Chapter 10 Defining Cohorts
Chapter lead: Kristin Kostka
Observational health data, also referred to real world data, are the data related to patient health status and/or the delivery of health care routinely collected from a variety of sources. As such, OHDSI data stewards (OHDSI collaborators who maintain data in CDM for their sites) may capture data from a number of sources including Electronic Health Records (EHR), health insurance claims and billing activities, product and disease registries, patient-generated data including in home-use settings, and data gathered from other sources that can inform on health status, such as mobile devices. As these data were not collected for research purposes, the data may not explicitly capture the clinical data elements we are interested in.
For example, a health insurance claims database is designed to capture all care provided for some condition (e.g. angioedema) so the associated costs can appropriately be reimbursed, and information on the actual condition is captured only as part of this aim. If we wish to use such observational data for research purposes, we will often have to write some logic that uses what is captured in the data to infer what we are really interested in. In other words, we often need to create a cohort using some definition of how a clinical event manifests. Thus, if we want to identify angioedema events in an insurance claims database, we may define logic requiring an angioedema diagnose code recorded in an emergency room setting, to distinguish from claims that merely describe follow-up care for some past angioedema occurrence. Similar considerations may apply for data captured during routine healthcare interactions logged in an EHR. As data are being used for a secondary purpose, we must be cognizant of what each database was originally designed to do. Each time we design a study, we must think through the nuances of how our cohort exists in a variety of healthcare settings.
The chapter serves to explain what is meant by creating and sharing cohort definitions, the methods for developing cohorts, and how to build your own cohorts using ATLAS or SQL.
10.1 What Is a Cohort?
In OHDSI research, we define a cohort as a set of persons who satisfy one or more inclusion criteria for a duration of time. The term cohort is often interchanged with the term phenotype. Cohorts are used throughout OHDSI analytical tools and network studies as the primary building blocks for executing a research question. For instance, in a study aiming to predict the risk of angioedema in a group of people initiation ACE inhibitors, we define two cohorts: the outcome cohort (angioedema), and the target cohort (people initiating ACE inhibitors). An important aspect of cohorts in OHDSI is that they are typically defined independently from the other cohorts in the study, thus allowing re-use. For example, in our example the angioedema cohort would identify all angioedema events in the population, including those outside the target population. Our analytics tools will take the intersection of these two cohorts when needed at analysis time. The advantage of this is that the same angioedema cohort definition can now also be used in other analyses, for example an estimation study comparing ACE inhibitors to some other exposure. Cohort definitions can vary from study to study depending on the research question of interest.
A cohort is a set of persons who satisfy one or more inclusion criteria for a duration of time.
It is important to realize that this definition of a cohort used in OHDSI might differ from that used by others in the field. For example, in many peer-reviewed scientific manuscripts, a cohort is suggested to be analogous to a code set of specific clinical codes (e.g. ICD-9/ICD-10, NDC, HCPCS, etc). While code sets are an important piece in assembling a cohort, a cohort is not defined by code set. A cohort requires specific logic for how to use the code set for the criteria (e.g. is it the first occurrence of the ICD-9/ICD-10 code? any occurrence?). A well-defined cohort specifies how a patient enters a cohort and how a patient exits a cohort.
There are unique nuances to utilizing OHDSI’s definition of a cohort, including:
- One person may belong to multiple cohorts
- One person may belong to the same cohort for multiple different time periods
- One person may not belong to the same cohort multiple times during the same period of time
- A cohort may have zero or more members
There are two main approaches to constructing a cohort:
- Rule-based cohort definitions use explicit rules to describe when a patient is in the cohort. Defining these rules typically relies heavily on the domain expertise of the individual designing the cohort to use their knowledge of the therapeutic area of interest to build rules for cohort inclusion criteria.
- Probabilistic cohort definitions use a probabilistic model to compute a probability between 0 and 100% of the patient being in the cohort. This probability can be turned into a yes-no classification using some threshold, or in some study designs can be used as is. The probabilistic model is typically trained using machine learning (e.g. logistic regression) on some example data to automatically identify the relevant patient characteristics that are predictive.
The next sections will discuss these approaches in further detail.
10.2 Rule-Based Cohort Definitions
A rule-based cohort definition begins with explicitly stating one or more inclusion criteria (e.g. “people with angioedema”) in a specific duration of time (e.g. “who developed this condition within the last 6 months”).
The standard components we use to assemble these criteria are:
Domain: The CDM domain(s) where the data are stored (e.g. “Procedure Occurrence”, “Drug Exposure”) define the type of clinical information and the allowable concepts that can be represented inside that CDM table. Domains are discussed in more detail in Section 4.2.4.
Concept set: A data-agnostic expression that defines one or more Standard Concepts encompassing the clinical entity of interest. These concept sets are interoperable across different observational health data as they represent the standard terms the clinical entity maps to in the Vocabulary. Concept sets are discussed in Section 10.3.
Domain-specific attribute: Additional attributes related to the clinical entity of interest (E.g. DAYS_SUPPLY for a DRUG_EXPOSURE, or VALUE_AS_NUMBER or RANGE_HIGH for a MEASUREMENT.)
Temporal logic: The time intervals within which the relationship between an inclusion criteria and an event is evaluated (E.g. Indicated condition must occur during 365 days prior to or on exposure start.)
As you are building your cohort definition, you may find it helpful to think of Domains analogous to building blocks (see Figure 10.1) that represent cohort attributes. If you are confused about allowable content in each domain, you can always refer to the Common Data Model chapter (Chapter 4) for help.

Figure 10.1: Building Blocks of Cohort definitions.
When creating a cohort definition, you need to ask yourself the following questions:
- What initial event defines the time of cohort entry?
- What inclusion criteria are applied to the initial events?
- What defines the time of cohort exit?
Cohort entry event: The cohort entry event (initial event) defines the time when people enter the cohort, called the cohort index date. A cohort entry event can be any event recorded in the CDM such as drug exposures, conditions, procedures, measurements and visits. Initial events are defined by the CDM domain where the data are stored (e.g. PROCEDURE_OCCURRENCE, DRUG_EXPOSURE, etc), the concept sets built to identify the clinical activity (e.g. SNOMED codes for conditions, RxNorm codes for drugs) as well as any other specific attributes (e.g. age at occurrence, first diagnosis/procedure/etc, specifying start and end date, specifying visit type or criteria, days supply, etc). The set of people having an entry event is referred to as the initial event cohort.
Inclusion criteria: Inclusion criteria are applied to the initial event cohort to further restrict the set of people. Each inclusion criterion is defined by the CDM domain(s) where the data are stored, concept set(s) representing the clinical activity, domain-specific attributes (e.g. days supply, visit type, etc), and the temporal logic relative to the cohort index date. Each inclusion criterion can be evaluated to determine the impact of the criteria on the attrition of persons from the initial event cohort. The qualifying cohort is defined as all people in the initial event cohort that satisfy all inclusion criteria.
Cohort exit criteria: The cohort exit event signifies when a person no longer qualifies for cohort membership. Cohort exit can be defined in multiple ways such as the end of the observation period, a fixed time interval relative to the initial entry event, the last event in a sequence of related observations (e.g. persistent drug exposure) or through other censoring of observation period. Cohort exit strategy will impact whether a person can belong to the cohort multiple times during different time intervals.
In the OHDSI tools there is no distinction between inclusion and exclusion criteria. All criteria are formulated as inclusion criteria. For example, the exclusion criterion “Exclude people with prior hypertension” can be formulated as the inclusion criterion “Include people with 0 occurrences of prior hypertension”.
10.3 Concept Sets
A concept set is an expression representing a list of concepts that can be used as a reusable component in various analyses. It can be thought of as a standardized, computer-executable equivalent of the code lists often used in observational studies. A concept set expression consists of a list of concepts with the following attributes:
- Exclude: Exclude this concept (and any of its descendants if selected) from the concept set.
- Descendants: Consider not only this concept, but also all of its descendants.
- Mapped: Allow to search for non-standard concepts.
For example, a concept set expression could contains two concepts as depicted in Table 10.1. Here we include concept 4329847 (“Myocardial infarction”) and all of its descendants, but exclude concept 314666 (“Old myocardial infarction”) and all of its descendants.
| Concept Id | Concept Name | Excluded | Descendants | Mapped |
|---|---|---|---|---|
| 4329847 | Myocardial infarction | NO | YES | NO |
| 314666 | Old myocardial infarction | YES | YES | NO |
As shown in Figure 10.2, this will include “Myocardial infarction” and all of its descendants except “Old myocardial infarction” and its descendants. In total, this concept set expression implies nearly a hundred Standard Concepts. These Standard Concepts in turn reflect hundreds of source codes (e.g. ICD-9 and ICD-10 codes) that may appear in the various databases.
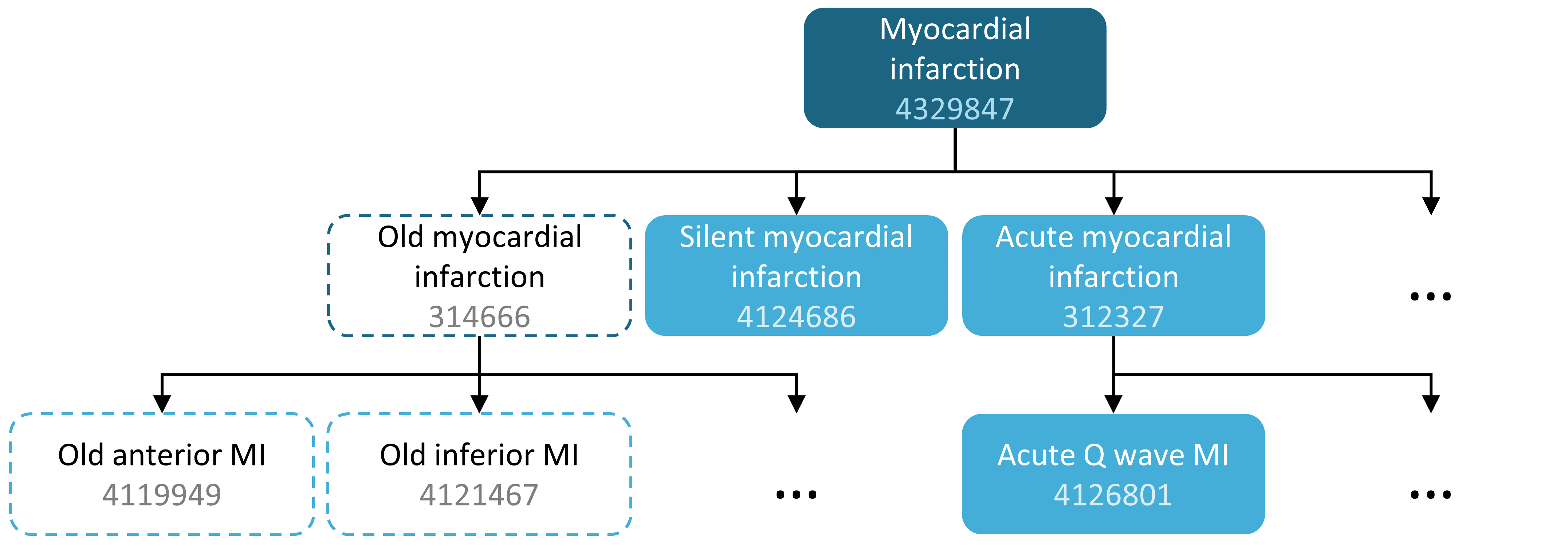
Figure 10.2: A concept set including “Myocardial infarction” (with descendants), but excluding “Old myocardial infarction” (with descendants).
10.4 Probabilistic Cohort Definitions
Rule-based cohort definitions are a popular method for assembling cohort definitions. However, assembling necessary expert consensus to create a study cohort can be prohibitively time consuming. Probabilistic cohort design is an alternative, machine-driven method to expedite the selection of cohort attributes. In this approach, supervised machine learning allows a phenotyping algorithm to learn from a set of labeled examples (cases) of what attributes contribute to cohort membership. This algorithm can then be used to better ascertain the defining characteristics of a phenotype and what trade-offs occur in overall study accuracy when choosing to modify phenotype criteria.
An example of applying this approach on data in the CDM is the APHRODITE (Automated PHenotype Routine for Observational Definition, Identification, Training and Evaluation) R-package54 . This package provides a cohort building framework that combines the ability of learning from imperfectly labeled data. (Banda et al. 2017)
10.5 Cohort Definition Validity
When you are building a cohort, you should consider which of these is more important to you: finding all the eligible patients? versus Getting only the ones you are confident about?
Your strategy to construct your cohort will depend on the clinical stringency of how your expert consensus defines the disease. This is to say, the right cohort design will depend on the question you’re trying to answer. You may opt to build a cohort definition that uses everything you can get, uses the lowest common denominator so you can share it across OHDSI sites or is a compromise of the two. It is ultimately at the researcher’s discretion what threshold of stringency is necessary to adequately study the cohort of interest.
As mentioned at the beginning of the chapter, a cohort definition is an attempt to infer something we would like to observe from the data that is recorded. This begs the question how well we succeeded in that attempt. In general, the validation of a rule-based cohort definition or probabilistic algorithm can be thought of as a test of the proposed cohort compared to some form of “gold standard” reference (e.g. manual chart review of cases). This is discussed in detail in Chapter 16 (“Clinical Validity”).
10.5.1 OHDSI Gold Standard Phenotype Library
To assist the community in the inventory and overall evaluation of existing cohort definitions and algorithms, the OHDSI Gold Standard Phenotype Library (GSPL) Workgroup was formed. The purpose of the GSPL workgroup is to develop a community-backed phenotype library from rules-based and probabilistic methods. The GSPL enable members of the OHDSI community to find, evaluate, and utilize community-validated cohort definitions for research and other activities. These “gold standard” definitions will reside in a library, the entries of which are held to specific standards of design and evaluation. For additional information related to the GSPL, consult the OHDSI workgroup page.55 Research within this workgroup includes APHRODITE (Banda et al. 2017) and the PheValuator tool (Swerdel, Hripcsak, and Ryan 2019) , discussed in the prior section, as well as work done to share the Electronic Medical Records and Genomics eMERGE Phenotype Library across the OHDSI network (Hripcsak et al. 2019). If phenotype curation is your interest, consider contributing to this workgroup.
10.6 Defining a Cohort for Hypertension
We begin to practice our cohort skills by putting together a cohort definition using a rule-based approach. In this example, we want to find patients who initiate ACE inhibitors monotherapy as first-line treatments for hypertension
With this context in mind, we are now going to build our cohort. As we go through this exercise, we will approach building our cohort similar to standard attrition chart. Figure 10.3 shows the logical framework for how we want to build this cohort.
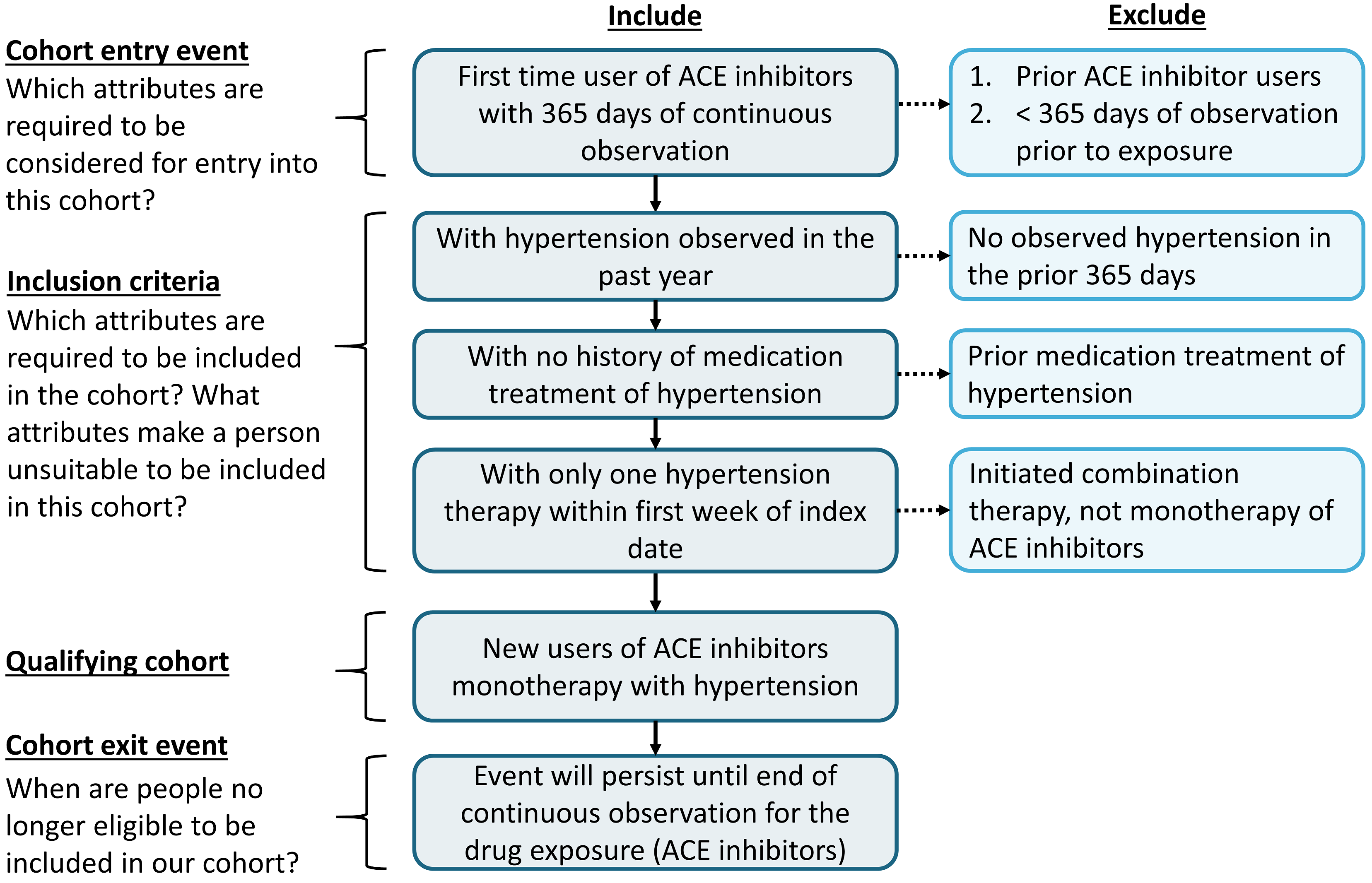
Figure 10.3: Logical Diagram of Intended Cohort
You can build a cohort in the user interface of ATLAS or you can write a query directly against your CDM. We will briefly discuss both in this chapter.
10.7 Implementing a Cohort Using ATLAS
To begin in ATLAS, click on the  module. When the module loads, click on “New cohort”. The next screen you will see will be an empty cohort definition. Figure 10.4 shows what you will see on your screen.
module. When the module loads, click on “New cohort”. The next screen you will see will be an empty cohort definition. Figure 10.4 shows what you will see on your screen.
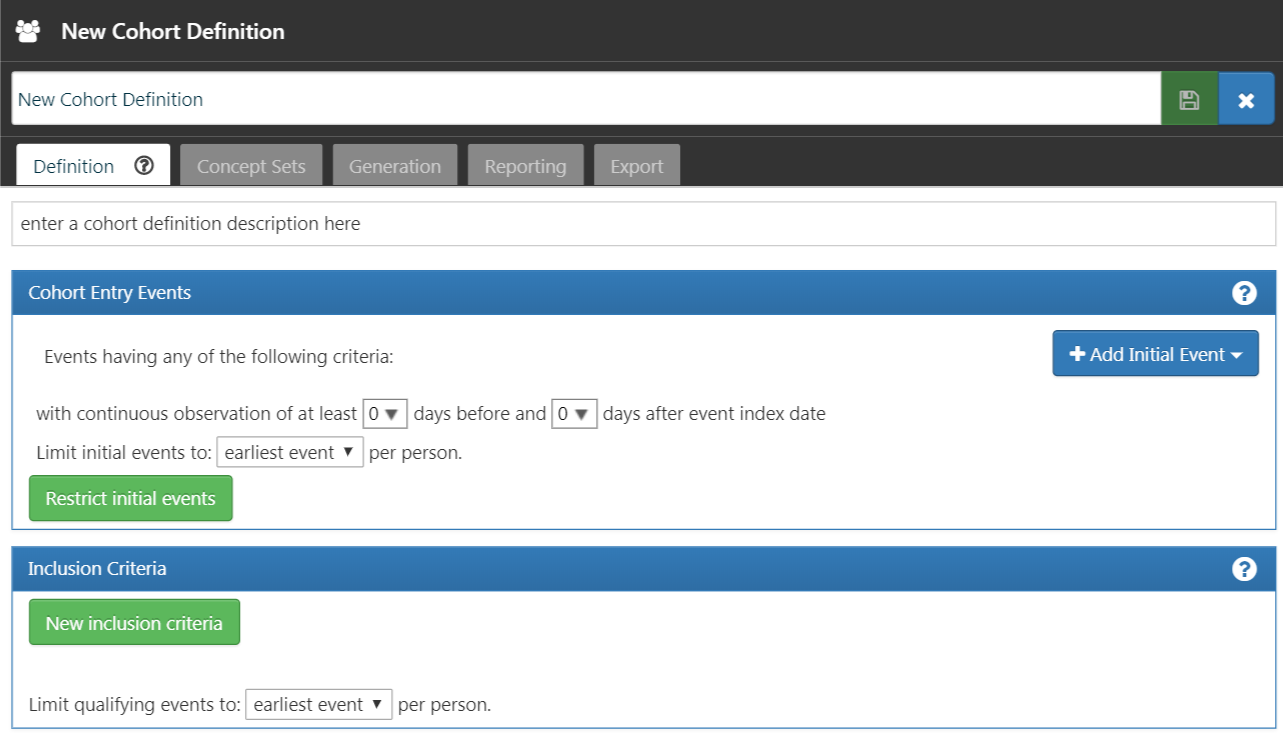
Figure 10.4: New Cohort Definition
Before you do anything else, you are encouraged to change the name of the cohort from “New Cohort Definition” to your own unique name for this cohort. You may opt for a name like “New users of ACE inhibitors as first-line monotherapy for hypertension”.
Once you have chosen a name, you can save the cohort by clicking  .
.
10.7.1 Initial Event Criteria
Now we can proceed with defining the initial cohort event. You will click “Add initial event”. You now have to pick which domain you are building a criteria around. You may ask yourself, “how do I know which domain is the initial cohort event?” Let’s figure that out.
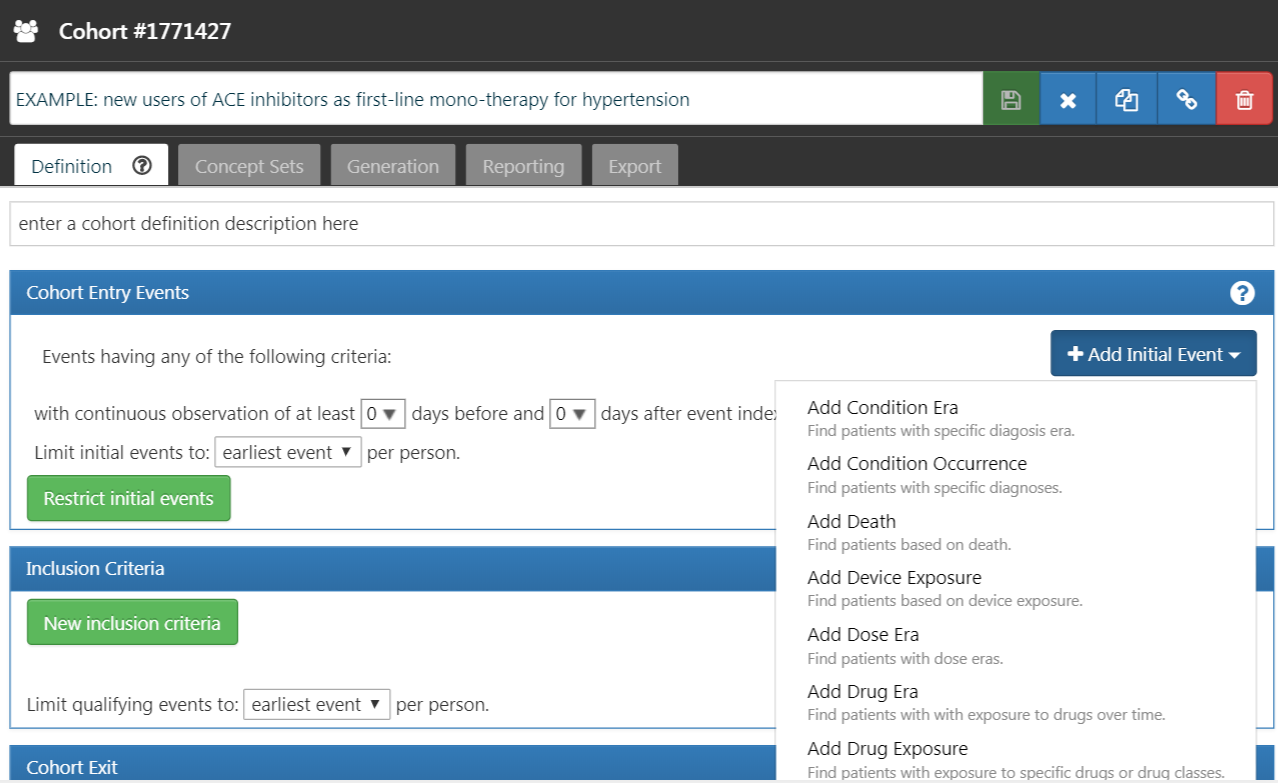
Figure 10.5: Adding an Initial Event
As we see in Figure 10.5, ATLAS provides descriptions below each criteria to help you. If we were building a CONDITION_OCCURRENCE based criteria, our question would be looking for patients with a specific diagnosis. If we were building a DRUG_EXPOSURE based criteria, our question would be looking for patients with a specific drug or drug class. Since we want to find patients who initiate ACE inhibitors monotherapy as first-line treatments for hypertension, we want to choose a DRUG_EXPOSURE criteria. You may say, “but we also care about hypertension as a diagnosis”. You are correct. Hypertension is another criterion we will build. However, the cohort start date is defined by the initiation of the ACE inhibitor treatment, which is therefore the initial event. The diagnosis of hypertension is what we call an additional qualifying criteria. We will return to this once we build this criteria. We will click “Add Drug Exposure”.
The screen will update with your selected criteria but you are not done yet. As we see in Figure 10.6, ATLAS does not know what drug we are looking for. We need to tell ATLAS which concept set is associated to ACE inhibitors.
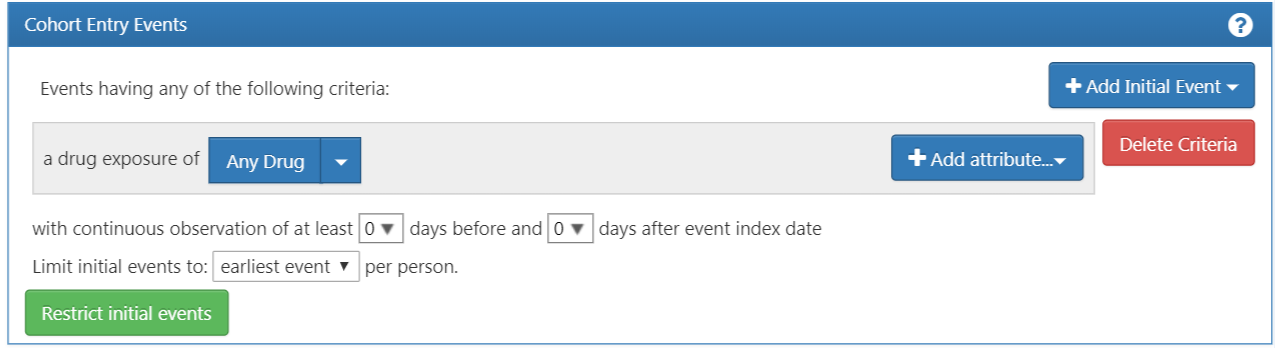
Figure 10.6: Defining a Drug Exposure
10.7.2 Defining the Concept Set
You will need to click  to open the dialogue box that will allow you to retrieve a concept set to define ACE Inhibitors.
to open the dialogue box that will allow you to retrieve a concept set to define ACE Inhibitors.
Scenario 1: You Have Not Built a Concept Set
If you have not assembled your concept sets to apply to your criteria, you will need to do so before you move forward. You may build a concept set within the cohort definition by navigating to the “Concept set” tab and clicking “New Concept Set”. You will need to rename the concept set from “Unnamed Concept Set” to a name of your choosing. From there you can use the  module to look for clinical concepts that represent ACE inhibitors (Figure 10.7).
module to look for clinical concepts that represent ACE inhibitors (Figure 10.7).
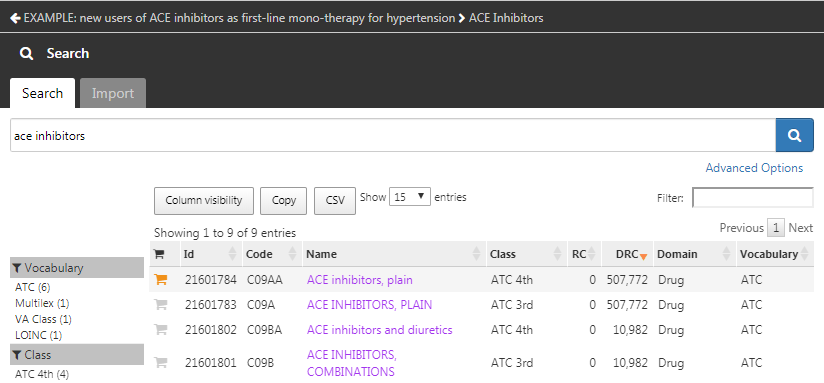
Figure 10.7: Searching the Vocabulary - ACE Inhibitors
When you have found terms that you would like to use to define this drug exposure, you can select the concept by clicking on  . You can return to your cohort definition by using the left arrow in the top left of Figure 10.7. You can refer back to Chapter 5 (Standardized Vocabularies) on how to navigate the vocabularies to find clinical concepts of interest.
. You can return to your cohort definition by using the left arrow in the top left of Figure 10.7. You can refer back to Chapter 5 (Standardized Vocabularies) on how to navigate the vocabularies to find clinical concepts of interest.
Figure 10.8 shows our concept set expression. We selected all ACE inhibitor ingredients we are interested in, and include all their descendants, thus including all drugs that contain any of these ingredients. We can click on “Included concepts” to see all 21,536 concepts implied by this expression, or we can click on “Included Source Codes” to explore all source codes in the various coding systems that are implied.
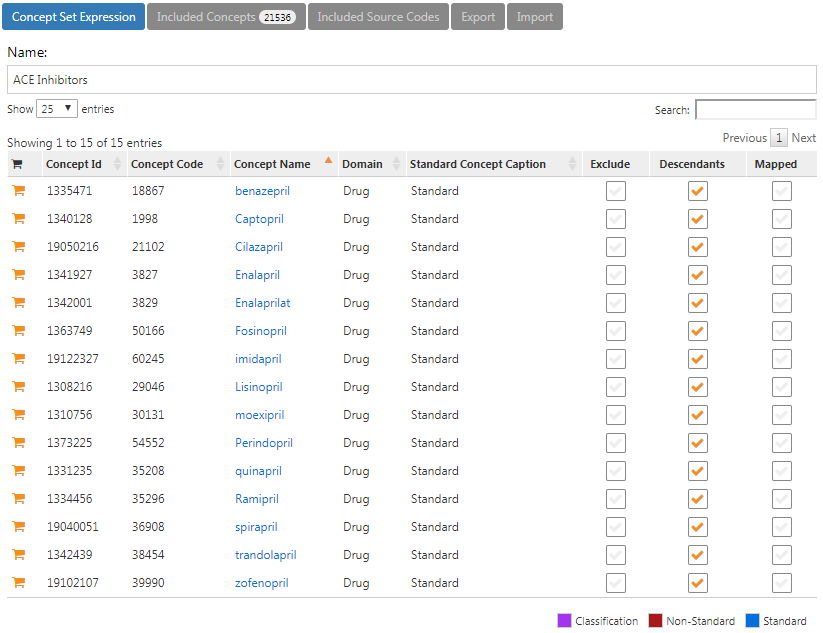
Figure 10.8: A concept set containing ACE inhibitor drugs.
Scenario 2: You Have Already Built a Concept Set
If you have already created a concept set and saved it in ATLAS, you can click to “Import Concept Set”. A dialogue box will open that will be prompt you to find your concept in the concept set repository of your ATLAS as shown in Figure 10.9. In the example figure the user is retrieving concept sets stored in ATLAS. The user typed in the name given to this concept set “ace inhibitors” in the right hand search. This shortened the concept set list to only concepts with matching names. From there, the user can click on the row of the concept set to select it. (Note: the dialogue box will disappear once you have selected a concept set.) You will know this action is successful when the Any Drug box is updated with the name of the concept set you selected.
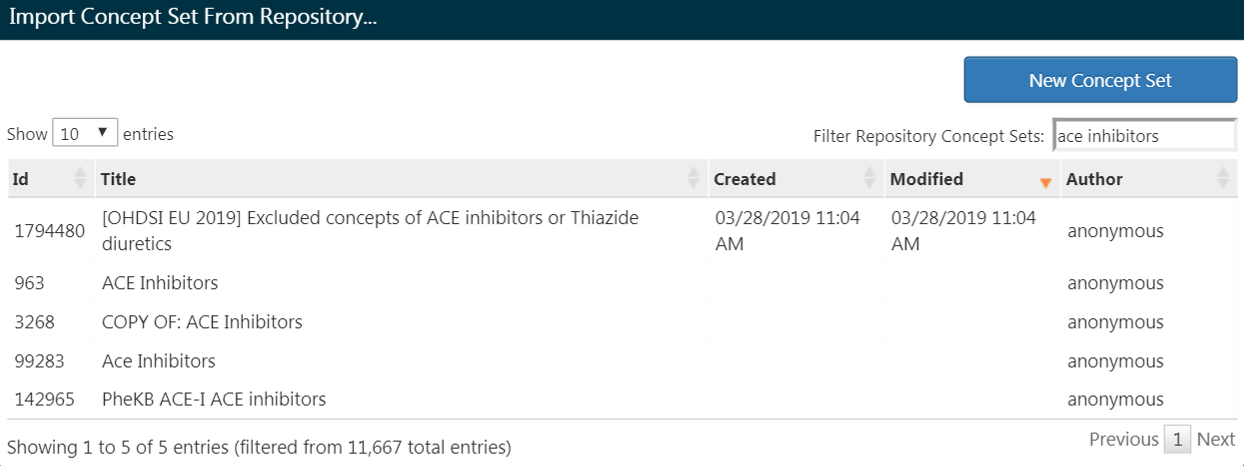
Figure 10.9: Importing a Concept Set from ATLAS Repository
10.7.3 Additional Initial Event Criteria
Now that you’ve attached a concept set, you are not done yet. Your question is looking for new users or the first time in someone’s history they are exposed to ACE inhibitors. This translates to the first exposure of ACE inhibitors in the patient’s record. To specify this, you need to click “+Add attribute”. You will want to select the “Add first exposure criteria”. Notice, you could specify other attributes of a criteria you build. You could specify an attribute of age at occurrence, the date of occurrence, gender or other attributes related to the drug. Criteria available for selection will look different for each domain.
From there, the window will automatically close. Once selected, this additional attribute will show up in the same box as the initial criteria (see Figure 10.10).
The current design of ATLAS may confuse some. Despite its appearance, the  is not intended to mean “No”. It is an actionable feature to allow the user to delete the criteria. If you click , this criteria will go away. Thus, you need to leave the criteria with the to keep the criteria active.
is not intended to mean “No”. It is an actionable feature to allow the user to delete the criteria. If you click , this criteria will go away. Thus, you need to leave the criteria with the to keep the criteria active.
Now you have built an initial qualifying event. To ensure you are capturing the first observed drug exposure, you will want to add a look-back window to know that you are looking at enough of the patient’s history to know what comes first. It is possible that a patient with a short observation period may have received an exposure elsewhere that we do not see. We cannot control this but we can mandate a minimum amount of time the patient must be in the data prior to the index date You can do this by adjusting the continuous observation drop downs. You could also click the box and type in a value to these windows. We will require 365 days of continuous observation prior to the initial event. You will update your observation period to: with continuous observation of 365 days before, as shown in Figure 10.10. This look-back window is the discretion of your study team. You may choose differently in other cohorts. This creates, as best as we are able, a minimum period of time we see the patient to ensure we are capturing the first record. This criteria is about prior history and does not involve time after the index event. Therefore, we require 0 days after the index event. Our qualifying event is the first-ever use of ACE inhibitors. Thus, we limit initial events to the “earliest event” per person.
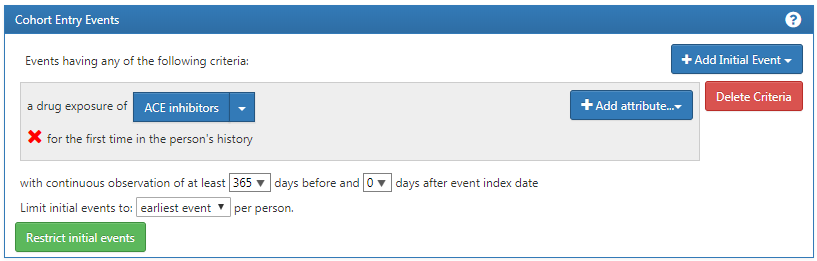
Figure 10.10: Setting the required continuous observation before the index date.
To further explain how this logic comes together, you can think about assembling patient timelines.
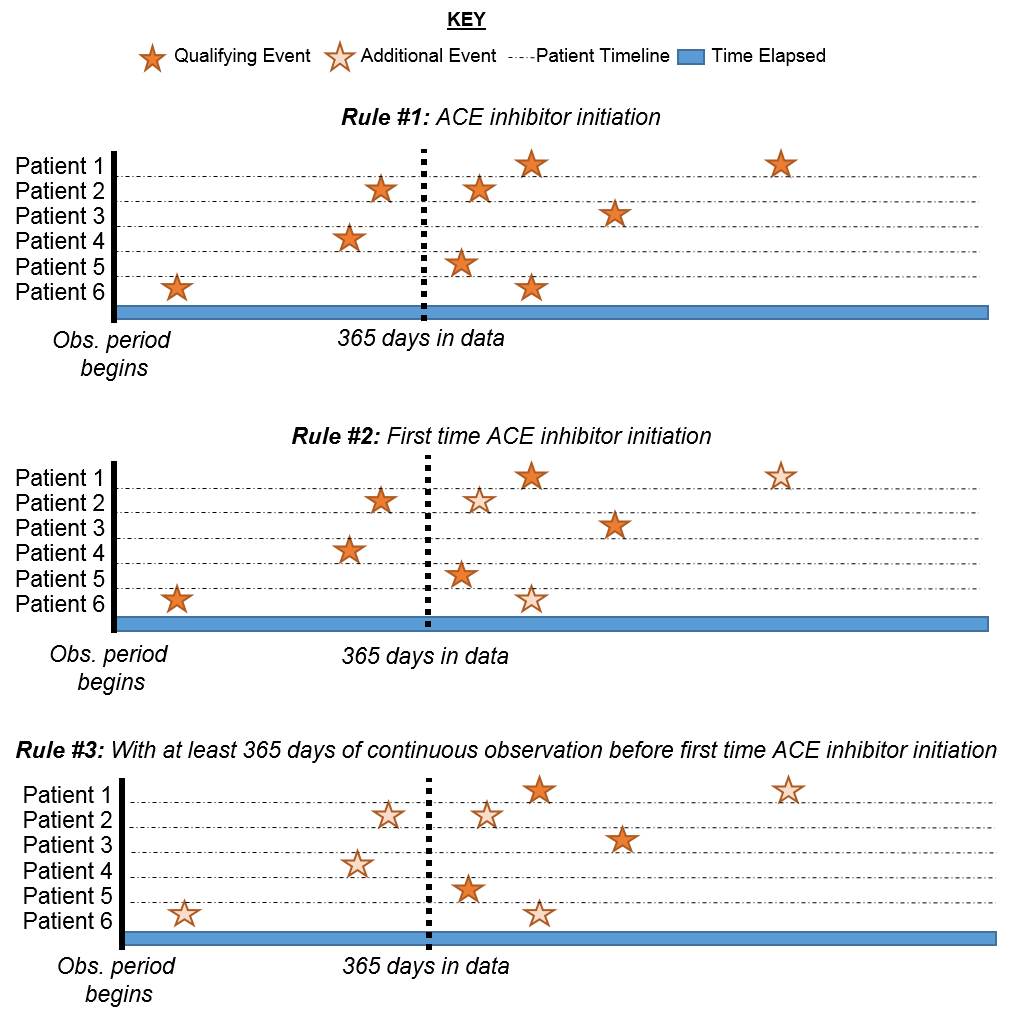
Figure 10.11: Explaining patient eligibility by criteria applied
In Figure 10.11, each line represents a single patient that may be eligible to join the cohort. The filled in stars represent a time the patient fulfills the specified criteria. As additional criteria is applied, you may see some stars are a lighter shade. This means that these patients have other records that satisfy the criteria but there is another record that proceeds that. By the time we get to the last criteria, we are looking at the cumulative view of patients who have ACE inhibitors for the first time and have 365 days prior to the first-time occurrence. Logically, limiting to the initial event is redundant though it is helpful to maintain our explicit logic in every selection we make. When you are building your own cohorts, you may opt to engage the Researchers section of the OHDSI Forum to get a second opinion on how to construct your cohort logic.
10.7.4 Inclusion Criteria
Once we have specified a cohort entry event, you could proceed to one of two places to add your additional qualifying events: “Restrict initial events” and “New inclusion criteria”. The fundamental difference between these two options is what interim information you want ATLAS to serve back to you. If you add additional qualifying criteria into the Cohort Entry Event box by selecting “Restrict initial events”, when you choose to generate a count in ATLAS, you will only get back the number of people who meet ALL of these criteria. If you opt to add criteria into the “New inclusion criteria”, you will get an attrition chart to show you how many patients are lost by applying additional inclusion criteria. It is highly encouraged to utilize the Inclusion Criteria section so you can understand the impact of each rule on the overall success of the cohort definition. You may find a certain inclusion criteria severely limits the number of people who end up in the cohort. You may choose to relax this criterion to get a larger cohort. This will ultimately be at the discretion of the expert consensus assembling this cohort.
You will now want to click “New inclusion criteria” to add a subsequent piece of logic about membership to this cohort. The functionality in this section is identical to the way we discussed building cohort criteria above. You may specific the criteria and add specific attributes. Our first additional criteria is to subset the cohort to only patients: With at least 1 occurrence of hypertension disorder between 365 and 0 days after index date (first initiation of an ACE inhibitor). You will click “New inclusion criteria” to add a new criteria. You should name your criteria and, if desired, put a little description of what you are looking for. This is for your own purposes to recall what you build – it will not impact the integrity of the cohort you are defining.
Once you have annotated this new criteria, you will click on the “+Add criteria to group” button to build your actual criteria for this rule. This button functions similar to the “Add Initial Event” except we are no longer specifying an initial event. We could add multiple criteria to this – which is why it specifies “add criteria to group”. An example would be if you have multiple ways of finding a disease (e.g. logic for a CONDITION_OCCURRENCE, logic using a DRUG_EXPOSURE as a proxy for this condition, logic for using a MEASUREMENT as a proxy for this condition). These would be separate domains and require different criteria but can be grouped into one criteria looking for this condition. In this case, we want to find a diagnosis of hypertension so we “Add condition occurrence”. We will follow similar steps as we did with the initial event by attaching a concept set to this record. We also want to specify the event starts between 365 days before and 0 days after the index date (the occurrence of the first ACE inhibitor use). Now check your logic against Figure 10.12.
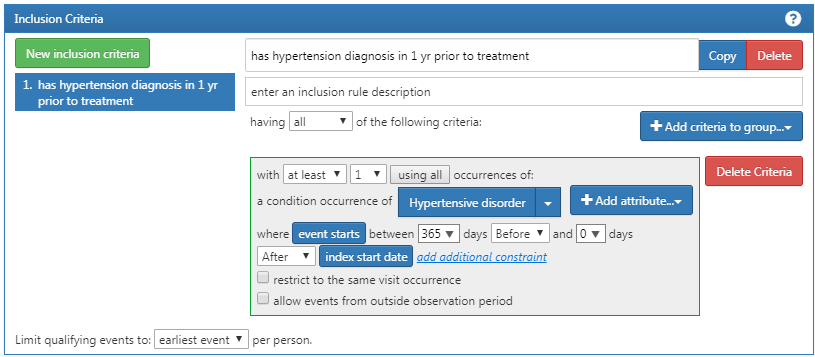
Figure 10.12: Additional Inclusion criteria 1
You will then want to add another criterion to look for patients: with exactly 0 occurrences of hypertension drugs ALL days before and 1 day before index start date (no exposure to HT drugs before an ACE inhibitor). This process begins as we did before by clicking the “New inclusion criteria” button, adding your annotations to this criterion and then clicking “+Add criteria to group”. This is a DRUG_EXPOSURE so you will click “Add Drug Exposure”, attach a concept set for hypertensive drugs, and will specify ALL days before and 0 days after (or “1 days before” is equivalent as seen in figure) the index date. Make sure to confirm you have exactly 0 occurrence selected. Now check your logic against Figure 10.13.
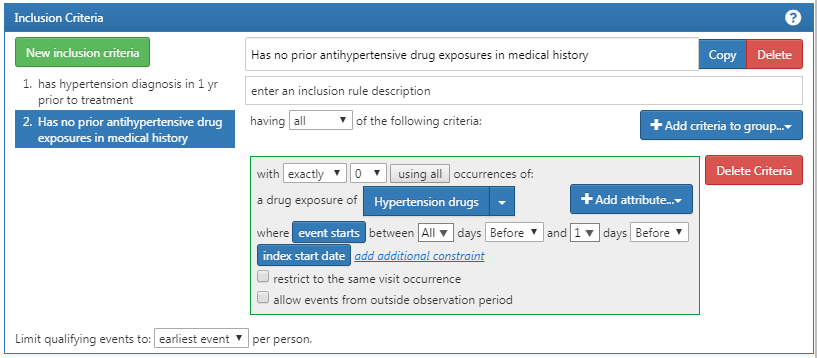
Figure 10.13: Additional Inclusion Criteria 2
You may be confused why “having no occurrences” is coded as “exactly 0 occurrences.” This is a nuance of how ATLAS consumes knowledge. ATLAS only consumes inclusion criteria. You must use logical operators to indicate when you want the absence of a specific attribute such as: “Exactly 0.” Over time you will become more familiar with the logical operators available in ATLAS criteria.
Lastly, you will want to add your another criterion to look for patients: with exactly 1 occurrence of hypertension drugs between 0 days before and 7 days after index start date AND can only start one HT drug (an ACE inhibitor) . This process begins as we did before by clicking the “New inclusion criteria” button, adding your annotations to this criterion and then clicking “+Add criteria to group”. This is a DRUG_ERA so you will click “Add Drug Era”, attach a concept set for hypertensive drugs, and will specify 0 days before and 7 days after the index date. Now check your logic against Figure 10.14.
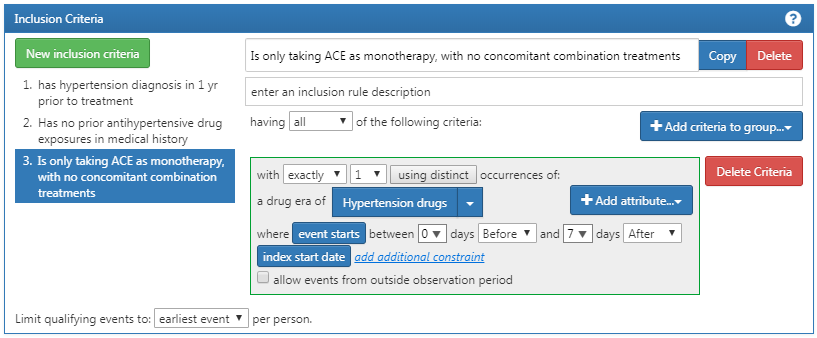
Figure 10.14: Additional Inclusion Criteria 3
10.7.5 Cohort Exit Criteria
You have now added all of your qualifying inclusion criteria. You must now specify your cohort exit criteria. You will ask yourself, “when are people no longer eligible to be included in this cohort?” In this cohort, we are following new-users of a drug exposure. We want to look at continuous observation period as it relates to the drug exposure. As such, the exit criterion is specified to follow for the entirety of the continuous drug exposure. If there is a subsequent break in the drug exposure, the patient will exit the cohort at this time. We do this as we cannot determine what happened to the person during the break in the drug exposure. We can also set a criteria on the persistence window to specify an allowable gap between drug exposures. In this case, our experts leading this study concluded that a maximum of 30 days between exposure records is allowable when inferring the era of persistence exposure.
Why are gaps allowed? In some data sets, we see only portions of clinical interactions. Drug exposures, in particular, may represent a dispense of a prescription that can cover a certain period of time. Thus, we allow a certain amount of time between drug exposures as we know the patient may logically still have access to the initial drug exposure because the unit of dispense exceeded one day.
We can configure this by selecting the Event will persist “end of a continuous drug exposure”. We then will add our persistence window to “allow for a maximum of 30 days” and append the concept set for “ACE inhibitors”. Now check your logic against Figure 10.15.
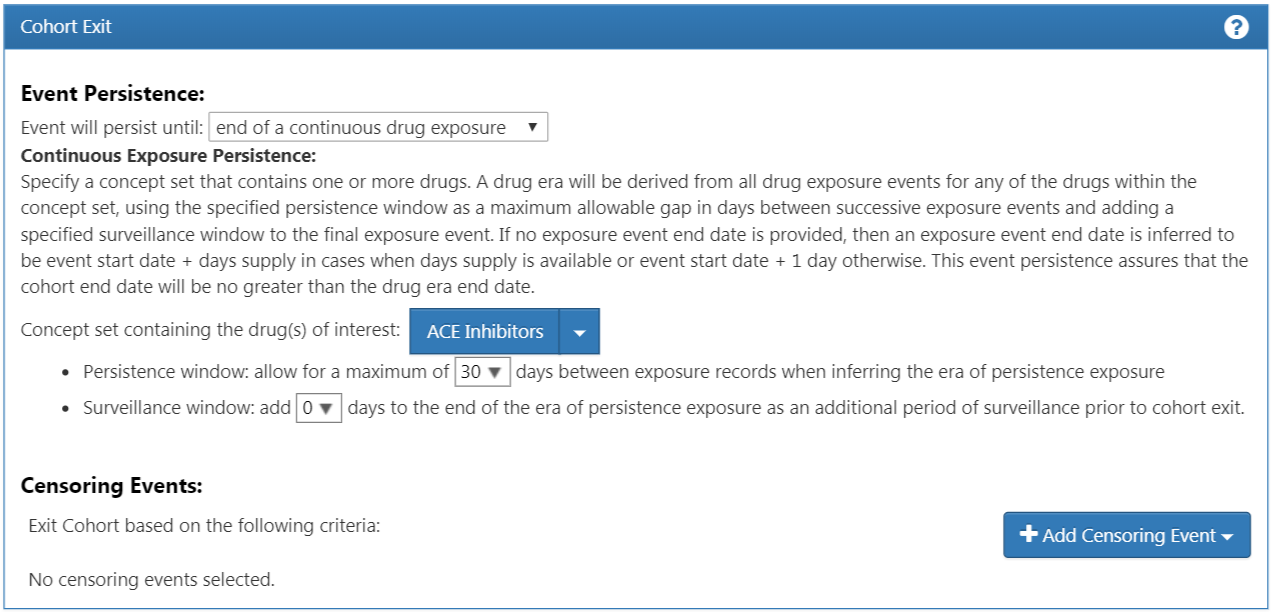
Figure 10.15: Cohort Exit Criteria
In the case of this cohort, there are no other censoring events. However, you may build other cohorts where you need to specify this criteria. You would proceed similarly to the way we have added other attributes to this cohort definition. You have now successfully finished creating your cohort. Make sure to hit the button. Congratulations! Building a cohort is the most important building block of answering a question in the OHDSI tools. You can now use the “Export” tab to share your cohort definition to other collaborators in the form of SQL code or JSON files to load into ATLAS.
10.8 Implementing the Cohort Using SQL
Here we describe how to create the same cohort, but using SQL and R. As discussed in Chapter 9, OHDSI provides two R packages, called SqlRender and DatabaseConnector, which together allow writing SQL code that can be automatically translated and executed against a wide variety of database platforms.
For clarity, we will split the SQL into several chunks, each chunk generating a temp table that is used in the next. This is likely not the most computationally efficient way to do it, but it is easier to read than a single very long statement.
10.8.1 Connecting to the Database
We first need to tell R how to connect to the server. We use the DatabaseConnector package, which provides a function called createConnectionDetails. Type ?createConnectionDetails for the specific settings required for the various database management systems (DBMS). For example, one might connect to a PostgreSQL database using this code:
library(CohortMethod)
connDetails <- createConnectionDetails(dbms = "postgresql",
server = "localhost/ohdsi",
user = "joe",
password = "supersecret")
cdmDbSchema <- "my_cdm_data"
cohortDbSchema <- "scratch"
cohortTable <- "my_cohorts"The last three lines define the cdmDbSchema, cohortDbSchema, and cohortTable variables. We will use these later to tell R where the data in CDM format live, and where the cohorts of interest have to be created. Note that for Microsoft SQL Server, database schemas need to specify both the database and the schema, so for example cdmDbSchema <- "my_cdm_data.dbo".
10.8.2 Specifying the Concepts
For readability we will define the concept IDs we need in R, and pass them to the SQL:
aceI <- c(1308216, 1310756, 1331235, 1334456, 1335471, 1340128, 1341927,
1342439, 1363749, 1373225)
hypertension <- 316866
allHtDrugs <- c(904542, 907013, 932745, 942350, 956874, 970250, 974166,
978555, 991382, 1305447, 1307046, 1307863, 1308216,
1308842, 1309068, 1309799, 1310756, 1313200, 1314002,
1314577, 1317640, 1317967, 1318137, 1318853, 1319880,
1319998, 1322081, 1326012, 1327978, 1328165, 1331235,
1332418, 1334456, 1335471, 1338005, 1340128, 1341238,
1341927, 1342439, 1344965, 1345858, 1346686, 1346823,
1347384, 1350489, 1351557, 1353766, 1353776, 1363053,
1363749, 1367500, 1373225, 1373928, 1386957, 1395058,
1398937, 40226742, 40235485)10.8.3 Finding First Use
We will first find first use of ACE inhibitors for each patient:
conn <- connect(connectionDetails)
sql <- "SELECT person_id AS subject_id,
MIN(drug_exposure_start_date) AS cohort_start_date
INTO #first_use
FROM @cdm_db_schema.drug_exposure
INNER JOIN @cdm_db_schema.concept_ancestor
ON descendant_concept_id = drug_concept_id
WHERE ancestor_concept_id IN (@ace_i)
GROUP BY person_id;"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
ace_i = aceI)Note that we join the DRUG_EXPOSURE table to the CONCEPT_ANCESTOR table to find all drugs that contain an ACE inhibitor.
10.8.4 Require 365 Days of Prior Observation
Next, we require 365 of continuous prior observation by joining to the OBSERVATION_PERIOD table:
sql <- "SELECT subject_id,
cohort_start_date
INTO #has_prior_obs
FROM #first_use
INNER JOIN @cdm_db_schema.observation_period
ON subject_id = person_id
AND observation_period_start_date <= cohort_start_date
AND observation_period_end_date >= cohort_start_date
WHERE DATEADD(DAY, 365, observation_period_start_date) < cohort_start_date;"
renderTranslateExecuteSql(conn, sql, cdm_db_schema = cdmDbSchema)10.8.5 Require Prior Hypertension
We require a hypertension diagnosis in the 365 days prior:
sql <- "SELECT DISTINCT subject_id,
cohort_start_date
INTO #has_ht
FROM #has_prior_obs
INNER JOIN @cdm_db_schema.condition_occurrence
ON subject_id = person_id
AND condition_start_date <= cohort_start_date
AND condition_start_date >= DATEADD(DAY, -365, cohort_start_date)
INNER JOIN @cdm_db_schema.concept_ancestor
ON descendant_concept_id = condition_concept_id
WHERE ancestor_concept_id = @hypertension;"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
hypertension = hypertension)Note that we SELECT DISTINCT, because else if a person has multiple hypertension diagnoses in their past, we would create duplicate cohort entries.
10.8.6 No Prior Treatment
We require no prior exposure to any hypertension treatment:
sql <- "SELECT subject_id,
cohort_start_date
INTO #no_prior_ht_drugs
FROM #has_ht
LEFT JOIN (
SELECT *
FROM @cdm_db_schema.drug_exposure
INNER JOIN @cdm_db_schema.concept_ancestor
ON descendant_concept_id = drug_concept_id
WHERE ancestor_concept_id IN (@all_ht_drugs)
) ht_drugs
ON subject_id = person_id
AND drug_exposure_start_date < cohort_start_date
WHERE person_id IS NULL;"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
all_ht_drugs = allHtDrugs)Note that we use a left join, and only allow rows where the person_id, which comes from the DRUG_EXPOSURE table is NULL, meaning no matching record was found.
10.8.7 Monotherapy
We require there to be only one exposure to hypertension treatment in the first seven days of the cohort entry:
sql <- "SELECT subject_id,
cohort_start_date
INTO #monotherapy
FROM #no_prior_ht_drugs
INNER JOIN @cdm_db_schema.drug_exposure
ON subject_id = person_id
AND drug_exposure_start_date >= cohort_start_date
AND drug_exposure_start_date <= DATEADD(DAY, 7, cohort_start_date)
INNER JOIN @cdm_db_schema.concept_ancestor
ON descendant_concept_id = drug_concept_id
WHERE ancestor_concept_id IN (@all_ht_drugs)
GROUP BY subject_id,
cohort_start_date
HAVING COUNT(*) = 1;"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
all_ht_drugs = allHtDrugs)10.8.8 Cohort Exit
We have now fully specified our cohort except the cohort end date. The cohort is defined to end when the exposure stops, allowing for a maximum 30-day gap between subsequent exposures. This means we need to not only consider the first drug exposure, but also subsequent drug exposures to ACE inhibitors. The SQL for combining subsequent exposures into eras can be highly complex. Luckily, standard code has been defined that can efficiently create eras. (This code was written by Chris Knoll, and is often referred to within OHDSI as ‘the magic’). We first create a temp table containing all exposures we wish to merge:
sql <- "
SELECT person_id,
CAST(1 AS INT) AS concept_id,
drug_exposure_start_date AS exposure_start_date,
drug_exposure_end_date AS exposure_end_date
INTO #exposure
FROM @cdm_db_schema.drug_exposure
INNER JOIN @cdm_db_schema.concept_ancestor
ON descendant_concept_id = drug_concept_id
WHERE ancestor_concept_id IN (@ace_i);"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
ace_i = aceI)We then run the standard code for merging sequential exposures:
sql <- "
SELECT ends.person_id AS subject_id,
ends.concept_id AS cohort_definition_id,
MIN(exposure_start_date) AS cohort_start_date,
ends.era_end_date AS cohort_end_date
INTO #exposure_era
FROM (
SELECT exposure.person_id,
exposure.concept_id,
exposure.exposure_start_date,
MIN(events.end_date) AS era_end_date
FROM #exposure exposure
JOIN (
--cteEndDates
SELECT person_id,
concept_id,
DATEADD(DAY, - 1 * @max_gap, event_date) AS end_date
FROM (
SELECT person_id,
concept_id,
event_date,
event_type,
MAX(start_ordinal) OVER (
PARTITION BY person_id ,concept_id ORDER BY event_date,
event_type ROWS UNBOUNDED PRECEDING
) AS start_ordinal,
ROW_NUMBER() OVER (
PARTITION BY person_id, concept_id ORDER BY event_date,
event_type
) AS overall_ord
FROM (
-- select the start dates, assigning a row number to each
SELECT person_id,
concept_id,
exposure_start_date AS event_date,
0 AS event_type,
ROW_NUMBER() OVER (
PARTITION BY person_id, concept_id ORDER BY exposure_start_date
) AS start_ordinal
FROM #exposure exposure
UNION ALL
-- add the end dates with NULL as the row number, padding the end dates by
-- @max_gap to allow a grace period for overlapping ranges.
SELECT person_id,
concept_id,
DATEADD(day, @max_gap, exposure_end_date),
1 AS event_type,
NULL
FROM #exposure exposure
) rawdata
) events
WHERE 2 * events.start_ordinal - events.overall_ord = 0
) events
ON exposure.person_id = events.person_id
AND exposure.concept_id = events.concept_id
AND events.end_date >= exposure.exposure_end_date
GROUP BY exposure.person_id,
exposure.concept_id,
exposure.exposure_start_date
) ends
GROUP BY ends.person_id,
concept_id,
ends.era_end_date;"
renderTranslateExecuteSql(conn,
sql,
cdm_db_schema = cdmDbSchema,
max_gap = 30)This code merges all subsequent exposures, allowing for a gap between exposures as defined by the max_gap argument. The resulting drug exposure eras are written to a temp table called #exposure_era.
Next, we simply join these ACE inhibitor exposure eras to our original cohort to use the era end dates as our cohort end dates:
sql <- "SELECT ee.subject_id,
CAST(1 AS INT) AS cohort_definition_id,
ee.cohort_start_date,
ee.cohort_end_date
INTO @cohort_db_schema.@cohort_table
FROM #monotherapy mt
INNER JOIN #exposure_era ee
ON mt.subject_id = ee.subject_id
AND mt.cohort_start_date = ee.cohort_start_date;"
renderTranslateExecuteSql(conn,
sql,
cohort_db_schema = cohortDbSchema,
cohort_table = cohortTable)Here we store the final cohort in schema and table we defined earlier. We assign it a cohort definition ID of 1, to distinguish it from other cohorts we may wish to store in the same table.
10.8.9 Cleanup
Finally, it is always recommend to clean up any temp tables that were created, and disconnect from the database server:
sql <- "TRUNCATE TABLE #first_use;
DROP TABLE #first_use;
TRUNCATE TABLE #has_prior_obs;
DROP TABLE #has_prior_obs;
TRUNCATE TABLE #has_ht;
DROP TABLE #has_ht;
TRUNCATE TABLE #no_prior_ht_drugs;
DROP TABLE #no_prior_ht_drugs;
TRUNCATE TABLE #monotherapy;
DROP TABLE #monotherapy;
TRUNCATE TABLE #exposure;
DROP TABLE #exposure;
TRUNCATE TABLE #exposure_era;
DROP TABLE #exposure_era;"
renderTranslateExecuteSql(conn, sql)
disconnect(conn)10.9 Summary
A cohort is set of persons who satisfy one or more inclusion criteria for a duration of time.
A cohort definition is the description of logic used for identifying a particular cohort.
Cohorts are used (and re-used) throughout the OHDSI analytics tools to define for example the exposures and outcomes of interest.
There are two major approaches to building a cohort: rule-based and probabilistic.
Rule-based cohort definitions can be created in ATLAS, or using SQL
10.10 Exercises
Prerequisites
For the first exercise, access to an ATLAS instance is required. You can use the instance at http://atlas-demo.ohdsi.org, or any other instance you have access to.
Exercise 10.1 Use ATLAS to create a cohort definition following these criteria:
- New users of diclofenac
- Ages 16 or older
- With at least 365 days of continuous observation prior to exposure
- Without prior exposure to any NSAID (Non-Steroidal Anti-Inflammatory Drug)
- Without prior diagnosis of cancer
- With cohort exit defined as discontinuation of exposure (allowing for a 30-day gap)
Prerequisites
For the second exercise we assume R, R-Studio and Java have been installed as described in Section 8.4.5. Also required are the SqlRender, DatabaseConnector, and Eunomia packages, which can be installed using:
install.packages(c("SqlRender", "DatabaseConnector", "remotes"))
remotes::install_github("ohdsi/Eunomia", ref = "v1.0.0")The Eunomia package provides a simulated dataset in the CDM that will run inside your local R session. The connection details can be obtained using:
The CDM database schema is “main”.
Exercise 10.2 Use SQL and R to create a cohort for acute myocardial infarction (AMI) in the existing COHORT table, following these criteria:
- An occurrence of a myocardial infarction diagnose (concept 4329847 “Myocardial infarction” and all of its descendants, excluding concept 314666 “Old myocardial infarction” and any of its descendants).
- During an inpatient or ER visit (concepts 9201, 9203, and 262 for “Inpatient visit”, “Emergency Room Visit”, and “Emergency Room and Inpatient Visit”, respectively).
Suggested answers can be found in Appendix E.6.
References
Banda, J. M., Y. Halpern, D. Sontag, and N. H. Shah. 2017. “Electronic phenotyping with APHRODITE and the Observational Health Sciences and Informatics (OHDSI) data network.” AMIA Jt Summits Transl Sci Proc 2017: 48–57.
Hripcsak, G., N. Shang, P. L. Peissig, L. V. Rasmussen, C. Liu, B. Benoit, R. J. Carroll, et al. 2019. “Facilitating phenotype transfer using a common data model.” J Biomed Inform, July, 103253.
Swerdel, J. N., G. Hripcsak, and P. B. Ryan. 2019. “PheValuator: Development and Evaluation of a Phenotype Algorithm Evaluator.” J Biomed Inform, July, 103258.