Natl Academy Pr.
Overhage, J. M., P. B. Ryan, C. G. Reich, A. G. Hartzema, and P. E. Stang. 2012. “Validation of a common data model for active safety surveillance research.” J Am Med Inform Assoc 19 (1): 54–60.
Reps, J. M., P. R. Rijnbeek, and P. B. Ryan. 2019. “Identifying the DEAD: Development and Validation of a Patient-Level Model to Predict Death Status in Population-Level Claims Data.” Drug Saf, May.
Reps, J. M., M. J. Schuemie, M. A. Suchard, P. B. Ryan, and P. R. Rijnbeek. 2018. “Design and implementation of a standardized framework to generate and evaluate patient-level prediction models using observational healthcare data.” Journal of the American Medical Informatics Association 25 (8): 969–75. https://doi.org/10.1093/jamia/ocy032.
Ryan, P. B., D. Madigan, P. E. Stang, J. M. Overhage, J. A. Racoosin, and A. G. Hartzema. 2012. “Empirical assessment of methods for risk identification in healthcare data: results from the experiments of the Observational Medical Outcomes Partnership.” Stat Med 31 (30): 4401–15.
Ryan, P. B., P. E. Stang, J. M. Overhage, M. A. Suchard, A. G. Hartzema, W. DuMouchel, C. G. Reich, M. J. Schuemie, and D. Madigan. 2013. “A comparison of the empirical performance of methods for a risk identification system.” Drug Saf 36 Suppl 1 (October): S143–158.
Schuemie, M. 2018. “Empirical confidence interval calibration for population-level effect estimation studies in observational healthcare data.” Proc. Natl. Acad. Sci. U.S.A. 115 (11): 2571–7.
Schuemie, M. J., P. B. Ryan, W. DuMouchel, M. A. Suchard, and D. Madigan. 2014. “Interpreting observational studies: why empirical calibration is needed to correct p-values.” Stat Med 33 (2): 209–18.
Schuemie, M. J., P. B. Ryan, G. Hripcsak, D. Madigan, and M. A. Suchard. 2018. “Improving reproducibility by using high-throughput observational studies with empirical calibration.” Philos Trans A Math Phys Eng Sci 376 (2128).
Stang, P. E., P. B. Ryan, J. A. Racoosin, J. M. Overhage, A. G. Hartzema, C. Reich, E. Welebob, T. Scarnecchia, and J. Woodcock. 2010. “Advancing the science for active surveillance: rationale and design for the Observational Medical Outcomes Partnership.” Ann. Intern. Med. 153 (9): 600–606.
Tian, Y., M. J. Schuemie, and M. A. Suchard. 2018. “Evaluating large-scale propensity score performance through real-world and synthetic data experiments.” Int J Epidemiol 47 (6): 2005–14.
Vashisht, R., K. Jung, A. Schuler, J. M. Banda, R. W. Park, S. Jin, L. Li, et al. 2018. “Association of Hemoglobin A1c Levels With Use of Sulfonylureas, Dipeptidyl Peptidase 4 Inhibitors, and Thiazolidinediones in Patients With Type 2 Diabetes Treated With Metformin: Analysis From the Observational Health Data Sciences and Informatics Initiative.” JAMA Netw Open 1 (4): e181755.