Chapter 5 Standardized Vocabularies
Chapter leads: Christian Reich & Anna Ostropolets
The OMOP Standardized Vocabularies, often referred to simply as “the Vocabulary”, are a foundational part of the OHDSI research network, and an integral part of the Common Data Model (CDM). They allow standardization of methods, definitions and results by defining the content of the data, paving the way for true remote (behind the firewall) network research and analytics. Usually, finding and interpreting the content of observational healthcare data, whether it is structured data using coding schemes or laid down in free text, is passed all the way through to the researcher, who is faced with a myriad of different ways to describe clinical events. OHDSI requires harmonization not only to a standardized format, but also to a rigorous standard content.
In this chapter we first describe the main principles of the Standardized Vocabularies, their components, and the relevant rules, conventions and some typical situations, all of which are necessary to understand and utilizing this foundational resource. We also point out where the support of the community is required to continuously improve it.
5.1 Why Vocabularies, and Why Standardizing
Medical vocabularies go back to the Bills of Mortality in medieval London to manage outbreaks of the plague and other diseases (see Figure 5.1).

Figure 5.1: 1660 London Bill of Mortality, showing the cause of death for deceased inhabitants using a classification system of 62 diseases known at the time.
Since then, the classifications have greatly expanded in size and complexity and spread into other aspects of healthcare, such as procedures and services, drugs, medical devices, etc. The main principles have remained the same: they are controlled vocabularies, terminologies, hierarchies or ontologies that some healthcare communities agree upon for the purpose of capturing, classifying and analyzing patient data. Many of these vocabularies are maintained by public and government agencies with a long-term mandate for doing so. For example, the World Health Organization (WHO) produces the International Classification of Disease (ICD) with the recent addition of its 11th revision (ICD11). Local governments create country-specific versions, such as ICD10CM (USA), ICD10GM (Germany), etc. Governments also control the marketing and sale of drugs and maintain national repositories of such certified drugs. Vocabularies are also used in the private sector, either as commercial products or for internal use, such as electronic health record (EHR) systems or for medical insurance claim reporting.
As a result, each country, region, healthcare system and institution tends to have their own classifications that would most likely only be relevant where it is used. This myriad of vocabularies prevents interoperability of the systems they are used in. Standardization is the key that enables patient data exchange, unlocks health data analysis on a global level and allows systematic and standardized research, including performance characterization and quality assessment. To address that problem, multinational organizations have sprung up and started creating broad standards, such as the WHO mentioned above and the Standard Nomenclature of Medicine (SNOMED) or Logical Observation Identifiers Names and Codes (LOINC). In the US, the Health IT Standards Committee (HITAC) recommends the use of SNOMED, LOINC and the drug vocabulary RxNorm as standards to the National Coordinator for Health IT (ONC) for use in a common platform for nationwide health information exchange across diverse entities.
OHDSI developed the OMOP CDM, a global standard for observational research. As part of the CDM, the OMOP Standardized Vocabularies are available for two main purposes:
- Common repository of all vocabularies used in the community
- Standardization and mapping for use in research
The Standardized Vocabularies are available to the community free of charge and must be used for OMOP CDM instance as its mandatory reference table.
5.1.1 Building the Standardized Vocabularies
All vocabularies of the Standardized Vocabularies are consolidated into the same common format. This relieves the researchers from having to understand and handle multiple different formats and life-cycle conventions of the originating vocabularies. All vocabularies are regularly refreshed and incorporated using the Pallas system.22 It is built and run by the OHDSI Vocabulary Team, which is part of the overall OMOP CDM Workgroup. If you find mistakes please report and help improve our resource by posting in either the OHDSI Forums23 or CDM Github page.24
5.1.2 Access to the Standardized Vocabularies
In order to obtain the Standardized Vocabularies, you do not have to run Pallas yourself. Instead, you can download the latest version from ATHENA25 and load it into your local database. ATHENA also allows faceted search of the Vocabularies.
To download a zip file with all Standardized Vocabularies tables select all the vocabularies you need for your OMOP CDM. Vocabularies with Standard Concepts (see Section 5.2.6) and very common usage are preselected. Add vocabularies that are used in your source data. Vocabularies that are proprietary have no select button. Click on the “License required” button to incorporate such a vocabulary into your list. The Vocabulary Team will contact you and request you demonstrate your license or help you connect to the right folks to obtain one.
5.1.3 Source of Vocabularies: Adopt Versus Build
OHDSI generally prefers adopting existing vocabularies, rather than de-novo construction, because (i) many vocabularies have already been utilized in observational data in the community, and (ii) construction and maintenance of vocabularies is complex and requires the input of many stakeholders over long periods of time to mature. For that reason, dedicated organizations provide vocabularies, which are subject to a life-cycle of generation, deprecation, merging and splitting (see Section 5.2.10). Currently, OHDSI only produces internal administrative vocabularies like Type Concepts (e.g. condition type concepts). The only exception is RxNorm Extension, a vocabulary covering drugs that are only used outside the United States (see Section 5.6.9).
5.2 Concepts
All clinical events in the OMOP CDM are expressed as concepts, which represent the semantic notion of each event. They are the fundamental building blocks of the data records, making almost all tables fully normalized with few exceptions. Concepts are stored in the CONCEPT table (see Figure 5.2).
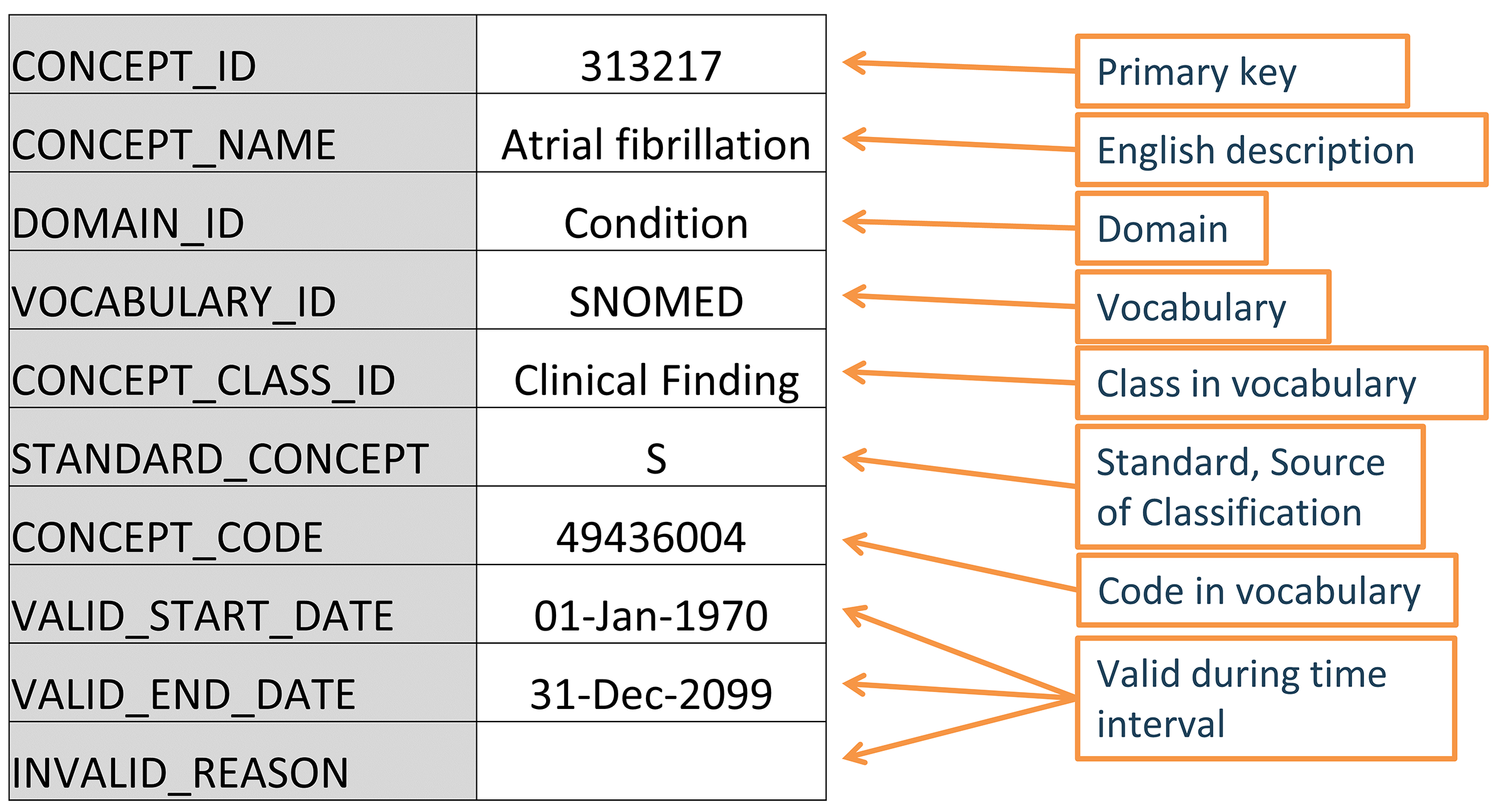
Figure 5.2: Standard representation of vocabulary concepts in the OMOP CDM. The example provided is the CONCEPT table record for the SNOMED code for Atrial Fibrillation.
This system is meant to be comprehensive, i.e. there are enough concepts to cover any event relevant to the patient’s healthcare experience (e.g. conditions, procedures, exposures to drug, etc.) as well as some of the administrative information of the healthcare system (e.g. visits, care sites, etc.).
5.2.1 Concept IDs
Each concept is assigned a concept ID to be used as a primary key. This meaningless integer ID, rather than the original code from the vocabulary, is used to record data in the CDM event tables.
5.2.2 Concept Names
Each concept has one name. Names are always in English. They are imported from the source of the vocabulary. If the source vocabulary has more than one name, the most expressive is selected and the remaining ones are stored in the CONCEPT_SYNONYM table under the same CONCEPT_ID key. Non-English names are recorded in CONCEPT_SYNONYM as well, with the appropriate language concept ID in the LANGUAGE_CONCEPT_ID field. The name is 255 characters long, which means that very long names get truncated and the full-length version recorded as another synonym, which can hold up to 1000 characters.
5.2.3 Domains
Each concept is assigned a domain in the DOMAIN_ID field, which in contrast to the numerical CONCEPT_ID is a short case-sensitive unique alphanumeric ID for the domain. Examples of such domain identifiers are “Condition,” “Drug,” “Procedure,” “Visit,” “Device,” “Specimen,” etc. Ambiguous or pre-coordinated (combination) concepts can belong to a combination domain, but Standard Concepts (see Section 5.2.6) are always assigned a singular domain. Domains also direct to which CDM table and field a clinical event or event attribute is recorded. Domain assignments are an OMOP-specific feature done during vocabulary ingestion using a heuristic laid out in Pallas. Source vocabularies tend to combine codes of mixed domains, but to a varying degree (see Figure 5.3).
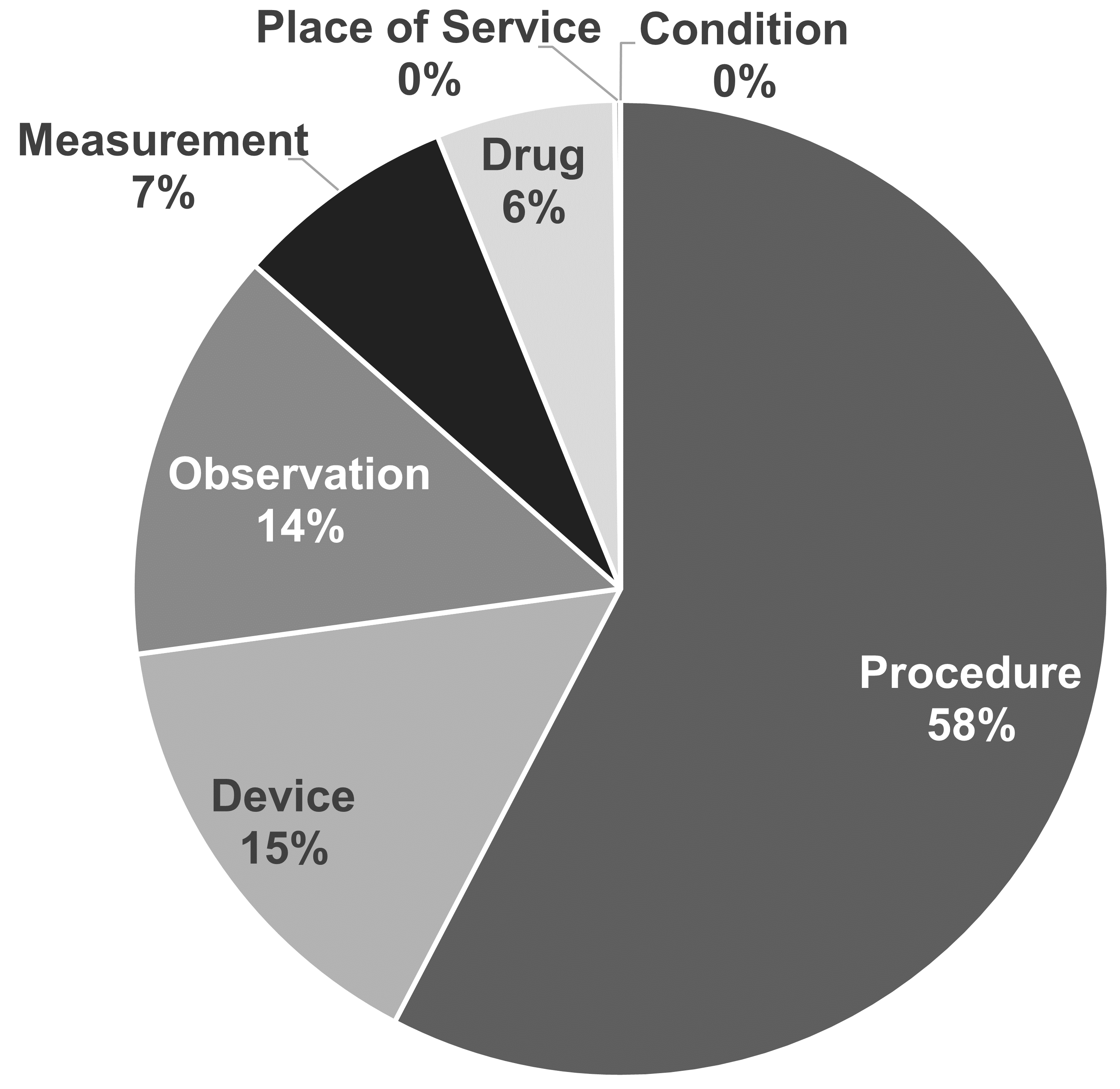
Figure 5.3: Domain assignment in procedure vocabularies CPT4 and HCPCS. By intuition, these vocabularies should contain codes and concepts of a single domain, but in reality they are mixed.
The domain heuristic follows the definitions of the domains. These definitions are derived from the table and field definitions in the CDM (see Chapter 4). The heuristic is not perfect; there are grey zones (see Section 5.6 “Special Situations”). If you find concept domains assigned incorrectly please report and help improve the process through a Forums or CDM issue post.
5.2.4 Vocabularies
Each vocabulary has a short case-sensitive unique alphanumeric ID, which generally follows the abbreviated name of the vocabulary, omitting dashes. For example, ICD-9-CM has the vocabulary ID “ICD9CM”. There are 111 vocabularies currently supported by OHDSI, of which 78 are adopted from external sources, while the rest are OMOP-internal vocabularies. These vocabularies are typically refreshed at a quarterly schedule. The source and the version of the vocabularies is defined in the VOCABULARY reference file.
5.2.5 Concept Classes
Some vocabularies classify their codes or concepts, denoted through their case-sensitive unique alphanumerical IDs. For example, SNOMED has 33 such concept classes, which SNOMED refers to as “semantic tags”: clinical finding, social context, body structure, etc. These are vertical divisions of the concepts. Others, such as MedDRA or RxNorm, have concept classes classifying horizontal levels in their stratified hierarchies. Vocabularies without any concept classes, such as HCPCS, use the vocabulary ID as the Concept Class ID.
| Concept class subdivision principle | Vocabulary |
|---|---|
| Horizontal | all drug vocabularies, ATC, CDТ, Episode, HCPCS, HemOnc, ICDs, MedDRA, OSM, Census |
| Vertical | CIEL, HES Specialty, ICDO3, MeSH, NAACCR, NDFRT, OPCS4, PCORNET, Plan, PPI, Provider, SNOMED, SPL, UCUM |
| Mixed | CPT4, ISBT, LOINC |
| None | APC, all Type Concepts, Ethnicity, OXMIS, Race, Revenue Code, Sponsor, Supplier, UB04s, Visit |
Horizontal concept classes allow you to determine a specific hierarchical level. For example, in the drug vocabulary RxNorm the concept class “Ingredient” defines the top level of the hierarchy. In the vertical model, members of a concept class can be of any hierarchical level from the top to the very bottom.
5.2.6 Standard Concepts
One concept representing the meaning of each clinical event is designated the Standard. For example, MESH code D001281, CIEL code 148203, SNOMED code 49436004, ICD9CM code 427.31 and Read code G573000 all define “Atrial fibrillation” in the condition domain, but only the SNOMED concept is Standard and represents the condition in the data. The others are designated non-standard or source concepts and mapped to the Standard ones. Standard Concepts are indicated through an “S” in the STANDARD_CONCEPT field. And only these Standard Concepts are used to record data in the CDM fields ending in "_CONCEPT_ID".
5.2.7 Non-Standard Concepts
Non-standard concepts are not used to represent the clinical events, but they are still part of the Standardized Vocabularies, and are often found in the source data. For that reason, they are also called “source concepts”. The conversion of source concepts to Standard Concepts is a process called “mapping” (see Section 5.3.1). Non-standard concepts have no value (NULL) In the STANDARD_CONCEPT field.
5.2.8 Classification Concepts
These concepts are not Standard, and hence cannot be used to represent the data. But they are participating in the hierarchy with the Standard Concepts, and can therefore be used to perform hierarchical queries. For example, querying for all descendants of MedDRA code 10037908 (not visible for users who have not obtained a MedDRA license, see Section 5.1.2 for access restrictions) will retrieve the Standard SNOMED concept for Atrial Fibrillation (see Section 5.4 for hierarchical queries using the CONCEPT_ANCESTOR table) - see Figure 5.4.
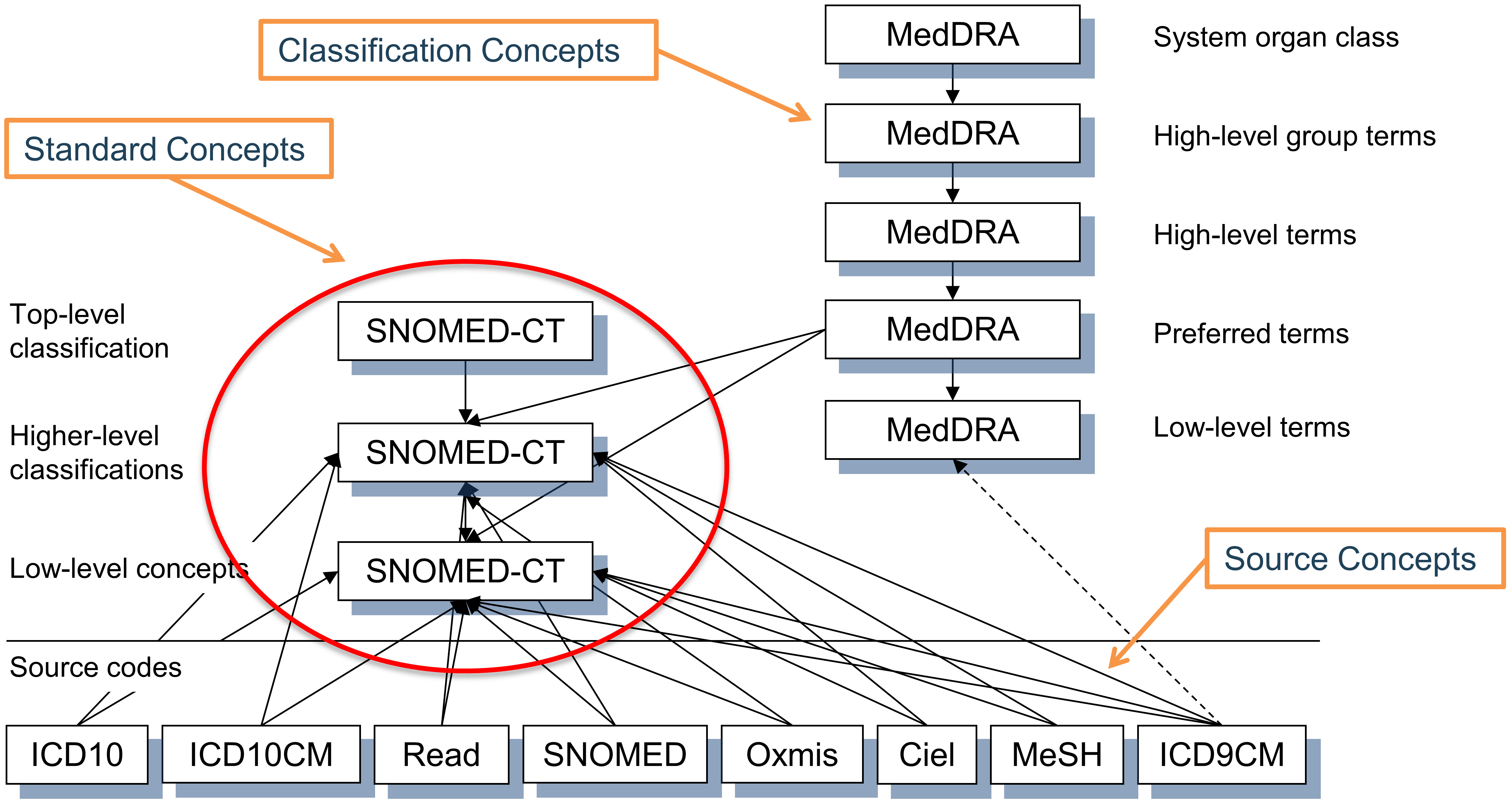
Figure 5.4: Standard, non-standard source and classification concepts and their hierarchical relationships in the condition domain. SNOMED is used for most standard condition concepts (with some oncology-related concepts derived from ICDO3), MedDRA concepts are used for hierarchical classification concepts, and all other vocabularies contain non-standard or source concepts, which do not participate in the hierarchy.
The choice of concept designation as Standard, non-standard and classification is typically done for each domain separately at the vocabulary level. This is based on the quality of the concepts, the built-in hierarchy and the declared purpose of the vocabulary. Also, not all concepts of a vocabulary are used as Standard Concepts. The designation is separate for each domain, each concept has to be active (see Section 5.2.10) and there might be an order of precedence if more than one concept from different vocabularies compete for the same meaning. In other words, there is no such a thing as a “standard vocabulary.” See Table 5.2 for examples.
| Domain | for Standard Concepts | for source concepts | for classification concepts |
|---|---|---|---|
| Condition | SNOMED, ICDO3 | SNOMED Veterinary | MedDRA |
| Procedure | SNOMED, CPT4, HCPCS, ICD10PCS, ICD9Proc, OPCS4 | SNOMED Veterinary, HemOnc, NAACCR | None at this point |
| Measurement | SNOMED, LOINC | SNOMED Veterinary, NAACCR, CPT4, HCPCS, OPCS4, PPI | None at this point |
| Drug | RxNorm, RxNorm Extension, CVX | HCPCS, CPT4, HemOnc, NAAACCR | ATC |
| Device | SNOMED | Others, currently not normalized | None at this point |
| Observation | SNOMED | Others | None at this point |
| Visit | CMS Place of Service, ABMT, NUCC | SNOMED, HCPCS, CPT4, UB04 | None at this point |
5.2.9 Concept Codes
Concept codes are the identifiers used in the source vocabularies. For example, ICD9CM or NDC codes are stored in this field, while the OMOP tables use the concept ID as a foreign key into the CONCEPT table. The reason is that the name space overlaps across vocabularies, i.e. the same code can exist in different vocabularies with completely different meanings (see Table 5.3)
| Concept ID | Concept Code | Concept Name | Domain ID | Vocabulary ID | Concept Class |
|---|---|---|---|---|---|
| 35803438 | 1001 | Granulocyte colony-stimulating factors | Drug | HemOnc | Component Class |
| 35942070 | 1001 | AJCC TNM Clin T | Measurement | NAACCR | NAACCR Variable |
| 1036059 | 1001 | Antipyrine | Drug | RxNorm | Ingredient |
| 38003544 | 1001 | Residential Treatment - Psychiatric | Revenue Code | Revenue Code | Revenue Code |
| 43228317 | 1001 | Aceprometazine maleate | Drug | BDPM | Ingredient |
| 45417187 | 1001 | Brompheniramine Maleate, 10 mg/mL injectable solution | Drug | Multum | Multum |
| 45912144 | 1001 | Serum | Specimen | CIEL | Specimen |
5.2.10 Life-Cycle
Vocabularies are rarely permanent corpora with a fixed set of codes. Instead, codes and concepts are added and get deprecated. The OMOP CDM is a model to support longitudinal patient data, which means it needs to support concepts that were used in the past and might no longer be active, as well as supporting new concepts and placing them into context. There are three fields in the CONCEPT table that describe the possible life-cycle statuses: VALID_START_DATE, VALID_END_DATE, and INVALID_REASON. Their values differ depending on the concept life-cycle status:
- Active or new concept
- Description: Concept in use.
- VALID_START_DATE: Day of instantiation of concept, if that is not known day of incorporation of concept in Vocabularies, if that is not known 1970-1-1.
- VALID_END_DATE: Set to 2099-12-31 as a convention to indicate “Might become invalid in an undefined future, but active right now”.
- INVALID_REASON: NULL
- Deprecated Concept with no successor
- Description: Concept inactive and cannot be used as Standard (see Section 5.2.6).
- VALID_START_DATE: Day of instantiation of concept, if that is not known day of incorporation of concept in Vocabularies, if that is not known 1970-1-1.
- VALID_END_DATE: Day in the past indicating deprecation, or if that is not known day of vocabulary refresh where concept in vocabulary went missing or set to inactive.
- INVALID_REASON: “D”
- Upgraded Concept with successor
- Description: Concept inactive, but has defined successor. These are typically concepts which went through de-duplication.
- VALID_START_DATE: Day of instantiation of concept, if that is not known day of incorporation of concept in Vocabularies, if that is not known 1970-1-1.
- VALID_END_DATE: Day in the past indicating an upgrade, or if that is not known day of vocabulary refresh where the upgrade was included.
- INVALID_REASON: “U”
- Reused code for another new concept
- Description: The vocabulary reused the concept code of this deprecated concept for a new concept.
- VALID_START_DATE: Day of instantiation of concept, if that is not known day of incorporation of concept in Vocabularies, if that is not known 1970-1-1.
- VALID_END_DATE: Day in the past indicating deprecation, or if that is not known day of vocabulary refresh where concept in vocabulary went missing or set to inactive.
- INVALID_REASON: “R”
In general, concept codes are not reused. But there are a few vocabularies that deviate from this rule, in particular HCPCS, NDC and DRG. For those, the same concept code appears in more than one concept of the same vocabulary. Their CONCEPT_ID value stays unique. These reused concept codes are marked with an “R” in the INVALID_REASON field, and the VALID_START_DATE to VALID_END_DATE period should be used to distinguish concepts with the same concept codes.
5.3 Relationships
Any two concepts can have a defined relationship, regardless of whether the two concepts belong to the same domain or vocabulary. The nature of the relationships is indicated in its short case-sensitive unique alphanumeric ID in the RELATIONSHIP_ID field of the CONCEPT_RELATIONSHIP table. Relationships are symmetrical, i.e. for each relationship an equivalent relationship exists, where the content of the fields CONCEPT_ID_1 and CONCEPT_ID_2 are swapped, and the RELATIONHSIP_ID is changed to its opposite. For example, the “Maps to” relationship has an opposite relationship “Mapped from.”
CONCEPT_RELATIONSHIP table records also have life-cycle fields RELATIONSHIP_START_DATE, RELATIONSHIP_END_DATE and INVALID_REASON. However, only active records with INVALID_REASON = NULL are available through ATHENA. Inactive relationships are kept in the Pallas system for internal processing only. The RELATIONSHIP table serves as the reference with the full list of relationship IDs and their reverse counterparts.
5.3.1 Mapping Relationships
These relationships provide translations from non-standard to Standard concepts, supported by two relationship ID pairs (see Table 5.4).
| Relationship ID pair | Purpose |
|---|---|
| “Maps to” and “Mapped from” | Mapping to Standard Concepts. Standard Concepts are mapped to themselves, non-standard concepts to Standard Concepts. Most non-standard and all Standard Concepts have this relationship to a Standard Concept. The former are stored in *_SOURCE_CONCEPT_ID, and the latter in the *_CONCEPT_ID fields. Classification concepts are not mapped. |
| “Maps to value” and “Value mapped from” | Mapping to a concept that represents a Value to be placed into the VALUE_AS_CONCEPT_ID fields of the MEASUREMENT and OBSERVATION tables. |
The purpose of these mapping relationships is to allow a crosswalk between equivalent concepts to harmonize how clinical events are represented in the OMOP CDM. This is a main achievement of the Standardized Vocabularies.
“Equivalent concepts” means it carries the same meaning, and, importantly, the hierarchical descendants cover the same semantic space. If an equivalent concept is not available and the concept is not Standard, it is still mapped, but to a slightly broader concept (so-called “up-hill mappings”). For example, ICD10CM W61.51 “Bitten by goose” has no equivalent in the SNOMED vocabulary, which is generally used for standard condition concepts. Instead, it is mapped to SNOMED 217716004 “Peck by bird,” losing the context of the bird being a goose. Up-hill mappings are only used if the loss of information is considered irrelevant to standard research use cases.
Some mappings connect a source concept to more than one Standard Concept. For example, ICD9CM 070.43 “Hepatitis E with hepatic coma” is mapped to both SNOMED 235867002 “Acute hepatitis E” as well as SNOMED 72836002 “Hepatic Coma.” The reason for this is that the original source concept is a pre-coordinated combination of two conditions, hepatitis and coma. SNOMED does not have that combination, which results in two records written for the ICD9CM record, one with each mapped Standard Concept.
Relationships “Maps to value” have the purpose of splitting of a value for OMOP CDM tables following an entity-attribute-value (EAV) model. This is typically the case in the following situations:
- Measurements consisting of a test and a result value
- Personal or family disease history
- Allergy to substance
- Need for immunization
In these situations, the source concept is a combination of the attribute (test or history) and the value (test result or disease). The “Maps to” relationship maps this source to the attribute concept, and the “Maps to value” to the value concept. See Figure 5.5 for an example.
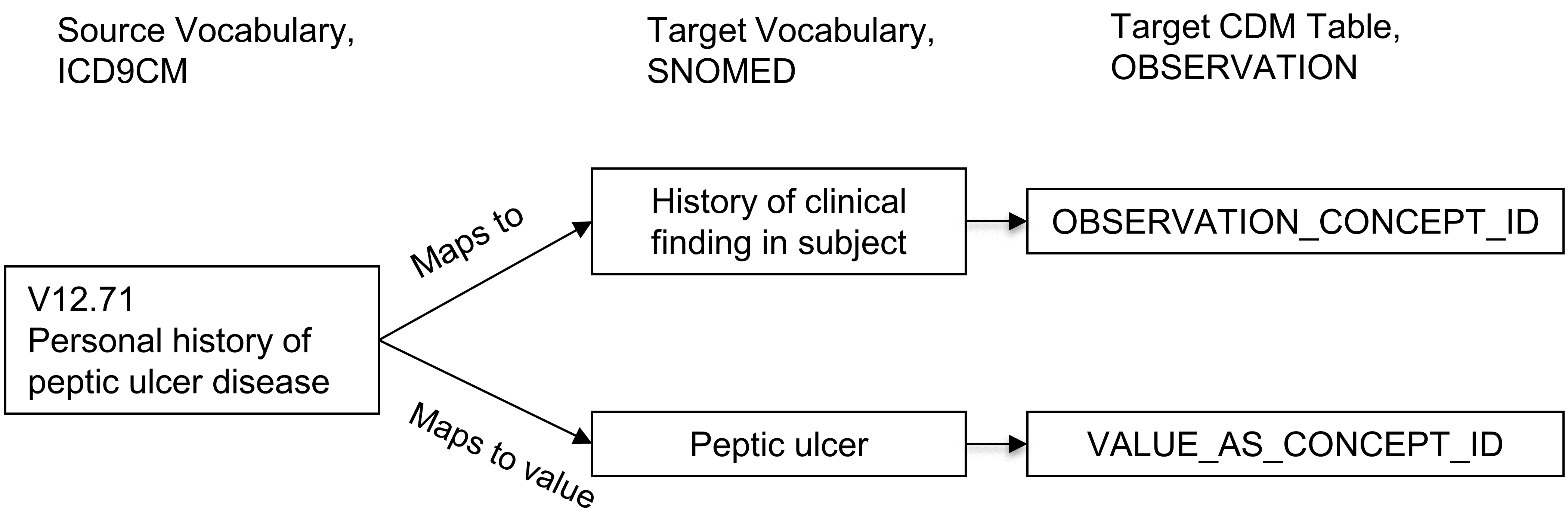
Figure 5.5: One-to-many mapping between source concept and Standard Concepts. A pre-coordinated concept is split into two concepts, one of which is the attribute (here history of clinical finding) and the other one is the value (peptic ulcer). While “Maps to” relationship will map to concepts of the measurement or observation domains, the ‘Maps to value" concepts have no domain restriction.
Mapping of concepts is another central feature of the OMOP Standardized Vocabularies provided for free and supporting the efforts of the community conducting Network Studies. Mapping relationships are derived from external sources or maintained manually by the Vocabulary Team. This means they are not perfect. If you find wrong or objectionable mapping relationships it is crucial that you report and help improve the process through a Forums or CDM issue post.
A more detailed description of mapping conventions can be found in the OHDSI Wiki.26
5.3.2 Hierarchical Relationships
Relationships which indicate a hierarchy are defined through the “Is a” - “Subsumes” relationship pair. Hierarchical relationships are defined such that the child concept has all the attributes of the parent concept, plus one or more additional attributes or a more precisely defined attribute. For example, SNOMED 49436004 “Atrial fibrillation” is related to SNOMED 17366009 “Atrial arrhythmia” through a “Is a” relationship. Both concepts have an identical set of attributes except the type of arrhythmia, which is defined as fibrillation in one but not the other. Concepts can have more than one parent and more than one child concept. In this example, SNOMED 49436004 “Atrial fibrillation” is also an “Is a” to SNOMED 40593004 “Fibrillation.”
5.3.3 Relationships Between Concepts of Different Vocabularies
These relationships are typically of the type “Vocabulary A - Vocabulary B equivalent”, which is either supplied by the original source of the vocabulary or is built by the OHDSI Vocabulary team. They may serve as approximate mappings but often times are less precise than the better curated mapping relationships. High-quality equivalence relationships (such as “Source - RxNorm equivalent”) are always duplicated by “Maps to” relationship.
5.3.4 Relationships Between Concepts of the Same Vocabulary
Internal vocabulary relationships are usually supplied by the vocabulary provider. Full descriptions can be found in the vocabulary documentation under the individual vocabulary at the OHDSI Wiki.27
Many of these define relationships between clinical events and can be used for information retrieval. For example, disorders of the urethra can be found by following the “Finding site of” relationship (see Table 5.5):
| CONCEPT_ID_1 | CONCEPT_ID_2 |
|---|---|
| 4000504 “Urethra part” | 36713433 “Partial duplication of urethra” |
| 4000504 “Urethra part” | 433583 “Epispadias” |
| 4000504 “Urethra part” | 443533 “Epispadias, male” |
| 4000504 “Urethra part” | 4005956 “Epispadias, female” |
The quality and comprehensiveness of these relationships varies depending on the quality in the original vocabulary. Generally, vocabularies that are used to draw Standard Concepts from, such as SNOMED, are chosen for the reason of their better curation and therefore tend to have higher quality internal relationships as well.
5.4 Hierarchy
Within a domain, standard and classification concepts are organized in a hierarchical structure and stored in the CONCEPT_ANCESTOR table. This allows querying and retrieving concepts and all their hierarchical descendants. These descendants have the same attributes as their ancestor, but also additional or more defined ones.
The CONCEPT_ANCESTOR table is built automatically from the CONCEPT_RELATIONSHIP table traversing all possible concepts connected through hierarchical relationships. These are the “Is a” - “Subsumes” pairs (see Figure 5.6), and other relationships connecting hierarchies across vocabularies. The choice whether a relationship participates in the hierarchy constructor is defined for each relationship ID by the flag DEFINES_ANCESTRY in the RELATIONSHIP reference table.
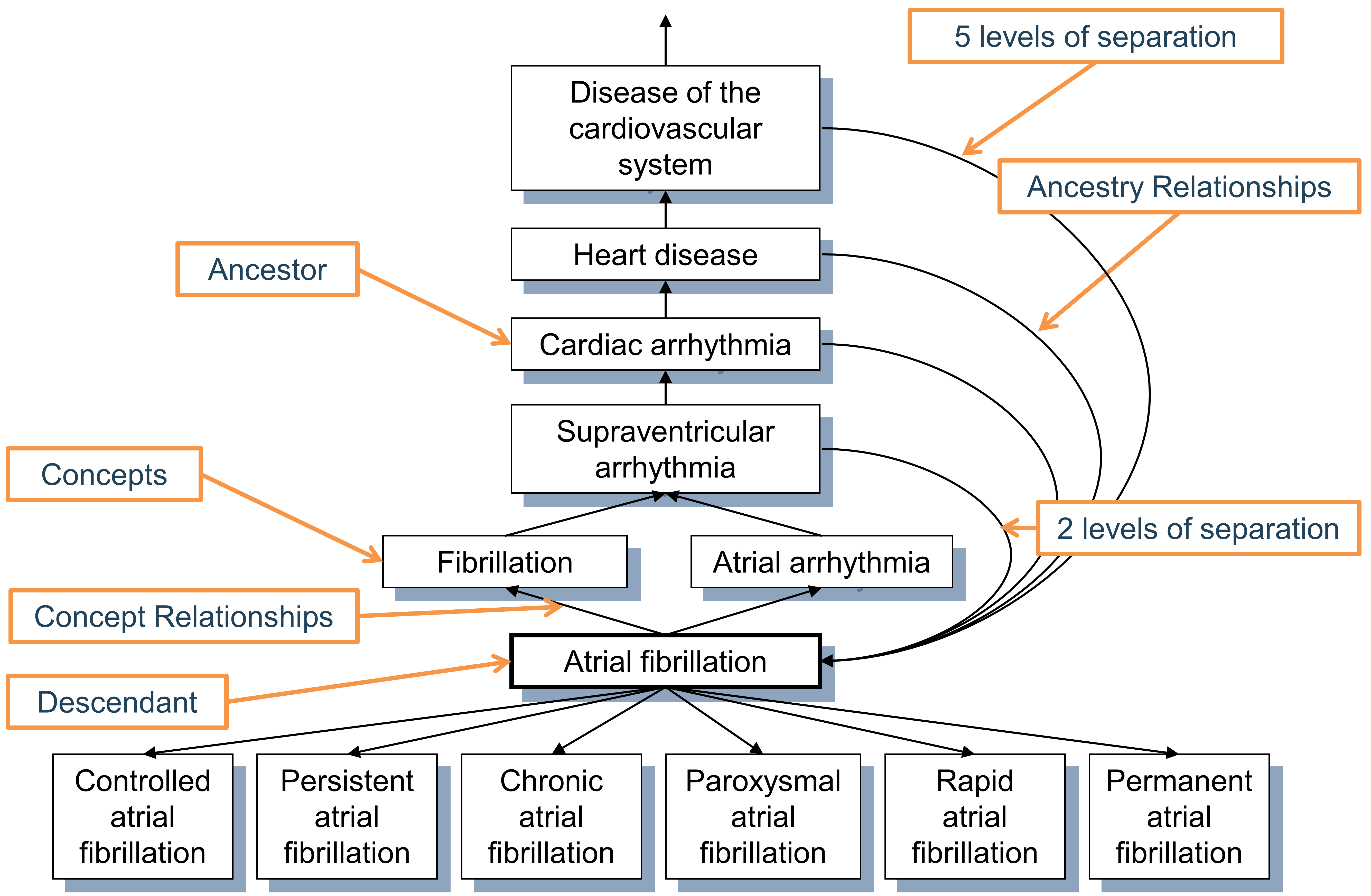
Figure 5.6: Hierarchy of the condition “Atrial fibrillation.” First degree ancestry is defined through “Is a” and “Subsumes” relationships, while all higher degree relations are inferred and stored in the CONCEPT_ANCESTOR table. Each concept is also its own descendant with both levels of separation equal to 0.
The ancestral degree, or the number of steps between ancestor and descendant, is captured in the MIN_LEVELS_OF_SEPARATION and MAX_LEVELS_OF_SEPARATION fields, defining the shortest or longest possible connection. Not all hierarchical relationships contribute equally to the levels-of-separation calculation. A step counted for the degree is determined by the IS_HIERARCHICAL flag in the RELATIONSHIP reference table for each relationship ID.
At the moment, a high-quality comprehensive hierarchy exists only for two domains: drug and condition. Procedure, measurement and observation domains are only partially covered and in the process of construction. The ancestry is particularly useful for the drug domain as it allows browsing all drugs with a given ingredient or members of drug classes irrespective of the country of origin, brand name or other attributes.
5.5 Internal Reference Tables
DOMAIN_ID, VOCABULARY_ID, CONCEPT_CLASS_ID (all in CONCEPT records) and CONCEPT_RELATIONSHIP_ID (in CONCEPT_RELATIONSHIP) are all controlled by their own vocabularies. They are defined in the four reference tables DOMAIN, VOCABULARY, CONCEPT_CLASS and RELATIONSHIP, containing the *_ID fields as primary keys, a more detailed *_NAME field and a *_CONCEPT_ID field with a reference back to the CONCEPT table, which contains a concept for each of the reference table records. The purpose of these duplicate records is to support an information model allowing for automatic navigation engines.
The VOCABULARY table also contains the VOCABULARY_REFERENCE and VOCABULARY_VERSION fields referring to the source and version of the original vocabulary. The RELATIONSHIP table has the additional fields DEFINES_ANCESTRY, IS_HIERARCHICAL and REVERSE_RELATIONSHIP_ID. The latter defines the counter relationship ID for a pair of relationships.
5.6 Special Situations
5.6.1 Gender
Gender in the OMOP CDM and Standardized Vocabularies denotes the biological sex at birth. Often, questions are posed how to define alternative genders. These use cases have to be covered through records in the OBSERVATION table, where the self-defined gender of a person is stored (if the data asset contains such information).
5.6.2 Race and Ethnicity
These follow the definitions of how the US government defines this. Ethnicity is a differentiation of Hispanic or non-Hispanic populations, which can have any race. Race is divided into the common 5 top races, which have ethnicities as their hierarchical descendants. Mixed races are not included.
5.6.3 Diagnostic Coding Schemes and OMOP Conditions
Commonly used coding schemes such as ICD-9 or ICD-10 define more or less well-defined diagnoses based on a proper diagnostic work-up. The condition domain is not identical with this semantic space, but partially overlapping. For example, conditions also contain signs and symptoms that are recorded before a diagnosis is derived, and ICD codes contain concepts that belong to other domains (e.g. procedures).
5.6.4 Procedure Coding Systems
Similarly, coding schemes like HCPCS and CPT4 are thought to be listings of medical procedures. In reality, they are more like a menu of justifications for payment for medical service. Many of these services are subsumed under the procedure domain, but many concepts fall outside this realm.
5.6.5 Devices
Device concepts have no standardized coding scheme that could be used to source Standard Concepts. In many source data, devices are not even coded or contained in an external coding scheme. For this same reason, there is currently no hierarchical system available.
5.6.6 Visits and Services
Visits concepts define the nature of healthcare encounters. In many source systems they are called Place of Service, denoting some organization or physical structure, such as a hospital. In others, they are called services. These also differ between countries, and their definition is hard to obtain. Care sites are often specializing on one of few visits (XYZ Hospital), but still should not be defined by them (even in XYZ hospital patients might encounter non-hospital visits).
5.6.7 Providers and Specialties
Any human provider is defined in the provider domain. These can be medical professionals such as doctors and nurses, but also non-medical providers like optometrists or shoemakers. Specialties are descendants of the provider “Physician.” Care Sites cannot carry a specialty, even though they are often defined by the specialty of their main staff (“Surgical department”).
5.6.8 Therapeutic Areas With Special Requirements
The Standardized Vocabularies cover all aspects of healthcare in a comprehensive fashion. However, some therapeutic areas have special needs and require special vocabularies. Examples are oncology, radiology, and genomics. Special OHDSI Working Groups develop these extensions. As a result, the OMOP Standardized Vocabularies constitutes an integrated system, where concepts from different origins and purposes all reside in the same domain-specific hierarchies.
5.6.9 Standard Concepts in the Drug Domain
Many concepts of the drug domain are sourced from RxNorm, a publicly available vocabulary produced by the US National Library of Medicine. However, drugs outside the US may or may not be covered, depending on whether or not the combination of ingredient, form and strength is marketed in the US. Drugs that are not on the US market are added by the OHDSI Vocabulary Team under a vocabulary called RxNorm Extension, which is the only large domain vocabulary produced by OHDSI.
5.6.10 Flavors of NULL
Many vocabularies contain codes about absence of information. For example, of the five gender concepts 8507 “Male,” 8532 “Female,” 8570 “Ambiguous,” 8551 “Unknown,” and 8521 “Other”, only the first two are Standard, and the other three are source concepts with no mapping. In the Standardized Vocabularies, there is no distinction made why a piece of information is not available; it might be because of an active withdrawal of information by the patient, a missing value, a value that is not defined or standardized in some way, or the absence of a mapping record in CONCEPT_RELATIONSHIP. Any such concept is not mapped, which corresponds to a default mapping to the Standard Concept with the concept ID = 0.
5.7 Summary
- All events and administrative facts are represented in the OMOP Standardized Vocabularies as concepts, concept relationships, and concept ancestor hierarchy.
- Most of these are adopted from existing coding schemes or vocabularies, while some of them are curated de-novo by the OHDSI Vocabulary Team.
- All concepts are assigned a domain, which controls where the fact represented by the concept is stored in the CDM.
- Concepts of equivalent meaning in different vocabularies are mapped to one of them, which is designated the Standard Concept. The others are source concepts.
- Mapping is done through the concept relationships “Maps to” and “Maps to value”.
- There is an additional class of concepts called classification concepts, which are non-standard, but in contrast to source concepts they participate in the hierarchy.
- Concepts have a life-cycle over time.
- Concepts within a domain are organized into hierarchies. The quality of the hierarchy differs between domains, and the completion of the hierarchy system is an ongoing task.
- You are strongly encouraged to engage with the community if you believe you found a mistake or inaccuracy.
5.8 Exercises
Prerequisites
For these first exercises you will need to look up concepts in the Standardized Vocabularies, which can be done through ATHENA28 or ATLAS.29
Exercise 5.1 What is the Standard Concept ID for “Gastrointestinal hemorrhage”?
Exercise 5.2 Which ICD-10CM codes map to the Standard Concept for “Gastrointestinal hemorrhage”? Which ICD-9CM codes map to this Standard Concept?
Exercise 5.3 What are the MedDRA preferred terms that are equivalent to the Standard Concept for “Gastrointestinal hemorrhage”?
Suggested answers can be found in Appendix E.2.